
ML Case-study Interview Question: Hub-and-Spoke GenAI: A Lean Strategy for Location Technology Integration


Browse all the ML Case-Studies here.
Case-Study question
The organization develops location-based technology and wants to introduce Generative AI features across its platform. They have limited AI resources yet aim to rapidly build a prototype and iterate. They also want to enhance internal workflows with AI, track measurable outcomes, and mitigate risks such as hallucinations. As the Senior Data Scientist, propose a strategy to build AI-based products for both end users and internal teams, using a small central innovation hub and local domain teams. Recommend how to integrate external AI models versus creating custom ones, how to structure the organization to democratize AI usage, and how to handle governance and workforce upskilling. Justify design decisions, scaling approaches, and potential ROI.
Proposed solution
Identifying key objectives
The primary goal is to deploy Generative AI for external products and internal workflows. The organization aims to minimize upfront costs, leverage small teams, and focus on value generation without large-scale hiring.
Core Generative AI model concept
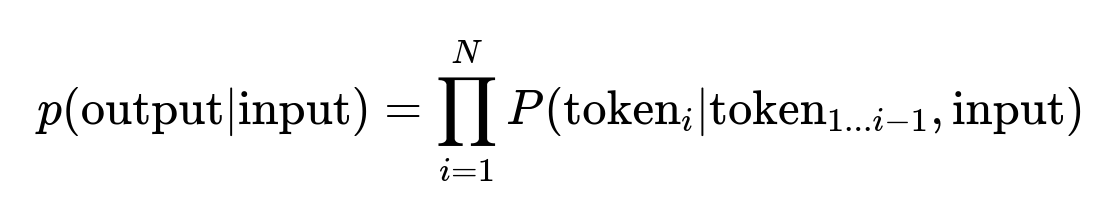
p(output|input) is the conditional probability of generating output given input. N is the number of tokens generated. token_i is the i-th token. token_{1...i-1} are previously generated tokens.
This formula governs how generative language models predict the next token. The process repeats until the output sequence is complete.
Infrastructure setup
Small central hub forms the innovation center, guiding best practices and architecture. Hub manages baseline AI infrastructure, sets coding and data standards, and offers specialized expertise in Large Language Models. Domain teams (spokes) maintain ownership of final products, relying on the hub for initial support and risk management.
Tailored AI versus external solutions
External foundational models are preferred for quick prototypes and to avoid large hardware costs. Domain teams can fine-tune smaller models if necessary, especially for domain-specific tasks. The hub monitors performance, cost, and maintenance feasibility. Over time, consider partial model customization if ROI justifies it.
Product innovation cycle
Local teams propose AI use-cases. The hub evaluates domain readiness, projected impact, and alignment with core business. If promising, they jointly create a proof-of-concept. Once viability is shown, local teams take full ownership. The hub remains available for support. This approach keeps overhead low and encourages widespread innovation.
Governance
An internal guideline framework addresses hallucinations and data security. Integrate knowledge grounding in production tools. Maintain an internal AI chatbot for secure data handling. Provide reference templates and monitor usage to reduce unintentional private data leaks. Conduct periodic compliance reviews. Adopt a risk-based approach to model updates and observe evolving regulations.
Workforce upskilling
Encourage hands-on learning with hackathons, internal AI discussion groups, office hours, and direct collaboration with the hub. Launch curated training for engineering and non-engineering roles. New employees get immediate access to AI resources. Leadership alignment is maintained through dynamic workshops and pilot demonstrations. This continuous learning culture boosts GenAI adoption without ballooning budgets.
Follow-up question 1
How do you handle the risk of Generative AI outputs that appear correct but are factually wrong?
Answer
Embed knowledge grounding in the AI inference pipeline. Extend large external models with domain-specific context retrieved from verified sources. Put a retrieval component before generation. This module fetches relevant text from domain data. Append that text to the model input prompt. Add a final validation phase with rule-based checks or smaller specialized models. Train internal teams on prompt engineering. Implement disclaimers in user-facing applications. Continuously log model outputs and keep a feedback loop for improvement.
Follow-up question 2
How do you measure Return on Investment (ROI) for these Generative AI projects?
Answer
Each AI use-case must define measurable outcomes such as user satisfaction ratings, reduced development time, or lower operational errors. Track metrics before and after deployment. Analyze productivity gains in workflows or improved feature adoption by end users. For example, if integrating an AI assistant into developer documentation shortens support ticket resolution by 20 percent, quantify that as cost savings. Use incremental A/B testing to isolate changes. Check usage frequency and error rates. Consolidate all data into a portfolio report for leadership to see which projects yield the best returns.
Follow-up question 3
How would you scale this approach once more teams want to adopt Generative AI and the hub faces potential overload?
Answer
Train more “champions” in domain teams so they can guide AI integration locally. Expand the hub’s scope incrementally by adding specialized members if demand spikes. Create templated processes for repetitive tasks like data preparation, model selection, or integration workflows. Document success stories so teams can follow proven patterns. Allow teams to share re-usable modules, reducing the need for direct hub involvement. Invest in internal AI community-building and knowledge repositories. Confirm each proposed project meets threshold metrics so resources focus on high-impact initiatives.
Follow-up question 4
How do you incorporate versioning, monitoring, and retraining in a practical manner?
Answer
Model versioning uses repository tags for model files and inference pipelines. Tag each release with model parameters and training data references. Maintain a rolling real-time dashboard tracking latency, usage patterns, and error frequencies. Implement triggers for retraining when model drift is significant or performance drops below target thresholds. Maintain a data pipeline that monitors new domain knowledge or changes in user interactions. Provide fallback mechanisms for system-critical scenarios. Automate alerts and partial rollbacks if new versions degrade performance. Offer quick rollback to stable checkpoints if needed.
Follow-up question 5
How would you integrate such Generative AI capabilities into an existing technology stack with microservices?
Answer
Wrap the model behind a REST or gRPC service. Host it on a container platform such as Kubernetes. Within microservices, call the AI inference endpoint asynchronously or via streaming if real-time responses are needed. Use circuit breakers and a load balancer to manage traffic spikes. Cache frequent model queries with minimal context differences. Gracefully handle timeouts to avoid blocking critical services. Log all calls to ensure performance measurement and debugging. For code, a simplified Python-based microservice wrapper:
import uvicorn
from fastapi import FastAPI
from inference_module import generate_text
app = FastAPI()
@app.post("/generate")
def generate_response(prompt: str):
result = generate_text(prompt)
return {"response": result}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8080)
The microservice handles requests for AI text generation. inference_module contains logic to interface with external or internal models.
Follow-up question 6
How would you maintain data security and compliance when teams are experimenting with user data?
Answer
All experimentation must use masked or synthetic data where possible. For real data, apply secure data governance, including encryption and strict access controls. Log data lineage with documented justification for AI usage. Provide a clearly stated data retention policy. If hosting internal large models, separate training data from actual user PII. Continually audit pipelines to confirm data handling meets internal and regulatory standards. Limit domain teams to only necessary subsets of data. Use automated scanning to detect accidental uploads of sensitive information into external services.