
ML Case-study Interview Question: Canonical MMoE Ranker: Balancing Favorites and Purchases Across Marketplace Modules


Browse all the ML Case-Studies here.
Case-Study question
You are tasked with designing a next-generation recommendation system that can be applied across multiple recommendation modules on a large online marketplace. You need to build a canonical ranker to handle different user contexts (e.g., item pages, homepage feeds) and optimize for both long-term user engagement (captured by revisit behavior) and short-term conversions (such as purchases). The primary user signal for long-term engagement is the favorite action, which is considered a proxy for a user's intention to return to the site. The system must handle items from different modules, each with its own user-interaction patterns. The goal is to ensure that your canonical ranker performs well for every module, especially those unseen during training.
Formulate a plan to accomplish this with a multi-task model that optimizes both favorite rate and purchase rate, then propose how you would train, deploy, and evaluate this system. Discuss data requirements, model structure, multi-task balancing, and how you would ensure that the new ranker outperforms or at least matches individual module-specific rankers in production.
Detailed solution
A canonical ranker must generalize across multiple recommendation modules and user contexts. Optimizing for both purchase rate and favorite rate requires a multi-task learning setup that predicts two different but related events. The multi-task framework captures commonalities between favorites and purchases while preserving their unique patterns.
Data requirements and collection
A large, diverse training dataset spanning various recommendation modules is necessary. Each module has different user contexts (e.g., mobile app users with a high sign-in rate vs. desktop users who might be browsing anonymously). Gathering data from multiple modules ensures the model can learn patterns relevant to each context. Each training sample includes features describing the user state (e.g., user ID embeddings, recent browsing history, user segments), item attributes (e.g., item taxonomy, textual features, shop data), and context attributes (e.g., module name, device type).
Adequate representation of modules in the data is crucial. Some modules will generate more frequent interactions, so controlling sample distributions from each module ensures balanced coverage. Weighting important actions (click, favorite, purchase) can also help calibrate the label distribution across modules.
Multi-task model structure
Using a shared-bottom network with additional Mixture-of-Experts extensions handles tasks that share overlapping features while allowing differences in upper layers. The shared layers learn general representations of user behavior. Expert layers specialize in either purchase prediction or favorite prediction. Task-specific heads output separate logits.
Including the module_name feature in each layer improves representation learning. Modules differ widely, so the ranker can condition on the module context. For unseen modules during inference, a placeholder dummy name or unknown token is included during training to simulate new modules.
A simple way to combine the two tasks into a single final ranking score is:
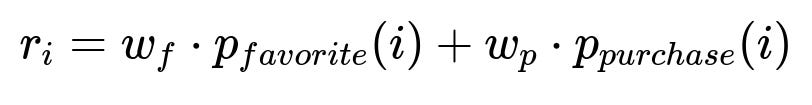
r_i is the final ranking score of item i. p_{favorite}(i) is the model's predicted probability that item i will be favorited. p_{purchase}(i) is the predicted probability that item i will be purchased. w_f and w_p are weighting coefficients that balance the emphasis between favorites and purchases.
Multi-gate Mixture-of-Experts refinement
A Multi-gate Mixture-of-Experts (MMOE) setup further refines the multi-task approach. Shared embeddings feed into multiple expert networks, each capturing different aspects of user and item interactions. Separate gating networks for favorite and purchase tasks learn how to mix the expert outputs. This approach often improves performance compared to a single shared-bottom layer, especially for tasks that share overlapping but not identical representations.
Implementation details
A typical Python implementation uses a deep learning framework such as TensorFlow or PyTorch. The workflow:
Preprocess features, including module_name.
Design the shared embedding layers for user features (IDs, categories) and item features (IDs, textual embeddings).
Construct the mixture-of-experts layers, with each expert being a small feed-forward network.
Build gating networks for each task, which output mixture weights for the experts.
Add separate heads for favorite and purchase predictions.
Use multi-task losses (e.g., logistic cross-entropy for each task) with dynamic or manual weighting.
Generate the combined ranking score with a formula like r_i = w_f p_favorite(i) + w_p p_purchase(i).
Below is a minimal PyTorch-style snippet illustrating a skeleton of the model:
import torch
import torch.nn as nn
import torch.nn.functional as F
class MMoENetwork(nn.Module):
def __init__(self, num_experts=4, embedding_dim=32, hidden_dim=64):
super(MMoENetwork, self).__init__()
self.user_embedding = nn.Embedding(num_embeddings=100000, embedding_dim=embedding_dim)
self.item_embedding = nn.Embedding(num_embeddings=200000, embedding_dim=embedding_dim)
# Shared experts
self.experts = nn.ModuleList([
nn.Sequential(
nn.Linear(embedding_dim*2, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU()
)
for _ in range(num_experts)
])
# Gating networks for each task
self.favorite_gates = nn.Linear(embedding_dim*2, num_experts)
self.purchase_gates = nn.Linear(embedding_dim*2, num_experts)
# Task-specific heads
self.favorite_head = nn.Linear(hidden_dim, 1)
self.purchase_head = nn.Linear(hidden_dim, 1)
def forward(self, user_ids, item_ids):
user_vec = self.user_embedding(user_ids)
item_vec = self.item_embedding(item_ids)
combined_vec = torch.cat([user_vec, item_vec], dim=-1)
# Expert outputs
expert_outputs = []
for expert in self.experts:
expert_outputs.append(expert(combined_vec))
expert_outputs = torch.stack(expert_outputs, dim=1) # [batch, num_experts, hidden_dim]
# Gating
fav_gate_logits = self.favorite_gates(combined_vec) # [batch, num_experts]
pur_gate_logits = self.purchase_gates(combined_vec)
fav_gates = F.softmax(fav_gate_logits, dim=-1).unsqueeze(-1) # [batch, num_experts, 1]
pur_gates = F.softmax(pur_gate_logits, dim=-1).unsqueeze(-1)
# Combine expert outputs for each task
fav_task_output = torch.sum(expert_outputs * fav_gates, dim=1)
pur_task_output = torch.sum(expert_outputs * pur_gates, dim=1)
# Task-specific logits
fav_logit = self.favorite_head(fav_task_output).squeeze(-1)
pur_logit = self.purchase_head(pur_task_output).squeeze(-1)
return fav_logit, pur_logit
This code passes user and item IDs through shared experts, then uses separate gating networks for each task. Combining the final logits with a weighting approach yields the final ranking score.
Model evaluation and deployment
During offline evaluation, track Normalized Discounted Cumulative Gain (NDCG) and area under the curve metrics for both purchase and favorite tasks. Also measure how well the model generalizes to modules not represented in the training data. Deploy the trained model behind a service that receives user requests and returns top-ranked items.
Online A/B tests measure favorite rates, purchase rates, and overall user return rates. Each newly supported module must meet or exceed the performance of its prior module-specific ranker. Once validated, the canonical ranker replaces the module-specific ranker, reducing system complexity.
Managing unseen modules
For modules not included in training, a fallback "dummy" module_name is incorporated at training time to handle unknown contexts. This approach avoids catastrophic drops in performance when new modules are introduced. If usage data for a new module is later available, it can be included in retraining to achieve tighter performance gains.
Monitoring and iteration
Constantly monitor purchase rate, favorite rate, and user return. Inspect the feature distribution shifts if module usage changes over time. Periodic retraining of the canonical model ensures it adapts to the evolving marketplace and user behaviors. Adjust the weighting (w_f, w_p) as new insights arise about the trade-off between long-term engagement and short-term conversions.
Possible follow-up questions
How would you balance the weights for favorite vs. purchase if one action is much less frequent than the other?
There are two main approaches. One way is to tune w_f and w_p directly by running small-scale experiments that measure changes in purchase metrics and favorite metrics in live tests. Another way is to adjust the training loss to upweight the rarer event so that the model still devotes sufficient capacity to it. Try a grid search for different ratios of w_f to w_p, and finalize by comparing performance in offline metrics and online A/B tests. When purchases are sparse, ensure the model still gets enough purchase-positive training samples. Higher weighting on rare actions helps the model avoid ignoring them.
How do you ensure that generalizing to new modules does not degrade performance for existing modules?
Randomly replacing some in-training module_name labels with a generic placeholder fosters resilience when faced with truly novel modules. Monitor each module's performance in offline validations to confirm that changes do not degrade existing modules' metrics. Keep track of module-wise performance in live experiments. If performance drops for a legacy module, investigate data distribution shifts or gating network behavior. Re-sample data to ensure coverage from multiple user segments and existing modules. Retrain if necessary.
Why choose a neural network rather than a tree-based model for multi-task recommendations?
Multi-task learning with separate heads (favorites, purchases) is simpler to implement with neural networks. Neural models can share hidden representations across tasks more flexibly. They handle Mixture-of-Experts easily, which is more difficult with tree-based models. Tree ensembles often require manual layering, whereas neural networks allow a custom architecture for multi-task signals. Neural networks also scale well with large user-item embedding spaces and can incorporate advanced structures like gating more naturally.
How would you handle potential negative effects on purchase rate when optimizing for favorites?
Constantly track purchase rate in both offline and online evaluations. If it decreases, adjust the weighting factors in the final ranking score. Possibly add more purchase-focused features to the shared layers. Consider dynamic weighting strategies that shift emphasis back to purchase if favorite-driven suggestions lower conversions. Segment analysis is useful to see if the purchase drop happens with certain user types or item types. Implement guardrails: only show results that meet a minimum purchase probability threshold.
Could you apply this canonical ranker to drastically different modules with minimal user-interaction data?
Yes, if there is enough user-item overlap in features. Even modules with sparse interaction data share user IDs and item IDs that appear elsewhere. The multi-task model leverages shared embeddings and can extrapolate to modules with fewer direct labels. If a completely new user segment appears (e.g., a new region or device platform), partial coverage from the existing embeddings may still help. Ensuring broad coverage in user-item embedding creation and doing partial fine-tuning when new data is available can mitigate cold starts.
Would you consider other tasks or additional signals in a multi-task framework?
Yes. Purchase and favorites can be augmented with add-to-cart, time-on-page, or collection interactions. As the number of tasks grows, carefully manage training complexity. Additional tasks often improve representation learning, but each new task can introduce overhead. Using flexible multi-gate structures or auxiliary heads can help. Continual monitoring is important to confirm that each added task does not dilute the focus on critical metrics like purchase rate.
How do you maintain low latency when using a deeper neural model for ranking?
Deploy the model on a high-performance server with GPU or specialized inference hardware. Prune large layers or reduce embedding dimensions if necessary. Optimize model architecture with quantization or knowledge distillation to shrink the network. Cache intermediate embeddings for frequently seen users or items to skip some forward-pass computations. Batch requests that arrive together. Monitor real-time inference speed and memory usage, and adjust the network depth or concurrency as needed.
How would you handle sudden shifts in user behavior or item listings?
Frequent model retraining helps adapt to changes in user interests or item inventory. Keep short intervals for data pipeline updates, possibly daily or weekly, to reflect the latest interactions. Incorporate real-time signals (recent sessions, trending items) into the ranking features. If a large distribution shift is detected (e.g., major seasonal changes or new categories), trigger an immediate retraining or rely on partial fine-tuning with new data. Monitor mismatch between offline training data distributions and online traffic patterns.
How do you evaluate success across the entire site rather than just within one module?
Track aggregated metrics like site-wide favorite rate and purchase rate. Observe user return patterns over time. Check broader funnel metrics such as long-term user retention or number of items purchased per session. A canonical ranker that works well across multiple modules should drive overall lifts in user engagement. Conduct holdout experiments on a fraction of site traffic to measure site-wide Key Performance Indicators. Confirm that improvements in one area do not cause regressions in other critical metrics (e.g., search conversions).