
ML Case-study Interview Question: Decoding Client Style Notes with BERT for Enhanced Fashion Recommendations.


Browse all the ML Case-Studies here.
Case-Study question
A major online clothing retailer handles a large volume of client style requests. Many clients leave notes specifying items they want, such as “Give me jeans, not shoes.” These notes help stylists pick suitable items. The retailer wants to automate better item recommendations by extracting nuanced context from textual requests. They have access to historical data of client requests and stylist item selections. Propose how you would design and implement a system that extracts meaningful context from these requests and uses it to recommend relevant inventory items. Include how you handle contextual language understanding, model training, and how you would integrate these features into a broader recommendation pipeline.
Detailed Solution
A robust approach relies on Bidirectional Encoder Representations from Transformers (BERT) to capture context in client notes. Static embeddings like word2vec ignore word order and fail to capture deeper relationships, while BERT learns contextual embeddings by attending to different parts of the text.
The attention mechanism weights each word’s importance relative to every other word. Each attention “head” learns a different linguistic relationship. Summing multiple heads yields powerful contextual representations. Stacking many Transformer encoder layers refines these representations.
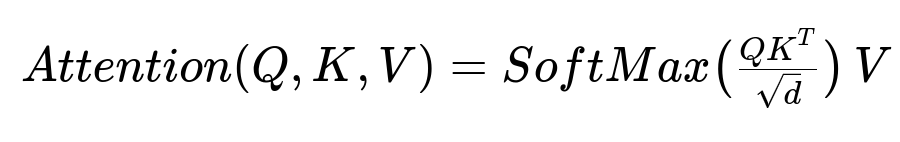
Here, Q stands for queries, K for keys, V for values, and d is the dimension of these vectors. Q, K, and V derive from the input embeddings. The SoftMax output yields attention weights that emphasize or de-emphasize words in relation to each query.
Training steps often begin with a publicly released BERT model (pretrained on large text corpora). Fine-tuning with domain-specific data is critical. The domain data in this scenario is the text from client notes describing style requests. A final classification or retrieval head can predict the probability of each item in the catalog being chosen given the client’s request embedding.
Below is an illustrative snippet of Python-like pseudocode (simplified) showing how to fine-tune the model:
import torch
from transformers import BertModel, BertTokenizer
import torch.nn as nn
import torch.optim as optim
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model_bert = BertModel.from_pretrained("bert-base-uncased")
# LSTM layer on top of BERT outputs
class BERTLSTM(nn.Module):
def __init__(self, hidden_size=500):
super(BERTLSTM, self).__init__()
self.bert = model_bert
self.lstm = nn.LSTM(input_size=768, hidden_size=hidden_size, batch_first=True)
self.classifier = nn.Linear(hidden_size, num_items) # num_items is the inventory size
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
sequence_output = outputs.last_hidden_state
lstm_output, (h, c) = self.lstm(sequence_output)
# h has shape [1, batch_size, hidden_size]
final_hidden_state = h[-1] # shape [batch_size, hidden_size]
logits = self.classifier(final_hidden_state)
return logits
# Example usage
# input_texts, labels = ... # Prepare dataset
# input_encodings = tokenizer(input_texts, return_tensors='pt', padding=True, truncation=True)
# model = BERTLSTM()
# criterion = nn.CrossEntropyLoss()
# optimizer = optim.Adam(model.parameters(), lr=1e-5)
#
# # Typical training loop (omitting details)
# for epoch in range(num_epochs):
# logits = model(input_encodings["input_ids"], input_encodings["attention_mask"])
# loss = criterion(logits, labels)
# loss.backward()
# optimizer.step()
# optimizer.zero_grad()
This model produces a vector representation of each request, then predicts the probability of each inventory item being chosen. These representations feed into the broader styling algorithm, which may include business rules on stock, user size, or other constraints. The synergy of BERT’s deep linguistic understanding with these external signals yields better ranking of relevant items.
Implementation details:
Data Cleaning: Remove noise or unrelated text segments.
Tokenization: Use the pretrained model's tokenizer to split text into tokens recognized by BERT.
Fine-Tuning: Freeze some or all of BERT’s layers initially, then gradually unfreeze for more domain adaptation. Minimizing catastrophic forgetting is often beneficial.
Integration: The final embeddings become features for the existing recommendation pipeline. The pipeline can integrate user style history, personal details, and inventory constraints.
Real-world usage reveals BERT captures context like "black dresses" or “no jeans.” If clients mention “please send me shorts but no skirts,” the model prioritizes short styles while filtering out skirts. Stylists retain final veto power, but these suggestions speed up and enrich the process.
What if the request text is short or ambiguous?
Short text often lacks context. The model can handle it by focusing on the tokens present. Training examples with brief requests help BERT generalize. In ambiguous cases, the user’s past behavior or curated synonyms help reduce confusion.
How do you handle items that rarely appear in training data?
Include class-imbalance strategies like oversampling underrepresented items or weighting the loss function. Also, augment data with synonyms. Continue collecting more data or incorporate external knowledge (fashion tags, metadata).
What if the system starts mixing up negations?
Negation handling relies on attention heads identifying “not” and its target. Inspect attention weights for improvement. Data augmentation with negative examples like “no jeans” clarifies the effect of negation. Post-processing rules can re-check for contradictory signals.
How do you measure success?
Define a ranking metric: recall at top-k or mean reciprocal rank to measure if the chosen items match the text requests. Also track stylist override frequency. Reduced overrides indicate higher model accuracy in capturing user intent.
How do you ensure performance at scale?
Batch-transform requests with a GPU-accelerated pipeline. Precompute embeddings for items. Store BERT-based request vectors in a fast vector index for quick nearest-neighbor searches or softmax classification. Use distributed processing if data volume is massive.
How do you prevent domain drift?
Use a periodic retraining schedule. Regularly fine-tune with newly collected notes. Evaluate on a hold-out set and re-check metrics for drift. If performance dips, incorporate new data or refine the architecture.
How might you handle multilingual requests?
Extend with multilingual BERT or a translation preprocessor. For languages not supported by pretrained models, train from scratch or adopt a multi-stage translation approach, then re-tokenize for BERT.
How do you justify the complexity of attention-based models vs simpler methods?
The jump in semantic understanding is large. Traditional approaches struggle with phrases like “no button-down shirts.” BERT identifies negations, synonyms, and co-references more precisely. Offline testing and significant performance gains in item ranking justify the cost.
How does your solution address interpretability?
Use attention visualization to see which words BERT focuses on. For interpretability, compare token attention or layer outputs. Present stylists with a short explanation of the top reasons (e.g., “Mentioned black dresses. Mentioned no jeans.”).
How do you handle out-of-vocabulary words?
BERT uses subword tokenization. Rare or new words break down into subwords. The model aggregates subword embeddings to form a representation. This is more robust than ignoring unknown terms.
How would you adapt this for a cold start?
Leverage pretrained BERT weights with minimal domain data. Warm up the final classification layers with a small subset of domain examples. Expand the training set rapidly by collecting user feedback and iterating.
How do you handle contradicting requests?
When the text says “I want jeans, not jeans” due to user confusion or typos, highlight conflicts in the user interface so stylists can manually resolve them. Optionally, track the user’s historical preference if confusion persists.
How do you avoid overfitting to ephemeral fashion trends?
Regularly retrain. Add a time decay factor in your data pipeline so older requests weigh less. Use domain signals (season, trending styles) as contextual features. Keep a healthy mix of older and newer data to ensure generality.
How do you test model reliability before deployment?
Run offline experiments measuring classification accuracy or retrieval metrics. Conduct A/B tests with a fraction of real styling sessions. Compare with a control group. Validate that user satisfaction and stylist acceptance improve.
How do you approach model scaling?
Reduce overhead with knowledge distillation, quantization, or smaller language models if inference time is critical. Use large GPU or TPU clusters during fine-tuning, then optimize for CPU deployment if needed.
What if you need real-time responses?
Adopt a streaming inference setup with an optimized inference engine. Cache or batch incoming requests. Fine-tune any pipeline components that are bottlenecks. Possibly switch to a lighter variant of BERT for lower latency.
How do you keep stylists in the loop?
Present stylists with top model recommendations and confidence scores. Gather feedback when they disagree. Retrain the model regularly to integrate stylist overrides. This ensures the system remains aligned with expert insight.