
ML Case-study Interview Question: Building Scalable Lookalike Audiences with No-Code ML for E-commerce


Browse all the ML Case-Studies here.
Case-Study question
You are given a large-scale e-commerce platform that wants to optimize marketing efforts by identifying new audiences with high conversion potential. They have an internal no-code platform for creating Machine Learning models. Their marketing team has limited coding skills but wants a scalable, self-service approach to build and deploy lookalike models. They also plan to run experiments comparing traditional audience selection with the new lookalike-based audiences.
They want you to design a complete ML strategy for:
Selecting and labeling seed users.
Creating and selecting relevant features from a large pool.
Training models to rank users by conversion potential.
Backtesting to validate performance before deployment.
Automating the pipeline so non-technical stakeholders can handle everything.
Propose how you would approach this project. Include how you would handle data ingestion, feature engineering, no-code ML platforms, user onboarding, and ongoing validation. Illustrate any potential obstacles and how you would solve them. Also show how you measure success through final campaign metrics like conversion uplift or cost per acquisition.
Detailed Solution
Overall Approach
Start by defining the seed group, which is a set of users who have demonstrated the target behavior (for example, purchasing a specific product or subscribing to a specific service) and those who did not. This contrasting group helps the model learn discriminating patterns. Prepare your features by merging data from multiple sources (e.g., transaction logs, user behavior datasets). Use a no-code platform to reduce dependency on advanced programming skills. Automate the solution so the marketing team can handle scoring and creating new lookalike audiences without heavy technical intervention.
Seed Group Definition
Specify clear criteria for positive labels. Example: “Has purchased Product X within the last 30 days.” For negatives, pick users who had the chance to purchase but did not. Ensure both groups match your target audience scope (e.g., same region, similar marketing exposure). Align seed group size with the complexity of your feature set.
Feature Engineering
Leverage a “feature store” concept or a centralized library. For example, gather:
User demographics (age, location).
Historic purchase patterns (frequency, recency).
Engagement data (email opens, push-clicks).
Cross-product interactions (fintech usage, main platform usage).
Apply domain knowledge to filter out irrelevant or potentially biased features. In no-code platforms, load feature sets by clicking on data sources. Let the tool handle merging, cleansing, outlier removal, and date-window filtering. If possible, rely on “Books” or “Feature Blocks” that bundle relevant signals (Commerce, Fintech, Cross-behavior).
Model Selection
Try classification methods like Random Forest, LightGBM, or XGBoost. Use a “Champion-Challenge” setup, training multiple models on the same dataset. Evaluate them using standard metrics: AUC, recall, precision. Verify your top model’s confusion matrix to avoid skew or overfitting. In a no-code environment, this often involves choosing from a menu of algorithms and letting the platform tune hyperparameters automatically.
Information Value (IV) and Feature Selection
Use IV to drop features that add minimal predictive power or lead to overfitting. One common formula is:
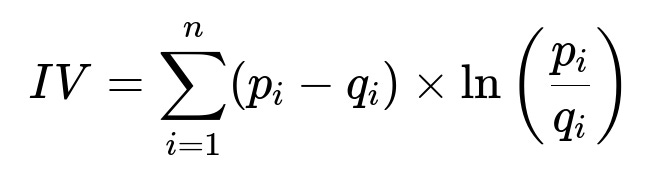
Here p_i is the proportion of “positives” in bin i, and q_i is the proportion of “negatives” in bin i. Keep features with IV above a threshold (e.g., 0.1). Remove features that cause perfect separation in the training set.
Backtesting
Pull historical campaigns where you can see who actually converted. Score those users with your new model. Sort them by predicted score. Compare real conversions across deciles of your predicted ranking. Ensure top deciles have the highest conversion. Calibrate your cutoffs for final segmentation. If conversion rates in top deciles are significantly higher, you have evidence the model is ranking correctly.
Scaling and Deployment
Expose the model through a robust pipeline. In a no-code platform, it might be a scheduled job that:
Reads daily or weekly updated features.
Scores all eligible users.
Writes predictions and deciles to a table for immediate usage.
Non-technical staff can log in, select the time window, trigger training, run scoring, or schedule recurring runs. Document the process (screenshots, short how-to videos).
User Onboarding
Provide a “quick-start guide” that shows:
How to prepare the seed group table (1/0 labels).
How to select relevant features from the pre-built library.
Which metrics to monitor (AUC, decile analysis).
How to interpret final decile outputs for marketing segmentation.
Offer personal support (office hours or short calls) to verify correct usage of the pipeline. Gather their feedback about user experience to refine documentation and feature sets.
Measuring Success
Review marketing outcomes with an A/B test. Compare your new lookalike-based audience (treatment) with the traditional audience selection (control). Focus on:
Conversion rates in each decile.
Uplift in the top deciles.
Cost per acquisition improvements.
Return on investment from higher-precision targeting.
Continue iterating if results are below expectations. Revisit labeling strategy or feature selection. Adjust decile thresholds if your top deciles are too narrow or too broad.
Possible Follow-up Questions
1) How would you structure a Python script for training an XGBoost model if you needed more custom control outside the no-code tool?
A simple approach:
import pandas as pd
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
df = pd.read_csv("training_data.csv")
X = df.drop("label", axis=1)
y = df["label"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = xgb.XGBClassifier(
max_depth=6,
learning_rate=0.1,
n_estimators=100,
use_label_encoder=False,
eval_metric="logloss"
)
model.fit(X_train, y_train)
pred_probs = model.predict_proba(X_test)[:,1]
auc_score = roc_auc_score(y_test, pred_probs)
print("AUC:", auc_score)
Split data, initialize the classifier, train, and evaluate AUC. Tune hyperparameters through grid search or Bayesian search. If you want to replicate the no-code tool’s approach, ensure consistent feature engineering steps and data cleaning.
2) How do you ensure you are not spamming users in the top deciles with irrelevant offers?
Create multiple business rules. For example:
Limit contact frequency within a specific time window.
Combine model outputs with business filters (e.g., “exclude if user unsubscribed from previous campaigns”).
Track user engagement signals. If open rates or conversions drop, reduce contact frequency.
Proper gating is essential so you do not exhaust your audience or trigger opt-outs.
3) How do you confirm the stability of your model over time?
Periodically retrain and compare performance metrics against previous runs. Use backtesting for each new iteration. Track drift in features or changes in user behavior. If performance drops, investigate possible distribution shifts (e.g., new products, seasonal changes).
4) Why is a decile-based approach recommended for marketing decisions?
Marketing teams benefit from discrete buckets for simpler decision-making. Each decile can correspond to a different campaign intensity or offer. Top deciles get premium engagement, while lower deciles may get fewer contacts or different messaging. This ensures controlled experimentation and better ROI monitoring.
5) How do you handle resource constraints if scoring every single user is expensive?
Use incremental scoring or partial scoring. Score only users who match broad segments of interest. Consider sampling approaches or use approximate methods for large volumes. Profile usage frequency to decide how often you refresh scores. Balance computational cost against marketing benefits.
6) What if your seed group is biased or too small?
Combine multiple seed sources (e.g., conversions from multiple geographies or time windows) to increase diversity. If you have a tiny seed group, explore transfer learning from a similar domain. Validate model generalization with cross-region or cross-product tests.
7) What if the champion model starts underperforming?
Quickly retrain or roll back to a previous version. Investigate external factors (product changes, marketing shifts, competitor actions). Adjust the feature window or add new signals that capture current user behavior. Maintain robust monitoring dashboards (e.g., daily AUC tracking) for early detection.
8) How do you evaluate no-code tools against custom solutions for a large-scale environment?
Check if no-code solutions handle the volume and velocity of your data. Evaluate integration with internal systems (data lake, streaming events). Compare speed of model training and scoring. Ensure the platform supports advanced metrics and can integrate with specialized libraries if needed. If there are limitations, complement no-code with custom scripts for specialized tasks.
9) How do you keep other teams informed about the new lookalike approach?
Expose a shared dashboard for real-time metrics. Provide a short standard operating procedure for campaign managers. Include guidelines on which deciles to target for each type of campaign. Offer occasional training sessions to ensure internal adoption.
10) How can you handle user privacy while collecting so much data?
Anonymize sensitive attributes, such as names or IDs, after linking them to your feature store. Follow compliance rules (GDPR or similar) for data collection and usage. Provide opt-out choices for users. Maintain auditable pipelines that document how data flows and which features are used in each scoring process.