
ML Case-study Interview Question: Feature Store for Real-Time Ranking: Unifying Batch and Streaming Features


Browse all the ML Case-Studies here.
Case-Study question
A large online wholesale marketplace wants to build a real-time ranking system for its product listings. They already have a set of batch-computed features used in offline models. They also want to incorporate real-time signals, such as recent user actions, so they can personalize and optimize their search and recommendation results for maximum relevance.
They must design and implement a feature store that consolidates both batch and real-time features. They must ensure low-latency retrieval during inference while supporting robust monitoring, versioning, and easy discoverability of features. The system should also streamline model training by logging all features used at serving time, so training sets align with online conditions.
How would you design and implement this feature store? How would you integrate it with your real-time ranking stack, address combinatorial feature interactions (user-item, brand-item, etc.), and ensure the training pipeline remains consistent with what happens at inference time?
Provide a detailed plan covering data orchestration, offline pipelines, real-time calculation, monitoring, and a mechanism for reusing the same features for training and prediction.
Detailed solution
High-Level Overview
Start by creating a single platform to manage features for both training and real-time inference. Use a batch component (orchestrated by a scheduler) to compute offline features, and a real-time component in the backend service to generate on-demand features. Store these in a central location for consistent access.
Offline Feature Computation
Use a scheduling framework such as Airflow to run daily jobs that compute features in a data warehouse. Write each feature to a unified store with a long-format schema like [feature_name, entity_id, date, feature_value]. Keep a global feature registry to list each feature’s definition, author, creation date, and validity window. This helps discoverability and prevents duplication. Use an extract-transform-load process that fills a feature table, and pivot it from wide-format to long-format so new features can be added without changing the schema.
Real-Time Feature Computation
Implement a real-time component in the backend service to handle dynamic signals. Fetch frequently updated info such as user actions or item properties. Use existing embeddings from the offline store to calculate on-the-fly similarity or user-item interaction scores. Cache these computations briefly in memory or Redis for quick lookups. Keep the logic modular so data scientists can add new code for real-time features without affecting the entire codebase.
Online Serving
Deploy a Redis or DynamoDB layer to store and retrieve precomputed batch features with minimal latency. Structure keys by entity identifiers (or multiple identifiers if combining user and item). At request time, form a ranking context containing user identifiers, item identifiers, and other relevant IDs. Query the store for the batch features, compute real-time features, then merge. Feed this consolidated vector to the ranking model.
Logging for Training
Log all feature values at serving time into a dedicated table. This ensures each example in training exactly matches how the feature was computed in production. When training data is needed, pivot the logs into rows of features and labels. This approach avoids training-serving skew because the same code and data pipeline used for inference is used for training.
Monitoring and Validation
Use daily checks in the scheduler to confirm that each feature’s data is not empty, has valid ranges, and follows expected distributions. Apply z-score anomaly detection on feature distributions over time. Set up alerts when features go missing or their mean or standard deviation changes abruptly.
Example Code Snippet
Below is a simple Python-style pseudocode for a real-time feature computer that calculates retailer-product embedding similarity. Assume embeddings are stored offline but fetched at runtime. Explanation follows the snippet.
class RetailerProductFeatures:
def __init__(self, embedding_store):
self.embedding_store = embedding_store
def compute_embedding_similarity(self, retailer_id, product_id):
retailer_embedding = self.embedding_store.get_embedding("retailer", retailer_id)
product_embedding = self.embedding_store.get_embedding("product", product_id)
if retailer_embedding is None or product_embedding is None:
return 0.0
# Simple dot product for similarity
dot_product = sum(r * p for r, p in zip(retailer_embedding, product_embedding))
norm_r = sum(r**2 for r in retailer_embedding)**0.5
norm_p = sum(p**2 for p in product_embedding)**0.5
return dot_product / (norm_r * norm_p)
def get_features(self, retailer_id, product_id):
similarity = self.compute_embedding_similarity(retailer_id, product_id)
return {"retailer_product_embedding_sim": similarity}
The snippet loads embeddings for both entities, computes a dot product, normalizes by the L2 norms, and returns a similarity feature. The offline pipeline produces these embeddings daily. The real-time component fetches them, computes similarity, and returns an immediate value for the ranking pipeline.
Sample Core Model Score Function
Assume a linear combination of features. Let x_1, x_2, ..., x_n be the real-time and batch features. Let w_1, w_2, ..., w_n be learned weights. The model score could look like:
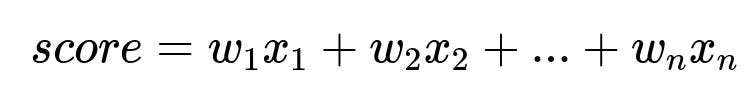
Here, w_i are model parameters learned from historical data. x_i are features such as embedding similarity, user engagement stats, or item popularity. The model might be a logistic regression or neural network. The final score is used to rank items.
x_1, x_2, ..., x_n are numeric feature values (for example, x_1 might be the embedding similarity, x_2 might be recency of last visit, etc.). w_1, w_2, ..., w_n are learned coefficients that weight these features. At inference time, the system fetches each x_i, computes score, and orders items by descending score.
Practical Implementation Details
Use a stable mechanism to manage the feature store, ensuring schema consistency. Introduce an environment variable or centralized config to handle feature versioning. If you add new features, log them for future training without affecting the current live model. Store everything in a robust store like S3 or BigQuery for offline, and replicate only the necessary daily snapshot into Redis or DynamoDB for quick retrieval.
Make model deployment easier by reusing the same feature mapping. When a new model trains on the same logged features, it can pick up automatically once you roll it out. Confirm that your cache invalidation or TTL in Redis is configured to handle stale data gracefully.
Keep the pipeline consistent by not rewriting old feature values for training. Instead, rely on the logs. Ensure that each record has a timestamp that correlates with the user event time. That alignment is critical for time-based labeling or future performance analysis.
Use robust error handling. If the real-time backend cannot compute a feature, fallback to a default or zero-like value. Monitor such fallback rates to see if there are pipeline bottlenecks.
How to answer follow-up questions
What if the batch pipeline fails, causing missing features at inference?
Use best-available caching. Let the system serve the latest available version of each feature within a reasonable time window. If a feature is missing entirely, either drop it or use a default fallback. Monitor daily tasks for signals of failure. If the pipeline fails entirely, either revert to a simpler fallback model with fewer features or degrade gracefully until the pipeline is fixed.
How do you manage feature drift?
Implement daily statistical checks. Compare mean, standard deviation, and distribution histograms with a baseline. Log anomalies in real time. If suspicious drift occurs, alert the team. Investigate changes in the data upstream. Sometimes user behavior shifts. Other times a pipeline bug might corrupt a feature. Tag training sets with the date range to track performance over time and diagnose drift.
How do you handle user-item interaction features without a massive offline combinatorial explosion?
Use real-time lookups for user-item interactions. Store user embeddings and item embeddings separately. Compute similarity or other transformations on the fly. Caching frequently used pairs helps when traffic is high. Rely on incremental computations. Do not store all user-item features in bulk offline. Instead, log user interactions (clicks, favorites, purchases). Summarize or transform them in the offline store if needed, but keep the dynamic interactions in real-time logic.
What if you need a bigger training set than what you have logged so far?
Log-and-wait imposes a limit: you can only train on data that has been collected since you started logging all features. If you realize you need more data, you must wait for the logging system to gather it. Alternatively, you can approximate real-time features for older data by replicating the same computations offline, but it risks training-serving mismatches. In most cases, accept the waiting period to maintain consistency with your production pipeline.
How do you handle embeddings in the feature store?
Write them as dense numeric arrays to a separate table or object store. Use a stable naming scheme like [entity_type, entity_id, date, embedding]. For real-time serving, load them into a caching layer or memory store. Keep an offline job that refreshes embeddings daily. If new embeddings are too large, store them in a scalable system, and fetch them on demand. Pre-warm caches for frequently accessed entities to reduce inference latency.
Could you adopt a different system that backfills real-time features for training?
Yes, but it becomes complex. You must replicate real-time logic exactly in an offline environment. Minor drift between offline code and real-time code can degrade performance. The log-and-wait approach ensures the same code that runs online also produced the feature in training data. A backfill system offers more flexible lookback windows, but requires extra maintenance and can introduce feature computation mismatches.
How do you confirm that the same feature transformations apply during both training and inference?
Deploy the same Python or SQL code for real-time and batch contexts. For real-time transformations, wrap them in a dedicated library used by both the production environment and the offline data pipeline if you want to replicate them. If you only rely on logging, the training set uses exactly what was served. Thorough unit tests can verify feature transformations match. Integration tests that simulate a real call can confirm the pipeline logs the correct outputs.
What approach would you use to keep system latencies acceptable?
Load batch features from an in-memory store such as Redis. Pre-warm high-traffic keys. Keep offline computations in well-optimized SQL or Spark jobs. For real-time features, keep logic minimal and avoid heavy queries. Cache repeated computations. Place strict timeouts. If the real-time component fails to compute a feature quickly, skip it or use a fallback. Profile your system regularly with synthetic and real load tests to ensure ranking responses meet your service-level agreements.
Why is log-and-wait especially appealing for a fast-moving team?
Any new feature automatically lands in the logs. No extra offline pipeline is needed. No manual alignment is required. Data scientists can iterate quickly, spinning up new models that rely on that logged data. They do not have to ensure offline transformations match the online transformations, because the logging is done at serving time. This tightens the feedback loop and avoids mismatch bugs.
Use these explanations when discussing design decisions with interviewers. Demonstrate that you see the end-to-end picture: data ingestion, feature computation, caching, training, inference, and monitoring all require a solid plan to maintain consistency, reliability, and low latency.