
ML Case-study Interview Question: LLM-Powered File Summarization and Q&A Using Embeddings and Clustering


Browse all the ML Case-Studies here.
Case-Study question
You have a large-scale file-hosting platform used by millions of users. You want to introduce a new feature: a web-based preview page that can summarize the contents of a file or answer user questions about it, using Large Language Models (LLMs). You need to handle diverse file types (documents, videos, etc.), chunk them as text, generate embeddings, cluster or compare these chunks, and feed the most relevant ones into an LLM to produce summaries or answers. You also want the option to handle multiple files at once. Propose your system architecture to achieve this. Explain how you will:
Extract text from various file types in real time.
Convert text into embeddings and cache them.
Generate summaries by covering all main ideas in a file.
Generate relevant answers to user questions.
Scale up to handle multi-file queries in one shot.
Ensure you manage latency, cost, and potential hallucinations.
Suggest a step-by-step design that addresses each requirement end-to-end. Share your ideas on data flow, caching strategy, chunk selection, how to incorporate user feedback, and how to keep it secure.
Proposed Detailed Solution
System Overview A pipeline orchestrates each stage of processing. It takes a file (or multiple files), extracts or transcribes any text, generates embeddings, and then routes these embeddings to LLM-based plugins for summarization or question-answering. Splitting the pipeline into separate transformations allows you to reuse cached data and avoid repeated computation.
Text Extraction Develop a transformation layer capable of converting any file into raw text. For documents (PDF, DOCX), parse text directly. For videos or audio, generate a transcript via speech-to-text. Cache all intermediate outputs.
Embedding Generation Transform text chunks into vector embeddings using a pretrained LLM or an embedding model. Chunking the text is crucial for large files. A typical approach is to split a file’s content into paragraph-like segments. Store and cache these embeddings so follow-up queries reuse them without extra computation.
Summarization Use embeddings to find dissimilar chunks that collectively cover the file’s topics. One approach is to cluster the chunk embeddings with k-means. Each cluster represents a distinct topic. Concatenate representative chunks of each cluster into a single context. Generate the final summary by calling the LLM once with that context. This approach minimizes hallucinations because it only needs one final LLM call.
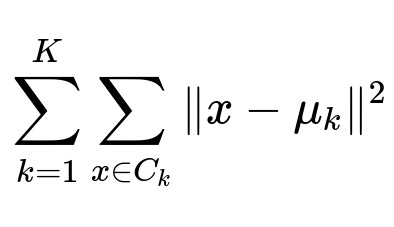
Here:
x is a chunk embedding.
mu_{k} is the centroid of cluster k.
C_{k} is the set of chunk embeddings in cluster k.
The goal is to minimize the sum of squared distances of each chunk to its assigned centroid.
Question-Answering Take the user’s query, convert it into an embedding, then compute the distance between this query embedding and each chunk embedding.
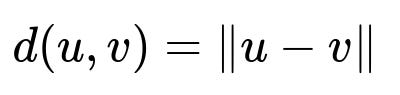
Here:
u is the query embedding.
v is the chunk embedding.
d is the distance function in embedding space.
Select the most similar chunks using a distance or similarity threshold. Concatenate those chunks and append the user query. Supply them to the LLM to produce an answer. Provide references to chunk positions as sources so users can verify the answer.
Multi-file Handling Gather embeddings from multiple files. For each query, compute relevance scores between the query embedding and all chunk embeddings from the chosen files. Rank them. Use power law dynamics to decide how many high-scoring chunks to keep. This ensures broad questions receive more context chunks and direct questions get fewer but very relevant chunks.
Caching Strategy Cache all embeddings and intermediate text data. Trigger the pipeline only when a file is accessed for a new query. This ensures minimal latency. Reuse the same cache for both summarization and question-answering.
Cost and Latency Considerations Perform chunking and embedding once per file, then reuse. Summaries or answers only require a single LLM call, using carefully selected chunks. This design offers a big gain in speed and lowers your hosting costs.
Security and User Privacy Extract or embed only those files the user explicitly requests. Send only a small subset of file text (chunks) to the LLM, not entire files. This secures private content and maintains compliance. Let users easily opt out.
Example Python Snippet
import numpy as np
from transformers import AutoTokenizer, AutoModel
import torch
tokenizer = AutoTokenizer.from_pretrained("some-embedding-model")
model = AutoModel.from_pretrained("some-embedding-model")
def get_embeddings(chunks):
embeddings = []
for text_chunk in chunks:
inputs = tokenizer(text_chunk, return_tensors='pt')
with torch.no_grad():
outputs = model(**inputs)
# Suppose 'outputs' has a final hidden state we pool
pooled = torch.mean(outputs.last_hidden_state, dim=1)
embeddings.append(pooled.squeeze().cpu().numpy())
return np.array(embeddings)
# Summaries or Q&A steps can then be built on these embeddings...
The code shows a basic approach to embedding text chunks. Summaries and answers come after, by grouping or ranking these embeddings.
What are some potential pitfalls with LLM outputs, and how do you handle them?
Hallucinations LLMs sometimes produce confident but incorrect text. Mitigate by sending only relevant chunks to the model as context. Provide chunk references in the final output. Let users see where the answer came from. You can also fine-tune or prompt-tune the LLM to be more cautious.
Privacy Leaks Limit how much text you send to the LLM and confirm it is from files the user has permission to read. Possibly mask or redact sensitive data. Let users opt out.
Over-Long Inputs Even relevant chunks can exceed model token limits. Deploy chunk ranking or power law logic to cut off the least relevant chunks. Summaries drastically reduce text length.
How would you optimize for cost and speed with so many LLM queries?
Each LLM call can be expensive. Generate embeddings once, and cache them. When summarizing or answering questions, pass only the relevant subset of chunks into the LLM for one final inference. Reducing repeated calls lowers cost. Summaries also reduce the data you feed into the model. Real-time chunk selection only processes text you actually need.
How do you ensure these methods scale as user traffic grows?
Use a distributed architecture for text extraction, embedding, and clustering. Shard your data across multiple workers or microservices. Incorporate asynchronous job queues for file transformations. Build a robust caching layer at every stage (text extraction, embeddings, LLM responses). Include metrics for throughput and latency, and scale your container or server fleet automatically.
Can you describe your approach for measuring the quality of summaries or Q&A answers?
Evaluating Summaries Compare the model’s summary with a human-generated summary. Track coverage of key topics. Look for false statements. Maintain an internal metric for how many distinct concepts are captured. You can also gather user feedback.
Evaluating Q&A Check correctness and completeness. See if references to chunk positions align with what the user asked. Measure whether the system’s answer matches a known ground truth. Look at user satisfaction metrics or explicit user ratings.
If the user provides contradictory or confusing instructions, how do you handle it?
LLMs can get confused by contradictory queries. Provide clarifications. Flag ambiguous requests for user confirmation. If the question directly conflicts with content in the file, highlight that mismatch. You can also have a fallback logic that suggests the user rephrase or clarifies their intent.
Why do you cluster with k-means for summarization instead of a map-reduce summary-of-summaries?
k-means picks chunks that are semantically dissimilar. This covers more topics in one shot. It lowers the number of LLM calls, reducing the risk of multiple-step hallucinations. It also makes it easier to debug and evaluate the final summary because you see exactly which chunks were selected.
What if your system needs to run on documents with millions of words?
Chunk them in smaller batches. Generate embeddings in parallel. Store embeddings in an efficient vector index. For summarization or Q&A, retrieve only the top chunk embeddings. Possibly sample or filter early to manage huge files. Use streaming or iterative chunk retrieval if you exceed memory limits.