
ML Case-study Interview Question: Architecting ML Pipelines for Scalable Real-Time Recommendation Systems


Browse all the ML Case-Studies here.
Case-Study question
A major platform receives continuous data streams from millions of user interactions. They want to build a recommendation system to personalize content, increase user engagement, and optimize resource allocation. They maintain real-time logs, transaction data, and historical behavioral signals. How would you architect and implement a machine learning pipeline, ensuring it handles massive volumes of data, updates predictions in real time, and balances accuracy with system constraints?
Your task:
Explain your full design choices, data preprocessing steps, model selection, and deployment strategies. Show how you would evaluate success with both offline metrics and online A/B experiments. Suggest methods for scaling, fault tolerance, and fast model refresh. Include relevant code snippets, design diagrams (described in words), and any mathematical expressions central to your approach.
Proposed Solution
A recommendation system must ingest user activity data, retrieve user embeddings, then generate personalized content. Historical data captures long-term preferences, while real-time logs provide immediate context.
First, collect data from user interactions, server logs, and content metadata. Store these in a distributed data lake. Use batch workflows to unify, clean, and transform large historical datasets. Use streaming pipelines (e.g., Apache Kafka or equivalent) to capture real-time events.
Deploy feature engineering to handle continuous signals (time decay of preferences, recency weighting). Combine user embeddings with item embeddings. For generating final recommendations, choose a ranking model that processes user features, item features, and contextual signals (time of day, device type).
Train a hybrid model: a collaborative filtering backbone plus a gradient boosted decision tree or neural network layer to account for user cold starts and item popularity. Evaluate with offline metrics such as precision@k and MAP. For real-world validation, launch online A/B tests that compare user click-through rates and dwell times before and after the new recommendations.
For deployment, adopt a microservices approach. Implement a serving layer that listens to user requests, fetches updated user embeddings from a feature store, scores items with the ranking model, and returns the top content. Update models periodically or via incremental learning pipelines. Monitor model performance with a dashboard that tracks core KPIs in near real time. Use distributed computing (e.g., Apache Spark) to handle large-scale data transformations.
Below is a key formula for logistic regression that might be part of the model component:
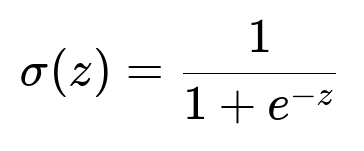
Here, sigma is the sigmoid function, z is the linear combination of input features plus bias, and e is the base of the natural logarithm. This function converts a continuous input into a probability range between 0 and 1.
Integration with a continuous deployment system ensures quick rollbacks if metrics degrade. A robust data validation layer prevents schema mismatches in production. A monitoring alert triggers if real-time metrics diverge sharply from expected ranges.
Use Python frameworks (e.g., TensorFlow or PyTorch) for deep learning segments. Below is a minimal code snippet for loading user-item interactions, creating a simplified model, and training:
import numpy as np
import tensorflow as tf
# Assume user_item_matrix is a large sparse matrix
user_ids = np.array([...])
item_ids = np.array([...])
labels = np.array([...])
model = tf.keras.Sequential([
tf.keras.layers.Embedding(input_dim=num_users, output_dim=64),
tf.keras.layers.Embedding(input_dim=num_items, output_dim=64),
tf.keras.layers.Dot(axes=2),
tf.keras.layers.Activation('sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy')
model.fit([user_ids, item_ids], labels, epochs=10, batch_size=1024)
This code creates a basic collaborative filtering approach using embeddings for users and items, then trains with user-item interaction labels.
Keep track of training time and memory usage. If the system grows too large, shard the embeddings or migrate to distributed parameter servers. Use an indexing service to enable fast item lookups.
Follow-up Questions
1) How do you address cold start for new users with limited interaction history?
A new user has few recorded events. Combine collaborative filtering with content-based filtering. Generate initial recommendations using item metadata, popular items from similar segments, and fallback defaults. If user demographics or contextual signals exist, feed those into the model to bootstrap. Introduce an exploration strategy that randomly shows novel items to gather data. As soon as new clicks stream in, update user embeddings or features.
2) How do you handle performance bottlenecks during peak traffic?
Cache frequently accessed results for popular segments. Use approximate nearest neighbor (ANN) lookups for high-dimensional embeddings. Partition data so that each service node handles a subset of requests. Precompute partial results, so the final stage merges fewer candidate items. Monitor throughput. Scale horizontally by adding more workers. Use efficient data structures for dense vector math (e.g., BLAS libraries).
3) How do you ensure the model generalizes well and doesn't overfit?
Split data into training, validation, and test sets. Use dropout or regularization in neural layers. Early-stop based on validation loss. Evaluate on multiple time windows, ensuring stable performance across recency segments. Cross-check offline metrics with actual user engagement patterns. Continuously gather feedback from production logs to confirm that the model's predictions match live behavior.
4) How would you design the online A/B testing framework?
Set up an experiment platform that randomly assigns users to control or treatment. Log user interactions separately. Compare engagement metrics (CTR, time spent, conversion rates) at high confidence levels. Gradually roll out the new model. Monitor any negative shifts in metrics. Stop or roll back if performance dips beyond an acceptable threshold. Increase traffic exposure as confidence grows.
5) How do you handle bias and fairness in recommendations?
Inspect user segments for disproportionate recommendation frequencies. Set guardrails to ensure certain items or categories are not overly penalized. Introduce fairness constraints in the model pipeline. Track disaggregated metrics across various demographic groups. If certain user segments are under-recommended, incorporate re-weighting or post-processing to balance exposure.
6) How do you manage feature drift over time?
Regularly retrain the model, updating feature transformations to reflect emerging trends. Version features in the feature store. Watch statistics on user behaviors and item popularity. If distributions shift (e.g., new items or content styles), schedule early retraining. Implement continuous deployment pipelines for quick model refresh. Use offline data checks and real-time monitoring to detect sudden changes in the data.
7) How do you optimize the architecture for frequent model updates?
Keep the training infrastructure separate from online inference. Automate data ingestion, validation, and transformation. Build a containerized environment with consistent dependencies for training and serving. Use a model registry to store metadata about the model, its hyperparameters, and evaluation metrics. Upon retraining, push a new container version to production behind a feature flag. Maintain backward compatibility so you can switch to the old model instantly if needed.
8) How do you ensure your pipeline is robust against corrupted data or upstream outages?
Use redundant data sources. Establish data quality checks to spot outliers or missing fields. Write failover logic that triggers fallback approaches if live data feeds stall. If partial data is corrupted, revert to historical distributions or default heuristics. Keep data transformations atomic and versioned. Keep a backup in cold storage so you can reprocess or rehydrate missing segments.
This solution covers the design of a scalable recommendation system. It addresses data ingestion, modeling, prediction serving, monitoring, and retraining. The follow-up answers further clarify real-world complexities around cold starts, performance bottlenecks, bias, online experimentation, and pipeline robustness.