
ML Case-study Interview Question: LLM-Powered Text-to-SQL: Semantic Retrieval & Self-Correction for Enterprise Data Querying


Browse all the ML Case-Studies here.
Case-Study question
A large organization needs to reduce the time spent by data experts on writing queries and guiding teams to the right tables. They want an internal text-to-SQL system that understands employees’ natural language questions, identifies relevant datasets, writes valid SQL queries, corrects errors automatically, and learns from interactions. Employees span multiple departments and have access to different datasets based on their permissions. Develop a plan for implementing this tool. Address how to find the right tables in a massive data warehouse, handle incomplete table metadata, personalize table selection for users, ensure query accuracy, fix errors, design a user-friendly chatbot interface, and benchmark the system’s performance. Propose the key architecture, including the knowledge sources, the vector-based retrieval strategy, the ranking process, the iterative query writing and self-correction mechanism, and the final user interface. Also suggest how teams can maintain the system long-term, adapt to evolving data sources, and measure success.
In-Depth Solution
Overview of the Challenges
Teams lose significant time answering repetitive data questions. A text-to-SQL system can automate this process but must handle a large data warehouse, incomplete table descriptions, various user contexts, and the need for accurate, optimized queries. The system must also handle table-level permissions, guide the user through any iterative steps, and offer an interactive interface.
Data Discovery and Metadata
The data warehouse contains many tables. Users cannot memorize all schema details. Many tables lack comprehensive descriptions. A robust system starts by curating reliable metadata from domain experts and existing documentation. Additional AI-generated annotations fill gaps in table or field definitions. Certified datasets receive priority to ensure queries rely on trusted sources. Deprecated tables are marked to prevent usage.
Personalized Retrieval Strategy
Semantic retrieval of tables uses embedding-based search. When a user asks a question, embeddings are generated for the question. We retrieve relevant tables by comparing embeddings. Table popularity and user access frequency narrow down the search space. We also infer the user’s department or product area to focus the query on relevant datasets.
Sometimes a user’s question is ambiguous. One user might want click-through rates in one domain, while another wants different domain data. The system infers the most probable dataset using user profiles and historical usage. Independent Component Analysis (ICA) helps cluster tables with patterns of co-usage across different business units.
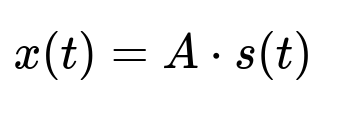
x(t) is the observed mixed data of dimension N. s(t) is the underlying source signal of dimension M. A is an N x M mixing matrix. ICA estimates a demixing matrix W that separates x(t) back into its independent components, revealing usage clusters for personalization.
Knowledge Graph and Query Generation
A knowledge graph links user nodes, table nodes, field nodes, and usage patterns. This knowledge graph stores table schemas, field attributes, example queries, domain tags, and user feedback.
The query generation pipeline begins with a short list of candidate tables from the retrieval step. A large language model (LLM) re-ranks these tables by analyzing descriptions, user context, and the knowledge graph. Next, the system picks fields and writes the query with an iterative plan. It stores partial outputs in memory, generating each step logically and minimizing complexity for simpler questions.
The query undergoes validators that run an EXPLAIN check, confirm table or field existence, and detect syntax issues. Error feedback is sent to a self-correction agent. If new tables or fields are needed, the agent repeats the retrieval process until the query passes validation.
Chatbot Interface
The assistant appears within the existing data analytics platform to avoid context-switching. Users can ask for table suggestions, request partial queries, or fix failing queries. The tool is conversational and supports follow-up prompts. Quick-reply options like “update query” or “show field details” let users refine outputs. A guided mode walks the user through table selection and query building step by step. Rich UI elements show table certifications, popular joins, partition keys, and links to the data discovery tool.
Customization
Power users can define default datasets or add custom domain instructions. They can tag their verified queries in a notebook so the system learns from good examples. They can also exclude tables that cause confusion or are no longer used. This fine-tuning requires minimal involvement from the platform team.
Performance Benchmarking
A text-to-SQL benchmark set is vital to refine the pipeline. It contains representative questions from multiple domains, with accepted ground-truth queries. The system is measured on table recall, field recall, query correctness, and response latency. Human reviewers expand the ground-truth set if multiple queries are correct. We also use LLM-based scoring for a quick approximate evaluation. Frequent re-checks highlight improvements or regressions in table usage and query accuracy.
Long-Term Maintenance
New tables must be ingested into the system’s vector store. Deprecated tables must be removed promptly. Updated domain knowledge goes into the knowledge graph. Periodic user feedback refines the pipeline. Tracking metrics like query success rate, user satisfaction, and time saved justifies ongoing investment. Error logs guide further improvement in the re-rankers, validators, and self-correction agent.
Example Implementation Sketch
A small code snippet for an iterative query writing agent:
# Pseudocode: iterative query generator
user_question = "Calculate daily CTR on email notifications"
tables_context = retrieve_tables(user_question)
tables_selected = llm_table_reranker(tables_context)
query_plan = generate_plan(user_question, tables_selected)
for step in query_plan:
partial_query = llm_write_partial_query(step)
partial_query_validated = validate_partial(partial_query)
if not partial_query_validated:
partial_query = self_correct_agent(partial_query, step)
# Final assembled query
final_query = assemble_query(query_plan)
explain_output = execute_explain(final_query)
if explain_output.error:
final_query = self_correct_agent(final_query, explain_output.error)
This demonstrates the iterative flow with retrieval, LLM-driven ranking, plan-based query writing, and validation plus correction.
How would you handle ambiguous questions?
A question like “What was the conversion rate?” can refer to different funnels. Classify the question into the correct domain by analyzing the user’s organizational unit and common tables. Present the user with disambiguation options if needed. If the user is from marketing, default to relevant marketing tables. If from ads, default to ads conversion tables. Provide a short descriptive note about each table to help the user choose.
How do you ensure minimal hallucinations in table selection?
Use well-curated metadata, frequent vector store updates, and domain knowledge from the knowledge graph. Re-rank tables with an LLM that sees real table descriptions, usage patterns, and validated example queries. Confirm existence of each recommended table. If the system sees a non-existent table name, it triggers a correction loop.
How do you handle user access and permissions?
Each table enforces read access rules for certain user groups. When a user is denied access, the system auto-requests group-based credentials if the user is authorized to use that group. This spares the user from manual role-switching. If the user truly lacks permission, the system gracefully notifies them to request access or select an alternative dataset.
What if the user only wants table names or reference queries?
Detect the user’s intent. If they just want table recommendations, show relevant table descriptions and common joins. For reference queries, fetch short code samples from verified notebooks. If the user wants general syntax tips, return a short snippet with explanations. Avoid returning a full query if the intent is purely informational.
How would you test the correctness of the generated queries?
Construct a benchmark with real user questions plus correct queries approved by domain experts. Compare table-level recall, field-level recall, and measure syntax correctness. Use an LLM-based judge to score accuracy on detailed aspects: correct filters, accurate joins, and appropriate aggregation. Re-check borderline results with a human review. For partial acceptance, add new correct answers to the benchmark to keep it up-to-date.
How do you adapt to changing data sources or new tables?
Schedule periodic ingestions of newly popular tables. Remove deprecated ones. Use metadata from the data discovery tool to auto-flag tables as obsolete when they lose certification or show no usage for a set period. Encourage domain experts to keep table descriptions and field definitions current. The knowledge graph’s edges and attributes must be updated to reflect new usage patterns.
Which metrics would you track to measure success?
Track user satisfaction, usage frequency, query success rate, time from question to correct query, and proportion of queries requiring manual expert intervention. Monitor false accept rates (bad queries that appear correct) and false reject rates (good queries corrected unnecessarily). Keep an eye on coverage across various departments.
Could this system generalize to other business intelligence tasks?
Yes. The pipeline of retrieving relevant metadata, re-ranking with an LLM, generating partial queries or code, validating, and self-correcting applies to tasks like building data pipelines or analytics reports. A different set of knowledge sources might be required, but the same iterative approach and user feedback loop can be extended to a wide range of data tasks.