
ML Case-study Interview Question: Accurate Quote Attribution Using Machine Learning and Coreference Resolution


Browse all the ML Case-Studies here.
Case-Study question
A large organization wants to build an automated system to attribute extracted quotes from its text archive to the correct speakers. They already parse articles to identify direct quotes. They struggle to link each quote to the right person, especially when ambiguous references like "he," "she," or "the former official" appear. They want a robust solution that can handle complex language structures, use limited labeled data specific to their domain, and leverage advanced techniques in natural language processing. As a Senior Data Scientist, how would you design, train, and deploy a machine learning model that accomplishes accurate quote attribution at scale?
Detailed Solution Approach
A robust quote attribution system relies on coreference resolution. This means detecting every entity in a text and grouping references that point to the same entity. The model identifies the correct mention (antecedent) for any ambiguous pronoun or phrase (anaphora).
Training data is essential. Humans label sample articles, linking each reference like "she" or "the former official" to the correct person. This curated dataset teaches the model how to interpret context. Because language is complex and domain-specific, smaller labeled datasets benefit from pre-trained language models (LMs). These LMs already understand general grammar and semantics but need fine-tuning to adapt to the organization’s style.
Language models learn a probability distribution over word sequences. A standard definition for a language model is shown below.
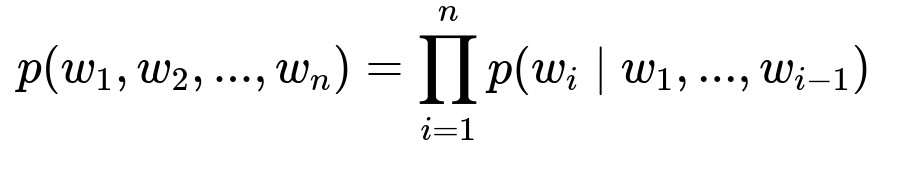
p(w_1, w_2, ..., w_n) is the probability of the entire sequence of words w_1 through w_n. The function p( ) is the language model, and w_i are the tokens.
This distribution helps generate word embeddings. Embeddings are numeric vectors that encode semantic relationships. The model uses embeddings to group references to the same entity. Since different words can refer to the same speaker, contextual embeddings disambiguate them. For instance, "Sarah" in one sentence and "She" in the next must be linked if the context signals they refer to the same person.
Fine-tuning on in-domain text is critical. Off-the-shelf models can miss domain-specific references, unusual writing patterns, or unique speaker names. The final system then assigns each quote to the speaker by matching pronouns or phrases in and around the quote to the correct antecedent. The system runs at scale by processing entire archives, storing results, and exposing them via a service for analytics or fact-checking.
Explanation of Technologies
Neural language models: Modern approaches use Transformers to build embeddings. They infer meaning from surrounding words. This global context is crucial for resolving ambiguities and detecting references scattered across paragraphs.
Coreference engines: Off-the-shelf libraries (for example, publicly available coreference resolution libraries) allow quick prototyping. They form clusters of mentions that refer to the same entity. Fine-tuning these models boosts accuracy when dealing with the organization’s data style.
Annotation tools: Human annotators draw links between an entity’s first mention and subsequent references. This ensures the training data captures subtle language usage. Consistency guidelines reduce subjectivity and maintain data quality.
Deployment: The system can be containerized and scaled horizontally. It processes articles in batches, extracts all quotes, runs coreference resolution, and saves speaker-quote pairs.
Follow-up question 1
How do you handle articles with multiple speakers of the same name or position, such as two different politicians both referred to as “the minister” in the same text?
Answer Disambiguation requires both local context around each mention and document-level analysis. When the model spots the phrase “the minister,” it checks the surrounding sentences to see who was introduced as “Minister John” or “Minister Jane.” The system then assigns that phrase to whichever entity cluster best matches. If both are plausible, the model weighs additional features, such as speech topic or any other unique descriptors. In practice, training on examples where multiple individuals share titles helps the model learn these nuances. If the model remains uncertain, it can raise a confidence score. Human review can then confirm or correct the assignment.
Follow-up question 2
What if many references are ambiguous even to humans? How do we quantify uncertainty and address potential misattributions?
Answer The model can output probability estimates for each potential antecedent. When probabilities for two speakers are close, the system flags the quote as uncertain. This is where a human-in-the-loop approach helps. Humans check uncertain cases, and their feedback updates future training data. One way is to implement a threshold. Below a certain confidence, the system defers to manual verification. This approach balances automation with quality assurance.
Follow-up question 3
Why is a rule-based algorithm insufficient, and what unique advantage does a machine learning approach offer?
Answer Rule-based methods rely on hand-crafted grammar patterns that break when faced with linguistic variations or complex anaphora. Machine learning excels because it uses learned embeddings that capture context. A model sees many examples of ambiguous phrases and learns from distributional patterns. This contextual understanding is harder to encode manually. Machine learning also adapts as language evolves, provided it has labeled examples of new patterns or terms.
Follow-up question 4
How do you evaluate the system’s performance, and what metrics should you track?
Answer You measure precision, recall, and F1-score of correctly matched references. You prepare a test set of articles with gold-standard speaker-label pairs. The model’s predictions are compared against these ground truths. Precision indicates how many attributed quotes are correct, recall shows how many quotes were identified correctly out of all possible quotes, and F1-score balances both. Additional domain-specific metrics can be added, such as checking if high-profile speaker quotes meet a certain accuracy threshold.
Follow-up question 5
If the organization needs real-time processing for breaking news, how do you optimize the model’s speed without losing accuracy?
Answer You can use efficient inference optimizations like model pruning and quantization, reducing model size while retaining most performance. Distillation trains a smaller model to mimic the larger one’s outputs. Also, caching partial results for repeated phrases or known speakers speeds up subsequent lookups. Parallel processing frameworks distribute article batches across nodes. A final load-test ensures throughput meets real-time demands.
Follow-up question 6
How do you adapt the solution if new writing styles, slang, or emerging terms appear in articles?
Answer Incremental retraining with fresh labeled examples keeps embeddings up to date. Online learning setups re-fine-tune the model at periodic intervals. If the model sees enough annotated instances of new phrasing or slang, it learns to interpret them correctly. Monitoring performance on new data highlights drops in accuracy. Ongoing annotation of recent articles and occasional re-fine-tuning address style changes.
Follow-up question 7
What is the best practice for storing and managing the labeled data and the model versions?
Answer Versioning is critical. Keep a central repository that organizes raw data, annotations, and final labeled datasets by version. Each model snapshot is tagged with the dataset version used for training. This ensures reproducibility. If an update lowers accuracy, you can roll back to a stable version. Use lineage tracking: each final model can trace its pipeline steps, hyperparameters, and code revisions.
Follow-up question 8
Why is it important to have human annotators follow clear guidelines, and how do you ensure consistency across multiple annotators?
Answer Language is subjective. Without standardized rules, one annotator might group “the official” with a person incorrectly. Clear guidelines unify how references are labeled. Consistency checks reduce noise in the training data. You spot disagreements by calculating inter-annotator agreement metrics, then reconcile them in annotation review sessions. This refinement step produces higher-quality annotations, which raises model performance.
Follow-up question 9
What would be your final steps to integrate the new solution within the organization’s existing data platforms?
Answer Wrap the model in an application programming interface that can be accessed by the organization’s systems. Ensure logs track input text, predictions, and confidence scores. Link the output to downstream platforms, like content management or analytics dashboards. Provide continuous monitoring on real-world data to detect drift. Implement alerts for performance drops, and schedule iterative improvements as new data arrives.