
ML Case-study Interview Question: Enhanced Social Search Relevance via Multi-Aspect and Re-Ranking Architecture


Browse all the ML Case-Studies here.
Case-Study question
You are consulted by a large social networking platform to improve the performance of its post search system. The existing search stack relies heavily on a feed-based service with multiple intermediate layers. The leadership wants to decouple the post search functionality from the feed services, allowing the search system to directly index user-generated posts and articles. The goal is to simplify system architecture, accelerate feature development, and improve search relevance with advanced machine learning models. The leadership also wants to introduce multi-aspect ranking, second-pass re-ranking, and a final diversity layer. How would you design and implement this new post search stack? How would you measure success and ensure that relevance and latency both improve?
Detailed Solution
Architecture Simplification
Engineers removed feed-based dependencies to streamline post search. The feed-oriented mixing services were replaced with a direct path through a unified “search federation” layer. This federation layer handles fanout to the relevant indices and blends the final results. The search stack no longer depends on feed mixers or unnecessary intermediate steps. This simplified design reduces query translation overhead, since fewer translation layers are involved. The system can pass the query directly to a single search backend that indexes posts and articles.
System engineers also plan to remove an intermediate query language. This will enable direct translation from the user’s text input to the final index queries. Reducing complexity like this speeds up development and makes it simpler to add new query filters.
Multi-Aspect First Pass Ranker
A first pass ranker quickly scans a large pool of documents. This ranker uses multiple lightweight models, each focusing on a different aspect such as relevance, content quality, personalization, or recency. Each aspect model outputs a numeric score. These scores are combined in a downstream step, yielding a final first pass score for each candidate post.
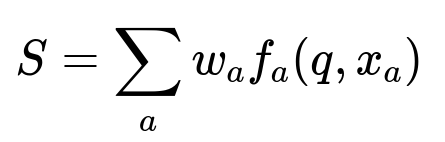
Where:
S is the total first pass score for each candidate.
w_{a} is the weight for aspect a, controlling its importance.
f_{a}(q, x_{a}) is the feature function for aspect a, given query q and candidate x_{a}.
Separating aspects in this way allows independent model tuning. For example, the recency model can be optimized to spot fresh, trending content, while the personalization model adjusts for user interests or social proximity. The final combined score is then used to retrieve a top-k set of candidates.
Second Pass Ranker
The second pass ranker operates on the top-k candidates from the first pass ranker. This ranker uses more powerful or expensive models, such as deeper neural networks. The second pass ranker has access to real-time signals, advanced embeddings, or user-interaction data that may be too slow to run on the entire candidate set. This step improves precision by re-scoring the smaller subset of candidates using richer context features, like user affinity or advanced language representations.
Diversity Re-Ranker
Engineers add a final re-ranking layer to enforce result diversity. This stage can detect near-duplicate content, prioritize emerging viral posts, and ensure coverage across different author networks or languages. Result diversity makes the user experience more engaging and balanced, preventing excessive duplication.
Offline and Online Validation
They developed a multi-pronged validation strategy. Before rolling out changes, engineers measure performance on fixed sets of queries to confirm correct filtering and ranking logic. They also build reliability tests ensuring that basic “exact match” scenarios do not break. Human-rated relevance labels and offline performance metrics confirm that the new ranking does not regress on core queries. Online A/B tests measure end-user metrics such as click-through rates, dwell time, and user actions. These measurements confirm that the new system meets engagement and latency goals.
Example Gradient Boosted Implementation
Below is a simplified demonstration of how a multi-aspect model might be implemented using Python with a popular gradient boosting library:
import numpy as np
import xgboost as xgb
# Suppose we collect training data for multiple aspects
# Feature vector X: each row has features relevant to one aspect
# Label y: ground truth or relevance score
X = np.load('training_features.npy')
y = np.load('labels.npy')
params = {
"objective": "reg:squarederror",
"eta": 0.1,
"max_depth": 6,
"subsample": 0.8
}
dtrain = xgb.DMatrix(X, label=y)
model = xgb.train(params, dtrain, num_boost_round=200)
# To get scores for new data:
X_test = np.load('test_features.npy')
dtest = xgb.DMatrix(X_test)
pred_scores = model.predict(dtest)
# The final first pass ranker might combine multiple
# aspect-specific models, each producing a predicted score,
# then summing them with separate weights.
This snippet illustrates how to handle a single aspect’s model. The multi-aspect approach would combine multiple such models.
Final Results and Observed Benefits
This new architecture improves developer productivity. Removing feed-based services cuts development time by reducing code duplication. Latency also improves because the search federation can query the index directly, with fewer roundtrips. Early data shows reduced 90th-percentile latency for mobile and web. Engagement rises because personalized and trending posts appear more frequently. Users can locate relevant content faster and can filter posts by author, recency, or other criteria more easily.
Follow-up Question 1
How would you handle personalized ranking signals when the first pass ranker cannot afford to compute them for all documents?
Answer The first pass ranker handles a large pool of documents, so it relies on cheaper models. Deep personalization features or user-graph relationships can be expensive to compute for every post in the candidate pool. Engineers run a second pass ranker only on the top-k first-pass results. This step can afford more expensive features like real-time user interests, language embeddings, or social graph distances. The second pass ranker thus achieves personalization with minimal latency overhead.
Follow-up Question 2
How would you ensure result diversity while still returning the most relevant items?
Answer The final re-ranking layer takes the top-k posts and adjusts them to remove near-duplicates, limit over-clustering from the same user, and highlight posts from different perspectives. Engineers implement diversity constraints that blend high-scoring results with some exploratory or fresh content. The system can detect patterns of duplication or repeated promotions from certain author networks and reduce their presence, improving the user’s browsing experience.
Follow-up Question 3
What strategies would you use to measure and validate these improvements offline before online deployment?
Answer They would curate a set of test queries and verify correctness using automated reliability tests. They would check that exact-phrase matching or author-based filtering still returns expected results. Human evaluation (crowdsourced) can produce graded relevance scores, especially for top results. Offline metrics such as NDCG or MRR indicate whether the newly scored results align with relevance labels. Reproducible test suites verify that the new system is stable and that no key scenarios regress. Only then do they ramp changes in controlled A/B tests to confirm performance in production.
Follow-up Question 4
What role do advanced embeddings and neural models play in the re-ranking layers?
Answer The system can use embedding-based retrieval or neural re-ranking to capture deeper semantic relationships between the query and candidate text. This is especially helpful for nuanced queries not captured by keyword matches. The second pass ranker can apply a neural scoring model that considers richer context, user intent, and potential synonyms. Embeddings also help with detecting duplicates or near-duplicates by comparing vector similarities, which contributes to a better final blend of results.
Follow-up Question 5
How would you adjust your search system for time-sensitive or trending topics?
Answer They can incorporate fresh engagement signals in near-real time. The system monitors interactions (likes, comments, and shares) and updates recency features quickly. The first pass ranker can have recency-based scoring or a specialized sub-model. The second pass ranker can refine that further by analyzing short-term engagement velocity to detect trending content. This shortens the feedback loop from hours to minutes for popular discussions or breaking news.
Follow-up Question 6
What are some key technical challenges in removing legacy query-translation layers?
Answer The legacy query layer might encode complicated rules for different verticals or content types. Removing it requires merging these rules or rewriting them directly in the search federation. Engineers must confirm that all specialized filters, personalization rules, and phrase matching are still supported. Testing is crucial to prevent regressions in search relevance or advanced query operators. Once done, it reduces code duplication and maintenance overhead.
Follow-up Question 7
What steps would you take to accommodate new content formats like short videos or audio posts?
Answer Engineers would expand the search index to handle metadata for multimedia. They might integrate transcription or image analysis pipelines. The index stores textual representations (e.g., transcripts, tags, or captions) that the ranking models can access. The second pass ranker can include features capturing video watch-time or audio engagement signals. Additional embeddings might capture visual or audio similarity. This integration ensures that short videos or audio clips appear in relevant post search results.