
ML Case-study Interview Question: Personalized Meal Combo Recommendations via Embeddings and Approximate Nearest Neighbors.


Browse all the ML Case-Studies here.
Case-Study question
You are a Senior Data Scientist at a large platform that delivers meals to users. Many customers browse menus for a long time and abandon their carts. They have too many options and cannot decide what to order. Management wants to launch a recommendation feature that shows each user a short list of two-item combos personalized to their tastes and location. They want you to devise a detailed solution that handles scale, subjectivity of food preferences, item availability, and micro-personalization, while ensuring fresh and relevant combos. How would you design, build, and deploy this system?
Proposed Solution
Personalized cart recommendations focus on helping users quickly find relevant combos. A practical approach is to reduce the space to two-item combos, build a retrieval mechanism to fetch candidate carts, and then apply a ranking process. This architecture addresses complexity by balancing personal preferences with menu availability and offering only a short list. Below are the key steps.
Generating Valid Carts
Start by examining historic orders from the entire platform. Construct all two-item carts that appeared in actual orders. Remove incoherent pairs by relying on a classification taxonomy for each item. This taxonomy groups dishes by family and category. Evaluate co-order frequency, item popularity, and ratings to discard pairs that rarely appear or have low feedback. This filters nonsense combos like a curry paired with a small snack users only order when they have rice at home. Maintain only pairs that make sense as a standalone meal.
Micro-Personalization
Compute a user’s item-level taste profile from past orders. Estimate dietary preferences through a vegness score that measures how vegetarian or non-vegetarian a user tends to be at a certain mealslot and location. Exclude combos that conflict with the user’s inferred dietary habits. If a user shows consistent vegetarian behavior, never surface combos that include non-vegetarian items.
Embedding Computation
Represent each item in a continuous embedding space. To form a cart embedding, treat it as a weighted combination of item embeddings, where each item’s price acts as a weight. This is a core formula because it encodes the main dish more strongly than the side dish.
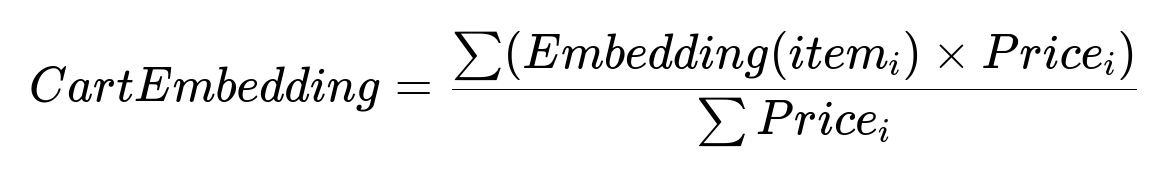
The variable Embedding(item_i) is the continuous vector representation of item_i in some d-dimensional space. Price_i is the menu price. The sum runs over all items in the combo. A main dish with a higher price gets a higher contribution in the combined vector. This allows capturing combo similarity in a meaningful way.
Candidate Retrieval
Retrieve combos for each user from multiple sources:
(1) Combos from overall platform orders filtered by the taxonomy-based rules. (2) Combos created from items the user has ordered before, extended with cross-sell pairs from those same restaurants.
Build an approximate nearest neighbor (ANN) index for each geographic area. Query the index using the user embedding (aggregated from the user’s past item embeddings) to fetch top-k combos. Combine these combos with user-specific combos from cross-sell predictions and any local popularity combos to form the final candidate set.
Ranking
Create a simple scoring method to sort the retrieved combos. Include similarity to user embeddings, difference from the user’s median spend, difference from user’s vegness score, and distance between the user and the restaurant. Use manual weights to combine these factors into a final ranking score. Return the highest scoring combos as the user’s recommendation list.
Production Orchestration
Offline pipelines produce these recommendations at regular intervals. One pipeline generates the taxonomy-based rules, user embeddings, and the user’s dietary preferences. Another pipeline runs more frequently to rebuild the ANN indexes from recent orders, retrieve relevant combos for each user, rank them, and push results to a fast-access data store. During each user session, the system fetches these combos with minimal latency. Over time, iterate to move some retrieval and ranking steps online if you need deeper freshness or want to reduce storage overhead.
Example Python Snippet for ANN Index
Below is a short demonstration of how to build an ANN index using Python. This example uses a library similar to Spotify’s Annoy. Explanations follow after the code.
from annoy import AnnoyIndex
import numpy as np
dimension = 64 # Example embedding dimension
annoy_index = AnnoyIndex(dimension, metric='euclidean')
# Suppose cart_embeddings is a list of (cart_id, embedding_vector)
for i, (cart_id, emb) in enumerate(cart_embeddings):
annoy_index.add_item(i, emb)
annoy_index.build(10) # Build the index with 10 trees
# Retrieving combos for a user embedding
user_embedding = np.random.rand(dimension).tolist()
neighbors = annoy_index.get_nns_by_vector(user_embedding, 10) # Get top 10 combos
In this snippet, each two-item cart has a 64-dimensional embedding. The index is built once, then used to retrieve the nearest neighbors for a user embedding. Map the retrieved neighbor indices back to actual cart_ids for further ranking.
How would you handle item unavailability?
This requires real-time checks on restaurant inventory. Do not show combos with items out of stock. At daily or real-time refresh, remove combos with unavailable items. Adding multiple combos for the same user helps guard against last-minute unavailability issues.
What if users dislike certain dish families?
Use item-level embeddings and user-level signals. If a user rarely or never orders a particular dish family, discount combos that contain it. Track negative feedback from clickstream data. For each user, log combos that were shown but not clicked. Incorporate this data into user embeddings over time, reducing the embedding similarity for disliked food categories.
How to ensure combos stay fresh?
Update candidate combos and user embeddings on a regular schedule. Include new combos discovered in recent orders, incorporate seasonal items, and consider trending items regionally. If you see an uptick in cold drinks during summer, those combos become more prominent. Keep the pipeline flexible so that user embeddings and combos refresh automatically.
Could real-time scoring improve accuracy?
A real-time scoring approach would fetch combos from an ANN index at query time, then run a supervised ranking model. This might evaluate session context, immediate user actions, or ephemeral signals. This method reduces offline storage needs and adapts faster to changing data. It also increases infrastructure complexity. You would balance latency, scalability, and cost to decide on a real-time versus scheduled approach.
How to handle ranking with limited labeled data?
Start with a heuristic approach using relevant signals (distance, price range, dietary preference). Log user clicks, impressions, conversions on the shown combos. Over time, gather enough data to train a supervised model. That model can learn the best weightings for these signals. Deploy it in the ranking pipeline and continuously monitor performance.
How would you address user feedback in real time?
Incorporate multi-armed bandit techniques that track immediate user interactions. Each time a user picks a combo, update the reward function and push it into a streaming system. Weigh recent feedback more heavily to quickly adapt to shifts in user preferences, including short-term cravings or special events.
How to ensure reliability in production?
Build modular workflows. One weekly pipeline generates the static pieces: item taxonomy rules, user embeddings, co-order patterns, and so on. Another daily or more frequent pipeline constructs ANN indexes, fetches combos, ranks them, and writes them to a fast lookup database. These processes should have robust logging, monitoring, and error-handling. Track success metrics like conversion, time spent, or reorder rates. Quickly roll back changes if a workflow fails or if performance metrics drop.