
ML Case-study Interview Question: Calibrated Machine Learning for Scalable Real-Time Ad Ranking Systems


Browse all the ML Case-Studies here.
Case-Study question
A social media platform with a large user base wants to design and scale a real-time ad ranking system that selects the highest-value ad for each user session, subject to strict latency and cost constraints. Ads come from advertisers bidding on conversion events like app installs or purchases. The platform must handle trillions of model predictions daily, cope with delayed feedback on conversions, and preserve user privacy. Propose a complete end-to-end solution, from feature engineering and model training to online deployment and monitoring, that ensures accurate predictions and calibrated conversion probabilities. Explain how you would address auction-induced selection bias, fast-changing ad inventory, and high model update frequency. Also outline how you would evaluate, A/B test, and continuously monitor this system.
Detailed solution
This system involves real-time scoring of potential ads, an auction mechanism, and continuous model updates.
Strict latency requirements mean the models must perform inference within milliseconds. This requires lightweight architectures for candidate generation, followed by heavier models for final scoring. Large-scale distributed training is crucial for speed. A warm-started training process and frequent incremental updates ensure recent data is utilized and the model is not stale.
Real-time ad ranking stages
Candidate generation retrieves a few hundred to a few thousand ads from millions. This culls ads that are clearly irrelevant based on quick checks. The heavy ML model then scores each candidate on metrics such as click probability, install probability, or purchase probability. The auction uses predicted scores, advertiser bids, and business rules to select the winning ad.
Handling auction-induced selection bias
The model only sees data from ads that won auctions. A miscalibrated score can lead to outlier ads winning more auctions. One method is to apply exploration strategies or incorporate techniques that treat unshown ads as negative samples with a certain weighting. Another way is to build a calibration correction layer that aligns predicted probabilities with observed outcomes across the entire candidate pool.
Calibration and Normalized Cross Entropy
Models must be well-calibrated. If the model predicts a total of X conversions, the true conversions should be close to X. Normalized Cross Entropy (NCE) is often used.
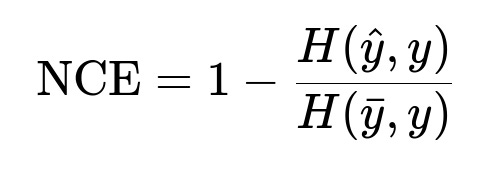
Here H(\hat{y}, y) is the cross-entropy between predicted labels and true labels. H(\bar{y}, y) is the cross-entropy of a naive model (for example, a baseline that always predicts a constant probability). \hat{y} is the predicted probability, y is the actual label, and \bar{y} is the baseline probability. NCE close to 1 indicates the model is better than the baseline. NCE close to 0 indicates no improvement.
Delayed conversions
Conversions can be reported days or weeks after an ad is shown. Waiting too long to update the model stalls adaptation. Updating too soon causes false negatives because delayed conversions have not yet been recorded. A hybrid strategy is common, where the model is trained incrementally with recent data, while older data is re-labeled with the newly arrived conversions.
Feature engineering
High-cardinality ad features and fast-changing ads require an infrastructure where new ads can be integrated quickly. Config-based pipelines accelerate feature addition so engineers do not need to manually wait for logs each time. Embeddings for user and ad features are stored in massive tables, and serving requests at scale requires specialized hardware.
Large-scale distributed training
Training on billions of rows with hundreds of millions of parameters needs data-parallelism. TPUs or GPUs reduce cost and time. A warm-start strategy retains weights from a previous checkpoint, then updates with fresh data. This frequent cycle (hourly to daily) ensures the model tracks new ads, user behaviors, or marketplace shifts.
Deployment and online inference
A specialized serving system loads the trained model, often split into multiple towers (user, ad, context). These towers perform embedding lookups, high-order feature interactions, and final predictions. After candidate ads are scored, the auction mechanism picks the winner by combining predicted probability with advertiser bid and budget constraints.
A/B testing
A budget-split approach is used. Each advertiser’s budget is partitioned so the new model can spend only a fraction of it. This prevents bias where the new model consumes too many budgets or starves the control. Random subsets of users see the new model. Core metrics (revenue, conversions, user engagement) are tracked. If the new model is stable, it fully replaces the old one.
Monitoring and incident detection
The system observes thousands of features and hundreds of models. Real-time dashboards track distribution drifts, broken features, or numeric anomalies. If the calibration drifts beyond a threshold, or the predicted probabilities differ too sharply from reality, alerts trigger. Engineers then perform a rollback or fix the feature pipeline.
What if the data distribution shifts quickly, for example when many new advertisers arrive?
A continuous warm-started update cycle addresses sudden changes. Retraining with more weight on recent data quickly adapts to new advertisers. A fallback mechanism can treat new ad identifiers as unknown, applying defaults or cold-start embeddings. A live monitoring system identifies large deviations in ad or user patterns, prompting higher-frequency training intervals.
How would you handle extremely sparse events like purchases, which can occur days after an install?
Use multi-task learning to share representation layers among correlated tasks such as clicks, installs, and purchases. The heavier label (purchase) has fewer samples, so it benefits from the more frequent signals of intermediate events (click, install). The delayed purchase label is integrated by storing event timestamps. If the model sees some purchases many days after install, the warm-started training from previous checkpoints includes these newly arrived purchase labels.
How would you address model explainability for advertiser trust?
Offer basic insights about why an ad was ranked. Maintain a secondary explainability pipeline that reports feature attributions (for instance, a simple layerwise relevance approach). Highlight top user signals or ad context that boosted the score. This helps advertisers understand how the model uses their bids or content. Heavy interpretability can be expensive at scale, so it might be restricted to sampling or offline analysis.
How would you prevent privacy leakage?
Encode personally identifiable data in anonymized or aggregated form before training. Adhere to user opt-outs by never logging or using restricted data. Use differential privacy for sensitive features. Maintain a robust data governance system that restricts access to raw logs.
How do you correct for the model’s tendency to pick outlier scores in an auction setting?
Once the heavy model is trained, apply a calibration correction layer that downweights improbable outlier scores. Use a method like Platt scaling on top of predicted probability. The layer’s parameters are updated frequently with the newest logs to keep the predictions in a correct range. This ensures that the highest predicted probability is not unrealistically high.
How would you handle hyperparameter tuning?
Auto-tune learning rates, embedding dimensions, regularization factors, and architectures through a managed platform. Use random or Bayesian search over a curated search space. Evaluate each candidate on offline metrics such as NCE and AUC, then run small-scale online tests for the best candidates. This ensures a systematic approach to finding the most effective hyperparameters.
How would you maintain high throughput and low inference latency?
Cache embeddings in memory. Keep the model footprint small with parameter sharing or factorized embeddings. Precompute frequently accessed features. Use asynchronous micro-batching if needed, although strict real-time constraints may require single-request inference. Deploy the model on specialized hardware or optimized CPU with efficient libraries.
How do you confirm a newly deployed model is not causing major revenue drops?
Monitor key business metrics such as total conversions, cost per conversion, and advertiser spend. Compare them to the baseline group using standard error bounds. If any critical KPI changes abruptly, investigate traffic distribution, score outputs, or newly added features. If needed, revert to the stable baseline model.
How would you handle repeated conversions after a user has installed an app?
Store conversion counts by user-ad pairs. Each additional conversion is treated as a separate label. Multi-task learning can incorporate multiple event types, including purchases after install. If the conversions are repeated events, the training data logs each event’s timestamp. During online scoring, the model can estimate the probability of a user performing yet another purchase, given past purchase history.
How do you manage the risk of false negatives due to incomplete logs?
Maintain a conversion window. For example, only label data as negative if no conversion is reported for a certain time frame. Retrain on data after the full conversion window to reduce false negatives. Perform partial updates with the understanding some labels may still turn positive. Over time, correct labels will flow into the model.
How do you evaluate model architecture changes when multiple tasks are involved?
Examine each task’s AUC and calibration. Also examine the combined NCE. If any major conversion type sees a regression, investigate whether more or fewer shared parameters help. Multi-tower approaches separate user representation from ad representation. If an architecture change helps one task but harms another, adjust multi-gate networks or weighting factors.
How would you design a data pipeline for new feature engineering?
Use a platform where features are declared in a configuration file. This pipeline automatically handles logging, data aggregation, transformation, and serving updates. Code changes are minimal. This speeds experimentation. Validate offline by replaying data to see if the newly engineered feature matches expectations. Then push it to production in small increments.
How do you handle memory-intensive embedding tables?
Split the tables across multiple hosts. Use row-based sharding for user embeddings, column-based partitioning for wide embeddings. Use specialized hardware with large memory capacity. If necessary, compress embeddings with product quantization or dimensionality reduction. The key is balancing representation detail with feasible memory usage.
How would you implement real-time feature monitoring?
Store feature statistics (mean, min, max, standard deviation) in a real-time buffer. Check if they deviate from a rolling average. For categorical features, track volume shifts. If an ad-ID or user-ID set spikes, alert an engineer. This ensures the data pipeline has not become skewed or broken.
How would you debug an unexpected drop in conversions despite stable calibration metrics?
Inspect feature coverage, distribution drifts, or partial system outages in the ad-serving pipeline. Check if certain user groups or advertisers are underrepresented. Confirm budgets have not been exhausted earlier in the day. Investigate user funnels (impressions, clicks, installs). If calibration remains stable but total conversions drop, it might be external market behavior or seasonality. Adjust the training schedule or weighting to adapt.
How would you ensure near real-time feedback for urgent advertiser campaigns?
Incorporate faster partial updates. If a new campaign appears, route it to a simpler but robust fallback model or zero-shot embedding approach. Schedule a mini-batch job that updates the main model embeddings after a short interval (every hour) with the partial data. This prevents the new campaign from performing poorly in the early phase.
How do you handle adversarial advertisers attempting to game the model?
Continuously track outliers in predicted scores, real performance, and advertiser budgets. If abnormal patterns appear, investigate suspicious features. Consider applying penalty terms if an advertiser’s actual conversion metrics differ drastically from predicted values over time. The system can reduce the ad’s ranking if it detects fraud or repeated low-quality interactions.
How would you finalize a model architecture that includes multi-gate mixture-of-experts or cross-net layers?
Prototype offline with representative data. Compare training curves and final NCE. Evaluate inference speed, memory usage, and cost. Test final candidates in small-scale online traffic. Confirm if multi-gate layers yield measurable calibration or AUC gains. If improvement is stable under production load, roll out fully.
How to recover quickly if a newly deployed model fails?
Use a rollback mechanism. Keep the previous stable model checkpoint ready. Switch traffic back to it if metrics degrade or if monitoring flags issues. Investigate logs. If a partial fix is easy, apply it, then redeploy. If not, revert to the prior stable state, then debug offline.
How to maintain user privacy while using user-generated signals?
Use hashed user IDs or embeddings that do not reveal identities. Apply local differential privacy for sensitive signals. Limit the direct usage of personally identifiable data. Rely on aggregated or anonymized data. Make sure user opt-outs exclude those signals from the training pipeline.
How to keep the conversation with stakeholders on track when they request immediate changes?
Maintain a clear release schedule for incremental updates. Explain that too many unverified changes can break the system. Provide a fast but safe path, like a small A/B test bucket. If major changes must be done, do them in a risk-limited environment to prevent large-scale revenue or user impact.