
ML Case-study Interview Question: Smarter Aggregator Search: Leveraging Knowledge Graphs and Machine Learning Ranking


Browse all the ML Case-Studies here.
Case-Study question
You are tasked with improving the search functionality of a large-scale aggregator platform that connects users with local merchants. The aggregator currently uses an out-of-the-box search system and struggles with:
Query ambiguity for certain high-frequency queries (for instance, “California roll” incorrectly returning unrelated merchants).
Minor spelling variations or colloquialisms (for example, “salsas” vs. “salsa”).
Poor understanding of broader concepts (queries for “fried chicken” vs. a specific branded merchant known for selling fried chicken).
A weak ranking mechanism that relies only on string matching rather than deeper features (store popularity, lexical context, user signals).
Propose an end-to-end redesign of this search pipeline. Describe how you would:
Handle queries to better capture user intent.
Use a recall mechanism that interprets and expands queries based on a knowledge graph.
Implement a ranking model that optimally orders the retrieved documents using contextual and relevance signals.
Evaluate success through relevant metrics and iterative experimentation.
Outline your approach in detail and provide key technical details for each step.
Detailed solution
Identifying the main issues involves analyzing two stages: recall (retrieving relevant documents) and ranking (ordering the retrieved documents). Improving them requires a pipeline that transforms raw queries into structured concepts, links them to a knowledge graph, and re-ranks the results with a machine learning model that incorporates multiple signals.
Recall step with standardized queries, concept identification, and expansion
Search systems often fail when they treat queries as simple “strings,” matching terms in a bag-of-words manner. A user typing “California roll” may see random matches for “California” or “roll,” which leads to irrelevant results. Minor spelling or pluralization variants (“salsas” vs. “salsa”) also cause mismatches.
Step 1: Standardize the input query. Convert the raw query into a canonical form. Remove noise and apply strict spell correction only when no items match exactly. Maintain a synonym dictionary to unify variants of the same concept. For instance, “KFC,” “KFZ,” and “Poulet Frit Kentucky” all become “kfc” if you have sufficient reason to believe the user wants that merchant or item.
Step 2: Identify the concept via entity linking. Match the standardized form to known entities (for instance, a “fried chicken” tag or a particular merchant). Use an internal dictionary of recognized entities. A minimal approach might rely on direct string matching if you’re only dealing with a curated set of popular queries.
Step 3: Expand the query using a knowledge graph. Construct a knowledge graph of merchants, their categories, and tags. Each node might be a store, store category, or fine-grained tag. Edges represent relationships (“parent category,” “belongs to,” etc.). A user searching for a specific merchant could also see relevant alternatives. A user searching for a category (“Asian”) could see different subcategories (“Thai,” “Chinese,” “Vietnamese”) that map to the same broader concept.
When a user queries a tag (“sushi”), prioritize merchants tagged “sushi,” and then expand to other related tags in that parent category (for instance, “ramen” under the Japanese category).
Ranking step with a context-aware ML model
Out-of-the-box ranking often prioritizes exact string matches. This works for brand-specific searches (“McDonald’s”), but fails for unbranded, broader searches (“pizza,” “noodles”). Incorporate signals beyond the simple text match.
Data constraints before a proper ML pipeline. Some legacy systems lack real-time ML inference integration. A basic logistic regression or heuristic ranking can be deployed quickly to gather training data. Once data collection is sufficient, a robust ML-based reranking approach can replace the heuristic solution.
Pointwise learn-to-rank approach. Represent each candidate (store or item) with multi-dimensional features (popularity, distance, lexical similarity, user feedback, etc.). Train a binary classifier or logistic regression to predict the probability that a user will engage with that candidate.
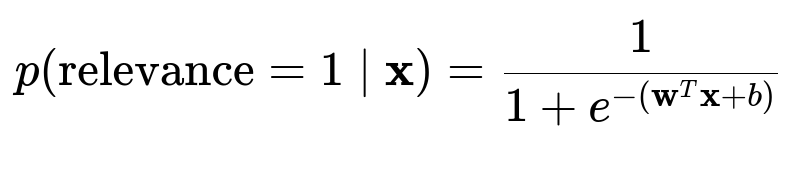
Where:
p(relevance=1 | x) is the probability that the candidate item/store is relevant given feature vector x.
w is the weight vector learned during training.
x is the feature vector for the candidate.
b is the bias term.
A higher predicted probability indicates a higher rank. Store features might include the store’s historical popularity for similar queries, textual match scores, average user rating, or contextual signals (time of day, location, etc.).
Example code snippet for a simplified knowledge graph constructor
def build_knowledge_graph():
graph = {}
# Example relationships for illustrative purposes
graph["breakfast_cat"] = {
"child_categories": ["sandwiches_cat", "bakery_cat"],
"tags": ["breakfast_tag", "breakfast_and_lunch_tag"],
"stores": ["ihop_biz", "dennys_biz"]
}
graph["sandwiches_cat"] = {
"child_categories": [],
"tags": ["sandwiches_tag", "cheesesteaks_tag"],
"stores": ["potbelly_sandwich_shop_biz", "subway_biz"]
}
# Add more categories, tags, and stores as needed
return graph
Integrate this graph into your search pipeline. When a user searches “breakfast,” gather its direct tags (for example, “breakfast_tag,” “breakfast_and_lunch_tag”), child categories (“bakery_cat”), and relevant stores. Expand the query accordingly if direct matches are insufficient.
Metrics and experimentation
Track:
Click-through rate: Ratio of clicks to overall searches for each query class.
Conversion rate: Whether the user completes a purchase after searching.
Null rate: Frequency of queries returning zero results.
Overall retention: Impact of improved relevance on user churn.
Run A/B tests comparing your new recall or ranking approach against the old pipeline. Even small percentages of improvement at high query volumes can be significant.
Iterative expansion to the long tail
Begin with the top queries (often the “head” queries) to validate the pipeline. Scale by:
Increasing your coverage in the synonym dictionary and knowledge graph.
Adding more advanced ML features for ranking, such as embeddings from neural models for better semantic understanding.
Improving real-time inference infrastructure to accommodate sophisticated models.
Follow-up question 1
How would you handle queries when item names are intentionally misspelled, like “Chick’n,” to avoid forcing them to “chicken”?
Answer Make the spell correction step very strict. Only apply a correction if no exact match is found in the index. For recognized brand names or intentionally misspelled items, keep them as-is. Collect user data on whether the corrected version correlates to actual clicks or purchases. If your system is uncertain, offer a “Did you mean?” fallback allowing the user to pick from multiple interpretations.
Follow-up question 2
What steps would you take to ensure that your ranking model continues to perform well as the catalog grows rapidly?
Answer Maintain ongoing data collection of new items, store openings, user interaction signals, and emerging synonyms. Periodically retrain the ranking model on the latest data distribution. Automate continuous integration and automated retraining pipelines to capture drifts in user queries and store availability. Regularly conduct offline experiments to confirm stable performance before rolling out updates.
Follow-up question 3
How do you handle edge cases where users search for something not in your knowledge graph or spelled in ways you cannot easily correct?
Answer Use a fallback to basic text matching. Return partial matches if no direct concept is found. Log these queries to observe recurring patterns. Update your dictionary or knowledge graph for new synonyms or popular terms. Encourage user feedback (or gather implicit signals from user clicks) to discover missing entities. Periodically re-check all no-match queries for potential expansions to your knowledge graph.
Follow-up question 4
Why might a heuristic ranker fail to produce significant gains, and how could you address it?
Answer Heuristic rankers often rely on a small set of fixed signals (for instance, string similarity plus store popularity). These signals may not capture context like user behavior patterns, user ratings, time-based preferences, or user location. A more advanced model can learn nuanced interactions among multiple features. Integrating real-time ML inference services allows for complex scoring functions (gradient boosted decision trees, neural rankers) that adapt to more diverse scenarios and user behaviors.
Follow-up question 5
What are some potential pitfalls when implementing a knowledge graph and synonyms map at scale?
Answer Synonym dictionaries and knowledge graphs can become stale if not systematically updated. Overly aggressive canonicalization can disrupt branding or lose meaning for items with intentional spelling. Manual curation is time-consuming. Avoid collisions in synonyms (different items spelled the same way). Ensure you handle expansions carefully so you do not flood the user with irrelevant or broad results. Automate testing with large sets of user queries to identify incorrect expansions or missing edges.
Follow-up question 6
How would you incorporate neural embeddings into the recall step?
Answer Convert stores, items, and queries into vector representations. Compare vector similarity instead of just token overlap. Pre-train or fine-tune embeddings on your item and query logs. Use approximate nearest neighbor search to fetch candidates with semantically similar embeddings. Combine these candidates with your knowledge-graph-based recall and lexical recall. Rank the union of these results with your final ML ranker.
Follow-up question 7
What strategy would you use to measure confidence in your expanded recall results when you add concept expansions?
Answer Track relative user engagement on expansions vs. direct matches. Monitor whether expansions produce higher conversion or reduce null results. Perform incremental rollouts: first test expansions on a subset of traffic, compare their user interactions with a control group. If expansions degrade user satisfaction or produce high bounce rates, refine the expansions or revert. Gradually extend expansions to more queries once confident in positive performance metrics.
Follow-up question 8
How would you debug a sudden drop in search relevance after deploying an update to query canonicalization?
Answer Check logs for mismatch spikes. Look at suspicious queries (for instance, queries that used to match many items but now match none). Verify if the new canonicalization incorrectly merges or splits synonyms. Investigate changes to the knowledge graph or synonyms map. Roll back the suspect update if needed. Compare user click distributions before and after. Identify which queries show the biggest shift in click or purchase patterns.
Use such iterative strategies to ensure the redesigned pipeline keeps evolving with user behavior and business growth.