
ML Case-study Interview Question: On-Device Handwriting Recognition for Mobile Crosswords Using Deep CNNs.


Browse all the ML Case-Studies here.
Case-Study question
You are tasked with designing a handwriting recognition system for a popular crossword puzzle app on mobile devices. The app has special squares that must capture letters traced by stylus or finger. Users may lift the stylus mid-letter, leading to partial strokes and noisy input. You must propose how to build an end-to-end machine learning pipeline for accurate letter recognition and seamless user experience. How would you approach data collection, data preprocessing, model design, parameter tuning, and on-device deployment?
Full Detailed Solution
Overview
The system must capture user strokes from a custom input area, then convert the resulting raw images into recognized letters. This requires a robust pipeline that handles noisy sketches, offset letters, and multiple handwriting styles. The core approach involves a Deep Convolutional Neural Network, data augmentation, and on-device inference.
Capturing Input
Each square in the puzzle app becomes a mini-canvas that records user strokes in real time. A mechanism waits for a short idle interval (e.g., 500 to 1000 ms) before assuming the letter input is complete. The captured image is then passed to the recognition pipeline.
Data Preprocessing
The system downscales and binarizes each square’s image. By converting 128x128 raw images to 28x28, the model sees a simplified, noise-reduced representation. For robust recognition, data augmentation randomly skews, shifts, and rotates training samples so the model learns to handle off-center letters.
Model Architecture
A Deep CNN is effective for image classification tasks. It extracts local features via convolutional filters, pools them to retain the most significant shapes, and applies nonlinear activations for better discrimination. After several convolution and pooling layers, the network flattens features and passes them through dense layers that output character probabilities.
You can optimize the training with the standard multi-class cross-entropy cost function:
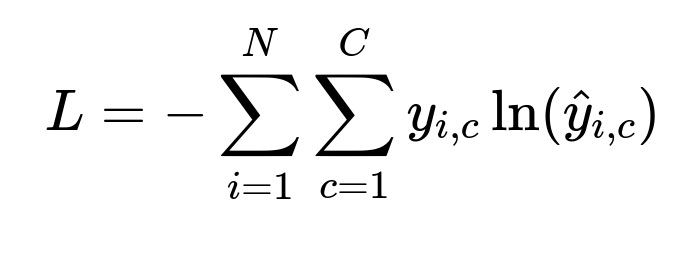
Here, N is the number of samples, C is the number of classes (letters, digits), y_{i,c} is the true label for sample i and class c, and \hat{y}_{i,c} is the predicted probability.
Parameter Tuning
Hyperparameter optimization uses techniques like randomized searches across different layer depths, filter sizes, and dropout rates. Stratified K-Fold cross-validation further checks model robustness by cycling through diverse subsets of augmented data. If overfitting arises, dropout and data augmentation help generalize better.
Model Implementation
Below is a simplified Python snippet showing the CNN construction in a framework like TensorFlow:
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=32, kernel_size=(3,3), activation='relu', input_shape=(28,28,1)),
tf.keras.layers.MaxPooling2D(pool_size=(2,2)),
tf.keras.layers.Conv2D(filters=64, kernel_size=(3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=(2,2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(62, activation='softmax') # 62 for 26 uppercase + 26 lowercase + 10 digits
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Data augmentation example
data_generator = tf.keras.preprocessing.image.ImageDataGenerator(
rotation_range=15,
width_shift_range=0.1,
height_shift_range=0.1,
zoom_range=0.1
)
# Fit model on augmented data
train_flow = data_generator.flow(x_train, y_train, batch_size=64)
model.fit(train_flow, validation_data=(x_val, y_val), epochs=20)
This code trains a CNN for multi-class handwriting recognition with data augmentation.
On-Device Deployment
After achieving acceptable accuracy, the model is converted to a mobile-friendly format (e.g., TensorFlow Lite). The final .tflite file is integrated into the puzzle app. The app listens for stroke completion, then runs inference locally on the device. This yields low-latency predictions even without network access.
Follow-up question 1
How would you handle users whose handwriting styles deviate significantly from the training data?
Answer
Include user-driven updates. After initial deployment, gather misclassified samples (with user permission) to expand your training set and retrain or fine-tune the model. This can use a feedback loop where misrecognized letters are labeled by the user, thus enriching coverage for diverse handwriting. Online or incremental learning can retrain a small portion of network parameters locally, or you can schedule periodic server-side model updates with new user samples.
Follow-up question 2
How would you address partial letters or premature predictions due to quick stylus lifts?
Answer
Incorporate timing-based heuristics and thresholds. If the stylus lifts briefly, wait a bit longer before triggering classification. Model or rule-based stroke analysis can also combine multiple strokes into a single letter if the input occurs within a short time window. An alternative is a small recurrent or convolutional module to process sequences of strokes and classify them collectively.
Follow-up question 3
What if the model size is too large for certain devices?
Answer
Use compression and quantization. Post-training quantization reduces model parameters from float32 to int8. Pruning removes redundant weights to make the network smaller. Knowledge distillation trains a smaller “student” model to mimic the outputs of a larger “teacher” model. These methods preserve most performance while significantly shrinking the footprint.
Follow-up question 4
How would you ensure real-time performance with limited hardware?
Answer
Profile the CNN on typical device hardware. If inference is too slow, reduce the network depth or number of convolutional filters. Use smaller kernel sizes and apply model optimizations (e.g., fused batch normalization). Test with GPU acceleration on devices that support it. Consider early-exit networks, which allow inference to stop at shallower layers if confident enough.
Follow-up question 5
How could you expand the feature set beyond simple handwriting recognition?
Answer
Add features like scribble-based erasing or shape detection. The same model pipeline could detect erasure gestures or interpret stylus pressure to differentiate valid strokes from accidental marks. You might also integrate personalization, letting users store their unique handwriting style for more accurate predictions over time.
These approaches, when combined, form a robust system for on-device handwriting recognition in a puzzle app.