
ML Case-study Interview Question: Adaptable Courier Photo Classification Pipeline via Transfer Learning and ResNet


Browse all the ML Case-Studies here.
Case-Study question
A technology company manages a large volume of courier-submitted photos (for example, photos of storefronts, pizza bags, and catering layouts) and needs an automated system to classify these images quickly. The goal is to reduce external vendor dependence, cut costs, ensure data privacy compliance, and seamlessly feed predictions into internal workflows. How would you plan, design, and implement an in-house image classification pipeline that can be adapted to multiple use cases with minimal effort?
Detailed Solution
Overall Approach
A data pipeline can combine transfer learning with a pre-trained deep neural network backbone. Limited labeled images can be used for fine-tuning. This setup avoids building a model from scratch. Real-time or daily scheduled predictions can feed downstream systems quickly.
Data Curation
Teams seeking to classify images must supply labeled examples that reflect real conditions. Balanced data selection is crucial. Augmentations like random flips or rotations can increase data variety. When the business requests specific checks (like pizza-bag usage or store-closure confirmation), they provide at least a few thousand labeled images for training.
Model Architecture
Transfer learning with a convolutional backbone such as ResNet is effective. Fully connected layers on top of the backbone can adapt to each new classification goal. Training uses a standard supervised learning strategy.
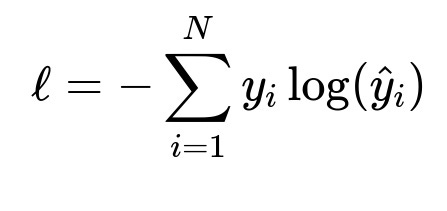
In this formula, N is the number of training samples, y_{i} is the true label (often encoded as 1 or 0 for binary classification), and hat{y}_{i} is the predicted probability. Minimizing this cross-entropy loss drives the model to match the ground-truth labels.
After training, the model’s output is typically a probability distribution over classes (for example, "has pizza bag" vs "no pizza bag").
Production Integration
A daily ETL job can pull new courier-submitted images, run inference, and store classification outputs. For faster response, a small prediction service can receive images in real time, return class probabilities, and store results for further processing. The system must handle tasks like data deletion or retention for privacy compliance.
Monitoring and Maintenance
Online metrics like false positives or negatives matter for refining the classifier. If stakeholders see too many errors, the training set must be rechecked. A dashboard can display model confidence for each class and track data pipeline health. Periodic retraining keeps the model aligned with shifting user behaviors and new photographic contexts.
Fraud Detection Example
Some couriers might upload fake storefront photos while far from the location. The pipeline can compare the submitted image against a known true storefront image. A GPS check can confirm that the courier is at the correct address. This system blends classification predictions with geolocation checks.
Benefits
Elimination of external vendor dependencies saves costs. A single in-house solution seamlessly integrates with internal data sources. Transfer learning cuts down big development cycles. As new cases emerge, the same backbone network can be reused, requiring only new labels to retrain the final layers.
Follow-Up Question 1
How would you handle the situation where there is insufficient labeled data for a new use case?
Answer
Collect a small labeled dataset from internal teams. If that is still insufficient, deploy a human-in-the-loop process to label new samples. Use data augmentation to enlarge the dataset by creating variants of existing images. Combine self-supervised or semi-supervised learning to leverage unlabeled samples and then refine with minimal labeled data. Transfer learning reduces data requirements because the backbone network already has learned generic image features. A smaller final classification layer can adapt quickly to the new target classes.
Follow-Up Question 2
How do you ensure the model remains compliant with privacy constraints when it processes user-submitted images?
Answer
Store images in a secure environment with strict access controls. Automate scheduled deletions of sensitive content after the allowed retention period. If the pipeline must keep derived features or embeddings, strip personal identifiers and keep only abstract representations. Monitor each stage of the pipeline to guarantee that no raw images or user data stay beyond retention limits.
Follow-Up Question 3
What steps would you take to confirm the model’s performance after deployment?
Answer
Sample predictions daily and validate them against a ground-truth set. Track the true-positive rate, false-positive rate, and confusion matrix. If the model powers business logic (like routing deliveries), watch user behavior to see if errors lead to higher complaint rates. Build a feedback loop where misclassified cases are automatically flagged for review and re-labeled. Such examples feed back into continuous retraining to boost accuracy.
Follow-Up Question 4
How do you decide between running inferences in real time versus in a scheduled batch mode?
Answer
Time sensitivity dictates the approach. If decisions must be made immediately (for example, automated dispatch), run a real-time service exposed via an API. If batched insights suffice (for example, periodic quality checks), schedule an ETL job that processes images at set intervals. Real-time services cost more in compute and infrastructure but offer immediate classification. ETL-based pipelines can handle large volumes efficiently if latency is not critical.