
ML Case-study Interview Question: Dynamic Document Taxonomy Building with User Interaction Embeddings, t-SNE & HDBSCAN.


Case-Study question
You have a large user-driven platform where people upload a wide range of documents lacking consistent metadata. The platform wants to build a multi-layer taxonomy that classifies these documents by topic. The platform also wants to identify new emerging topics. You have access to user interaction data (for example, reading patterns) spanning many years. In addition, a team of experts has labeled a subset of these documents. How would you design a solution to:
Represent user-uploaded documents and group them by semantic similarity.
Build a taxonomy that covers both well-known and newly emerging topics.
Automatically place new documents into these categories with minimal manual labeling.
Handle the challenge of incomplete initial training data and ensure continuous improvement of the model.
Explain your approach in detail and be ready to discuss how to refine or extend your solution when new data or new topics emerge.
Detailed Solution
Data Representation and Embeddings
Use interaction data (reading sequences or engagement patterns) to create a dense vector for each document. The intuition is that if two documents share reading sessions with overlapping user cohorts, they are semantically related. Train a model similarly to word2vec, but instead of words in a sentence, consider documents in a user’s reading session. This transforms the co-occurrence patterns into vectors in a high-dimensional embedding space.
To reduce complexity and reveal latent clusters, apply a dimensionality reduction method. A popular choice is t-SNE, which preserves local distances to keep semantically related documents near each other.
t-SNE Cost Function
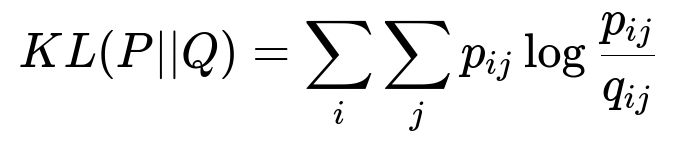
Here p_{ij} is the conditional probability of document j given document i in the high-dimensional space. q_{ij} is the analogous probability in the low-dimensional space. Minimizing the Kullback-Leibler divergence aligns the two probability distributions and pulls similar documents closer.
Clustering with HDBSCAN
Use HDBSCAN to cluster the t-SNE output. HDBSCAN discovers dense regions of points and labels them as clusters. It also identifies outliers as noise. This density-based approach provides flexibility when dealing with complex document distributions. Each cluster represents a broad topic or language group.
Examine each broad cluster and further subdivide it if needed. This two-step clustering exposes smaller, more consistent groups reflecting specific topics.
Building the Taxonomy
Combine expert knowledge with the above data-driven clusters. Start with a basic industry-level classification (inspired by standard subject headings) and enhance it with the discovered clusters. Inspect the clusters and map them to categories that might not be in the original list, such as specialized subdomains or emerging topics. Validate these new categories with Subject Matter Experts.
Categorization Pipeline
Build a supervised text classification model. Use the discovered categories as target labels. Feed each text-heavy document’s content, along with extracted key phrases and named entities, into the model. Train on a labeled dataset where each example is tied to a known category.
When confronted with incomplete or skewed training data, apply active learning. Periodically sample documents that the model is uncertain about. Have experts label them. Retrain the model. This refreshes the training set and adds coverage for categories that were not well-represented initially.
Handling Newly Emerging Topics
Monitor incoming user interaction data. Watch for new clusters. If a cluster does not map well to existing categories, label it as a possible emerging topic. This allows the taxonomy to keep pace with real-world trends. During unexpected events (for example, a new global topic), the system can adapt by detecting an unexplained cluster of documents.
Sample Code Snippet
Use Python to illustrate a lightweight approach. The real pipeline is often more complex, but this code shows the high-level workflow.
import numpy as np
from sklearn.manifold import TSNE
import hdbscan
# Suppose we have document_vectors from user co-occurrences
document_vectors = np.random.rand(1000, 128) # Example data
# Dimensionality reduction
tsne_model = TSNE(n_components=2, perplexity=30, random_state=42)
reduced_vectors = tsne_model.fit_transform(document_vectors)
# Clustering with HDBSCAN
clusterer = hdbscan.HDBSCAN(min_cluster_size=15, min_samples=5)
labels = clusterer.fit_predict(reduced_vectors)
print("Cluster labels:", labels)
Keep refining from this point, add a classification layer, incorporate active learning, and build the taxonomy with your domain experts.
Further Explanation of Active Learning
Active learning systematically picks documents where the model’s confidence is low or conflicting. Experts re-label them correctly and feed these examples back. This process repeatedly closes gaps in the training set and corrects model biases. This technique helps handle corner cases, like documents mentioning many countries but having non-travel-related context.
Zero-Shot Topic Identification (Optional)
After clustering, test zero-shot methods to name each cluster automatically. Gather the top key phrases for a cluster. Use a zero-shot classifier with prompts like “Is this cluster about business?” “Is this cluster about literary criticism?” to score each candidate topic. Select the highest-confidence topic label to reduce reliance on purely manual annotation.
Possible Follow-up Questions
How do you maintain high-quality labels when you have many annotators?
Explain that standardizing category definitions is vital. Maintain clear annotation guidelines. Routinely measure inter-annotator agreement. Resolve discrepancies through discussion or small calibration sessions. Emphasize that consistent labeling ensures the model learns stable patterns.
How would you detect if your model has assigned many documents to an incorrect category?
Monitor performance metrics. Inspect confusion matrices for frequently misclassified documents. Periodically run active learning to identify mislabeled samples. Track category distributions. If a category unexpectedly grows or shrinks, investigate by sampling newly labeled items. This catches anomalies in real time.
Why use t-SNE for dimensionality reduction instead of Principal Component Analysis?
t-SNE preserves local structure better, revealing distinct clusters when data may have non-linear separations. Principal Component Analysis is linear and might blend clusters that t-SNE separates. t-SNE’s non-linear nature is well-suited for detecting nuanced topics. However, t-SNE can be slower, which is why optimized versions like FIt-SNE help with large datasets.
How would you integrate domain knowledge from experts when your data-driven clusters conflict with expert expectations?
Work closely with experts to refine categories. If a data-driven cluster seems valid but differs from the original taxonomy, discuss if the taxonomy should expand. If experts decide that certain clusters do not align with business needs, the cluster can be merged or re-labeled. The final taxonomy should balance data-driven patterns with expert domain constraints.
How do you ensure the process remains scalable with increasing data volume?
Design distributed pipelines. Use approximate nearest neighbor search or sampling techniques to handle large amounts of interactions. Rely on optimized t-SNE variants (for example, FIt-SNE). Parallelize HDBSCAN or break the dataset into sub-cohorts before merging clusters. Regularly re-train and re-cluster if new data significantly changes the distribution.