
ML Case-study Interview Question: Unified Lodging Ranking with Deep Learning: Balancing Relevance and Property Similarity.


Browse all the ML Case-Studies here.
Case-Study question
You are asked to design and implement a lodging ranking algorithm for a major travel platform. The platform features two types of searches:
Destination searches, where a traveler arrives to the platform directly to explore properties in a given destination.
Property searches, where a traveler clicks on an external link or ad referencing a specific property but then lands on a search page if that property is sold out.
You need to create a single model or framework that can handle both cases. The ranking must account for relevance, business considerations, and property similarity when a traveler has a strong intent for a specific property. Provide a plan to build the training datasets, engineer features, choose model architecture, and test the system. Include how you would blend relevance and similarity signals to handle both destinations and targeted properties. Propose how you would measure success in an A/B test and detail how you would deploy and monitor this system in production.
Detailed solution
A unified ranking system can rely on a learning-to-rank approach. The main goal is to predict which properties best match the traveler’s query. Destination searches rely on contextual relevance. Property searches need an extra similarity signal, because travelers who click on an external property ad often want alternatives when that property is unavailable.
Maintaining one model architecture for both search modes means using a deep neural network that processes a variety of features. This network learns a utility score for each property in a given context. Training data is aggregated from historical logs where travelers clicked or booked properties. Bookings are treated as stronger signals than clicks. Impressions with no interaction form negative examples.
Features for training include: search context (destination, dates, number of adults, children, device), property information (price, guest rating, category, amenity embeddings), similarity metrics when a property search is requested (comparing each candidate property to the originally requested property).
The final model can compute a combined score incorporating relevance and similarity. An example formula:
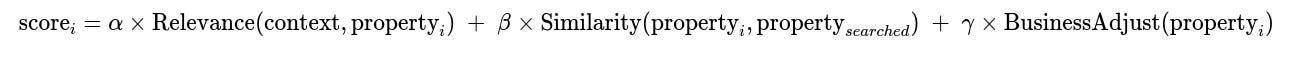
Where:
Relevance(context, property_i)is a function learned from the neural network using context and property features.Similarity(property_i, property_searched)compares embeddings or numeric attributes between the candidate propertyproperty_iand the specifically requested propertyproperty_searched.BusinessAdjust(property_i)captures strategic factors, like balancing marketplace goals or ensuring fair exposure for property owners.alpha,beta, andgammaare learned or tuned weights that scale each component.
Model training involves a large labeled dataset of historical searches. Each sample includes context, the property shown, and the traveler’s interaction outcome. The neural network treats the problem as a ranking task. A widely used approach is pairwise or listwise ranking loss to separate clicked/booked properties from ignored ones. The network’s capacity to learn complex feature interactions is key, since there are many categorical and continuous fields (destination, property type, star rating, brand embeddings).
Similarity features help the model handle property searches. The property’s embedding can be formed by a neural embedding mechanism resembling Word2Vec training, where co-occurrences of property bookings or views define vector representations. The similarity metric can be the dot product or another distance measure. This allows the model to compare each candidate property’s vector to the requested property vector.
A live system needs an A/B test to measure improvements. Metrics include:
Click-through rate on alternative properties in property searches.
Booking conversion for travelers seeking alternatives.
Overall traveler satisfaction or net promoter scores, if available.
Deployment uses model versioning and offline–online pipelines. Offline data collection and feature engineering feed the training. The trained model is served online through an inference service. Monitoring checks real-time logs to watch for drift or anomalies. Key concerns include how new properties with sparse historical data are embedded and how travelers with no prior history are handled.
A possible Python pipeline approach might involve using a popular deep learning framework to define the model, then feeding a training dataset of (search_context, property_features, similarity_features) → (click/booking labels). A minimal example:
import torch
import torch.nn as nn
class RankingModel(nn.Module):
def __init__(self, input_dim, hidden_dim):
super(RankingModel, self).__init__()
self.hidden = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, 1)
)
def forward(self, x):
return self.hidden(x)
# x might be a concatenation of context embeddings + property embeddings + similarity
model = RankingModel(input_dim=128, hidden_dim=64)
criterion = nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
# Example training loop
for batch_data, labels in data_loader:
predictions = model(batch_data)
loss = criterion(predictions, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
Possible follow-up questions and answers
How do you handle the “cold start” scenario for new properties?
The model might lack historical data for those properties. One approach is to assign default or average embeddings for the property and rely on generic features like price range, location, star rating. Another approach is to build a property embedding offline using textual descriptions or item metadata that produce a meaningful vector from a pretrained transformer-based model. This helps produce a placeholder embedding before real bookings or interactions come in.
How would you approach personalization if travelers have existing accounts?
The system can incorporate user profile features, such as loyalty tier, past booking preferences, or recent browsing. These features enrich the context vector. The neural network then learns correlations between user or user cluster features and property attributes. Personalization can also be short-term session-based or long-term. Mixing session interactions, such as recent clicks, with stable account-level data helps refine ranking in real time.
Why not use a fully similarity-based model for property searches?
Strictly focusing on similarity fails to capture overall utility or relevance. A traveler searching for a romantic getaway might want a similar boutique hotel but still needs basic relevance factors like location near their chosen city or availability on specific dates. Combining relevance and similarity in a single score is more effective than relying on similarity alone.
How do you tune hyperparameters like alpha, beta, and gamma in your score formula?
Offline hyperparameter tuning uses validation sets. The model is trained multiple times with different weighting schemes. Performance metrics (like NDCG or MRR) measure alignment with historical booking data. The best weights from the offline experiment then undergo an A/B test online. If the new model outperforms the baseline in real conversion and engagement, you adopt those alpha, beta, and gamma values.
How do you ensure business requirements do not overshadow relevance?
Relevance remains the primary driver. The business adjustments should only fine-tune the final scores. The platform monitors property exposure to detect any adverse effect, such as overshadowing smaller properties for brand-owned properties. If any bias emerges, you might revisit the weight or structure of business adjustment. The A/B test results guide final decisions to balance marketplace needs and user satisfaction.
How do you measure success and confirm statistical significance?
Booking conversion rate, gross booking value, and click-through rate to property detail pages are tracked. The A/B test splits traffic to compare the new ranking against the old. Statistical significance is assessed using standard tests like a t-test or a non-parametric bootstrap, depending on the metric’s distribution. A confidence interval clarifies whether you have enough evidence to ship the new model.
How do you handle extremely large candidate sets in real time?
A candidate generator first filters properties using simpler heuristics. The ranking model then re-ranks a smaller subset. This speeds up inference. Modern deployments may use GPU-based serving or efficient vectorized CPU libraries. A caching layer can store popular destination search results or property-based queries to reduce redundant scoring.
How do you update the model to accommodate changes in travel patterns?
Data pipelines must continuously track new user trends, seasonality, or regional shifts. Periodic retraining helps the model adapt to shifting patterns. Real-time updates might involve an online learning loop if necessary. Proper monitoring ensures that drops in performance trigger an investigation or a faster refresh schedule.
How would you deal with partial user intent in property searches?
If a traveler arrives from an external link that references an unavailable property but has flexible travel dates, you can add a small fallback flow that suggests alternative dates. The main ranking still tries to show relevant alternative properties. The model may see signals in logs of travelers who shift their dates to match the original property, and that data can inform future ranking refinements.
How would you generalize the similarity features approach to other verticals?
The method extends to any scenario where an item is pinned from an external channel. Similar embeddings that represent the pinned item and candidate items feed a similarity metric. A typical example could be e-commerce product recommendations. The same learning-to-rank pipeline merges overall relevance with item similarity to produce final scores.