
ML Case-study Interview Question: Automated Enterprise Document Summarization Using Transformer-Based Knowledge Distillation


Browse all the ML Case-Studies here.
Case-Study question
A global organization wants an automated system that suggests short (1-2 sentence) summaries for user-generated documents within a large enterprise platform. The summaries should capture the main ideas of a document, but the writer can edit or ignore them. The documents vary greatly in length and topic. Propose a machine learning solution to handle this broad range of documents, ensuring the system remains efficient and scalable in production. Outline how you would train the summarization model, manage the training data, optimize latency, and handle edge cases (extremely long or irrelevant documents). Provide details about the technical architecture, model training process, and deployment strategy.
Detailed solution
Model Training and Data Preparation
Collect a dataset of documents paired with human-written summaries. Filter out noisy and inconsistent samples, focusing on a smaller, high-quality set that reflects typical business documents. Pre-train a transformer-based encoder-decoder using a large corpus of unlabeled text for self-supervision. Fine-tune on the filtered, high-quality dataset so the model learns to map raw document text into concise, coherent summaries.
Architecture
Use a transformer encoder to encode long text segments. Apply sequence-to-sequence learning to generate summaries. A self-attention mechanism in the transformer encoder captures context across words and phrases. To generate summaries token by token, an autoregressive decoder is often used, but pure transformer decoding can be slow at inference time for long summaries.
Knowledge Distillation for Efficiency
Train a large teacher model first, then distill its knowledge into a smaller student model that maintains comparable quality but is faster. The teacher is the transformer encoder-decoder. The student can mix a transformer encoder with a more efficient RNN decoder to reduce latency. Use a standard technique for knowledge distillation, minimizing the Kullback-Leibler divergence between teacher and student probability distributions.
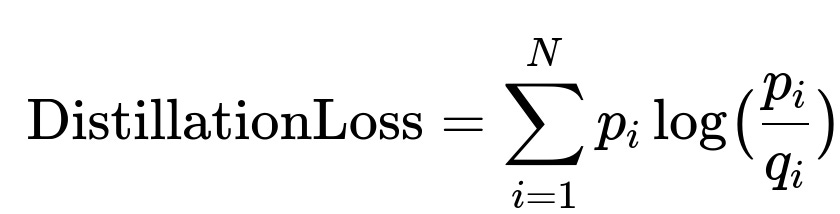
Here, p_i is the teacher model’s predicted probability for token i, q_i is the student model’s predicted probability for token i, and N is the length of the summary sequence. This objective encourages the student to match the teacher’s output distribution.
Serving and Infrastructure
Deploy on specialized hardware that handles large matrix multiplications efficiently. Use Tensor Processing Units (TPUs) or Graphics Processing Units (GPUs) to serve the final model. This setup reduces response time when generating summaries for user requests, even for longer documents. Present the model’s suggested summary to the document writer, who can accept, revise, or ignore it.
Handling Long and Irrelevant Documents
Select documents suitable for summarization by checking the model’s confidence score. When the model is uncertain (e.g., extremely long or irrelevant documents), skip suggestion. Improve coverage of longer documents by systematically subdividing them and consolidating sub-summaries if more robust coverage is needed. Continue user-based evaluation to refine these decisions.
How would you handle very large variability in document style and length?
Early steps filter the training set to ensure uniformity in summary style. At inference, dynamically adapt the input length by truncation or chunking. When a document is much longer than the limit, chunk it into smaller parts. Summaries from each chunk can be combined or used to guide a final summary pass.
How do you ensure that the generated summaries remain factual and grammatically correct?
Include quality-check layers. Pre-train on well-structured data so the model learns strong grammar foundations. Fine-tune on high-fidelity summaries with minimal factual errors. Evaluate with human reviewers on a small but representative sample. Track real-world feedback signals (user edits, acceptance rates) and retrain iteratively.
How do you measure the success of the system?
Collect direct user feedback and measure acceptance vs. rejection or level of edits. Compare suggested summaries to final user-edited summaries. Use reference-based metrics (e.g., ROUGE) on holdout sets, but place more weight on real usage statistics since multiple correct summaries are possible.
Why did you choose an approach that combines a transformer encoder with an RNN decoder instead of a full transformer?
A full transformer is simpler to train but can be slower in production for long outputs. An RNN decoder omits self-attention over previously generated tokens, reducing computational overhead. Knowledge distillation ensures comparable quality to the full-transformer baseline.
How do you handle domain-specific jargon or specialized vocabulary?
Maintain a large vocabulary from the pre-training corpus. For especially niche content, collect domain-specific documents and include them in fine-tuning. Use subword tokenization so new terms are split into recognizable chunks. Retrain or fine-tune the vocabulary and model if new jargon appears frequently.
What if the model occasionally outputs irrelevant or misleading content?
Add gating logic that checks the relevance of the summary against the input. If the summary is too dissimilar, the system can refrain from suggesting it. Log and examine these mismatches, then feed them back into training as negative examples to further refine model alignment.