
ML Case-study Interview Question: Scaling Deep Learning Recommenders: Architecture, Deployment, and Continuous Improvement.


Browse all the ML Case-Studies here.
Case-Study question
You are tasked with leading a project to improve a major platform’s recommendation system. The platform has a large user base with diverse preferences. The goal is to boost user engagement and transactions by serving personalized recommendations. Management wants a production-ready solution with scalable architecture, accurate models, and quick iteration cycles. Propose a complete plan, including data pipelines, model design, training strategy, and online deployment, then walk through an evaluation methodology and potential challenges.
Proposed Solution Approach
Building a recommendation system requires careful data selection and feature engineering. Each user has a unique behavior pattern. Distilling those behavioral signals into features is crucial. Data ingestion could involve combining transaction logs, clickstream records, and user profile metadata. Processing should be robust for real-time updates. Model training might involve factorizing user-item interactions or training deep neural networks. The choice depends on resource availability, interpretability needs, and problem constraints. A ranking framework can help reorder recommendations based on estimated relevance. Modern pipelines often integrate an online learning loop to capture shifting user preferences. Implementation typically proceeds with distributed processing frameworks for large-scale datasets. Deployment uses a containerized, load-balanced setup that handles real-time inference. Monitoring with A/B testing or multi-armed bandits refines the approach iteratively.
Core Mathematical Expression
A common training objective for classification-based recommenders is cross-entropy loss, which measures the difference between predicted probabilities and actual labels. For N training examples, y_i is the ground truth label, and p_i is the predicted probability.
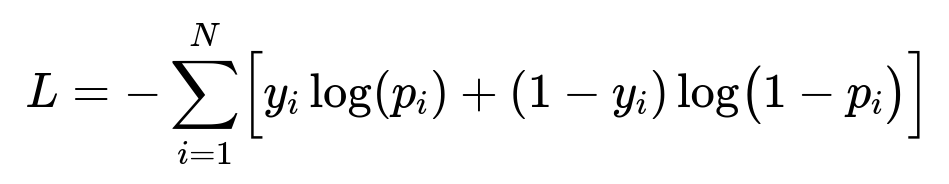
The term y_{i} indicates whether the user actually interacted (1) or did not interact (0) with the recommended item. p_{i} is the model-estimated probability of interaction. Summation runs over all training samples N. Minimizing this loss aligns predicted probabilities with true user interactions.
Detailed Reasoning
Data pipelines begin with raw user logs. A transformation step filters noisy events and aligns them with user IDs and item IDs. A feature store is useful to store aggregated stats, such as the number of page visits or average spend in recent sessions. Model selection revolves around balancing complexity and interpretability. Factorization machines or gradient-boosted trees can work well for tabular data. Deep neural networks can capture complex patterns. Training cycles involve repeated passes over the training set and periodic validation checks to prevent overfitting. Hyperparameters can be tuned with grid search or Bayesian optimization. Once a model meets baseline accuracy, it is deployed behind an API. Real-time requests flow in, fetching user features, applying the trained model, and returning top-N recommended items. Live metrics are tracked to confirm improvement in click-through rate or total revenue. If performance stalls, new features or architectures are tested in controlled experiments. This loop continues until production goals are reached.
Follow-Up Question 1: How would you handle the cold start problem?
A new user with little interaction history can frustrate any system reliant on past data. Approximate solutions rely on similarity measures or demographic inference. For example, an approach might use profile metadata to bucket new users based on location, age range, or device usage. Another technique leverages globally popular items. As the user interacts over time, the system refines recommendations. Alternate approaches include embedding-based systems that generalize from limited signals. Short session-based models sometimes capture real-time user behavior on the fly. Balancing speed with accuracy is key. Practical systems store minimal user signals from the earliest actions, such as page views or clicks on any item, to bootstrap the personalized recommendations within minutes of new-user activity.
Follow-Up Question 2: How do you manage data leakage during model training?
Unintentional contamination occurs when future user actions slip into the training set. This artificially boosts performance but destroys reliability. Preventing data leakage involves correctly slicing the data into past and future segments, ensuring no overlap in timestamps. Validation sets must reflect real-world ordering of events. Additional checks include removing unrealistic features that contain post-event knowledge. Automated pipelines can incorporate partitioning logic based on event timestamps to avoid errors. If an offline test set yields overly optimistic results, suspect data leakage. A well-structured versioning system for datasets helps maintain consistent splits. Production results then mirror or closely match offline metrics.
Follow-Up Question 3: How do you scale online inference for millions of requests per day?
Inference latencies must remain low to preserve a responsive user experience. A popular approach is to serve the model in a containerized environment with auto-scaling support. The system spins up extra containers during traffic surges. Efficient feature retrieval is also essential. Storing precomputed user embeddings in a fast-access in-memory database can reduce inference overhead. Caching frequently accessed item representations can further speed lookups. If the model is large, techniques like model distillation or quantization can shrink the model while preserving accuracy. Distributing inference across multiple machines and using asynchronous queuing frameworks can handle high concurrency. Monitoring resource usage and request throughput with real-time dashboards reveals bottlenecks. Optimizing these layers ensures minimal latency even under peak loads.
Follow-Up Question 4: How would you measure business impact in an A/B test?
Defining a single metric such as click-through rate is often insufficient. Revenue and user retention can provide a broader view. A typical setup randomly assigns users to a control group (current system) or a treatment group (new recommendation model). Engagement metrics, order conversion rates, and user session length are monitored. Statistical tests verify whether observed differences are significant beyond random fluctuation. For short test windows, advanced methods like sequential testing help detect changes quicker. If results are unclear, segment-based analysis can reveal if certain user groups respond differently to the new system. Thorough instrumentation ensures no hidden biases. Once confirmed, the new model can fully replace the old one. Continuous or periodic A/B testing remains in place to track performance drift over time.
Follow-Up Question 5: How would you ensure model explanations and interpretability?
Many recommendation systems function as black boxes, which complicates trust. Explanation can be approached by capturing feature importance or using surrogate models. If applying tree-based methods, extracting top features is straightforward. When using deep neural networks, techniques like integrated gradients or attention maps highlight influential inputs. Explanation can be shown to stakeholders or even to end users, though it must be concise and user-friendly. The system might display a short message like “Recommended because you enjoyed similar items.” An internal data science dashboard can show item embeddings or user feature attributions. This fosters confidence among business teams and can help identify data errors. For regulated industries, compliance might mandate traceability. Detailed logs of decisions and model versions address that need.
Follow-Up Question 6: How do you mitigate concept drift and ensure system resilience?
User behavior evolves. A model trained on last month’s data may degrade as preferences shift. Scheduled retraining or continuous training can handle gradual changes. Monitoring performance in near real-time detects severe drifts early. If metrics drop suddenly, a rollback to a stable checkpoint can buy time while investigating root causes. Retraining with the latest data helps maintain relevance. Robustness testing with artificially perturbed data ensures the system does not fail under unusual conditions. Models that adapt quickly with partial online updates might yield stable performance. Even with such strategies, constant oversight is essential. A cross-functional approach involving platform engineers, product managers, and data scientists keeps the system resilient and consistently aligned with business goals.
Follow-Up Question 7: What is your approach to feature selection and engineering at scale?
Many potential user and item features exist. Not all matter, and some can harm performance by adding noise. A systematic approach to feature selection begins with domain knowledge and exploratory data analysis. Correlation checks with the target variable can prune obviously irrelevant features. Highly correlated features can degrade model performance if the algorithm overfits. If an advanced model (like a deep network) is used, it can handle many features but still suffers from noisy or sparse inputs. Autoencoders or embedding layers can compress high-dimensional data into compact representations. Feature crosses can capture higher-order interactions, especially for large but structured data. A minimal set of robust features is easier to maintain and interpret. Automated pipelines that log feature usage and performance across multiple experiments help guide further improvements.
Follow-Up Question 8: How do you handle offline metrics versus online metrics discrepancies?
Offline validation is a proxy and might not mirror real behavior. The offline dataset may not capture the nuance of real-time user decisions. Overfitting to offline metrics leads to suboptimal online performance. The best remedy is continuous feedback from production. Monitoring user click patterns, dwell times, and conversions reveals if the offline-trained model truly resonates with users. When discrepancies occur, examining user segments can clarify if certain cohorts were underrepresented in the offline data. If user preferences evolve quickly, static offline data becomes stale. A possible fix is partial incremental training on fresh logs. Another approach is to carefully design an online experiment to confirm any new model improvements. Merging offline and online feedback closes the loop between model development and real-world results.
Follow-Up Question 9: How would you incorporate deep learning architectures?
Embedding-based methods excel at handling large numbers of users and items. A two-tower model architecture is popular. One tower encodes user representation, and the other encodes item representation, producing dense vectors in a shared space. During inference, a dot product approximates compatibility between user and item. Convolutional networks or recurrent networks can process sequential data like a user’s viewing history. Transformers can capture long-range patterns in user interactions. Training complexity might be higher, so hardware resources and data pipeline throughput must be considered. Testing smaller-scale prototypes helps ensure viability before expanding. Proper regularization mitigates overfitting. Model interpretability can be more challenging, so integrated gradients or attention-based methods might provide partial clarity.
Follow-Up Question 10: How do you deal with real-time feedback for model updates?
Engineering a live feedback loop requires capturing user responses the instant they occur. A streaming system processes these events, extracting features such as time spent viewing an item or any immediate clicks. This data passes through a message bus, then gets appended to a storage system that the model retraining job can query. Real-time feedback allows near-instant adaptation but can introduce instability if not handled carefully. A practical approach is a rolling retraining mechanism that updates the model every few hours or daily, balancing reactivity with computational cost. Feature transformations are repeated consistently to avoid mismatch between training and serving. Monitoring ensures that any anomalies in incoming data do not corrupt the model. Consistency checks and fallback to a stable version minimize risk.
(End of Case Study)