
ML Case-study Interview Question: Personalizing Geo-Notifications with XGBoost Relevance and PID Volume Control


Browse all the ML Case-Studies here.
Case-Study question
A social platform wants to personalize real-time notifications for users about new or trending posts in their geographic vicinity. The previous system used simple heuristics and random audience sampling. The goal is to improve relevance for each user and also control notification volume to avoid spam. The key constraints include timely delivery, personalized ranking for email and push channels, and dynamic thresholds for limiting total weekly notifications. Design a machine learning system to handle real-time ranking and volume management, explain how you would train and serve the models, and discuss approaches to manage notification frequency while preserving user trust.
Detailed Solution
Overview
This solution uses a tree-based model for relevance scoring, a budget-based approach to manage total notifications, and a closed-loop controller to adjust per-user notification thresholds. The main objective is to ensure only the most relevant notifications are sent to each user, while respecting a weekly budget that prevents over-notifying.
Model Choice and Features
A gradient boosting system such as XGBoost is used to predict the probability that a user will click or tap on a given notification. The model trains on historical interactions. It uses: Content features capturing text topics and engagement metrics (clicks, taps). User features capturing user activity frequency, recency of visits, and embeddings. Author or post-level features capturing geographic proximity and semantic similarity with the user’s interests.
Data preprocessing constructs embeddings for text and user or author profiles. These embeddings are combined via simple vector operations (for instance, dot product) to measure similarity. The combined features feed into the XGBoost model, which outputs a relevance score.
Volume Management
Each user receives a weekly notification budget. This indicates the maximum number of notifications to send for email and push channels separately. A real-time pipeline scores candidates with the model. If the user’s weekly quota is not exceeded, a decision to send or skip is based on whether the score surpasses a dynamic threshold for that user and channel.
Dynamic Thresholding
The threshold must be set intelligently to meet each user’s quota without going over or under. A PID controller is used to converge on a threshold that satisfies the budget over time. The PID controller reads the difference (error) between actual sends and the user’s budget and updates the threshold accordingly.
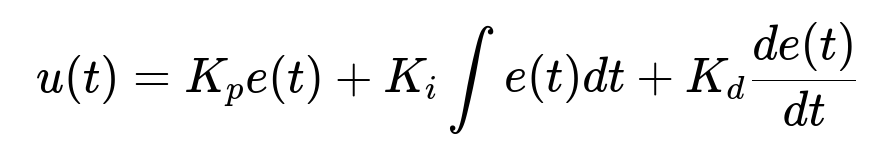
Here, u(t) is the threshold adjustment for the user’s channel, e(t) is the error between sent notifications and the target budget, and K_p, K_i, and K_d are constant gains for proportional, integral, and derivative terms. A daily batch job calculates these errors based on rolling seven-day metrics, then updates threshold values in a fast in-memory data store like redis. Real-time scoring only sends notifications when scores exceed the stored threshold.
Real-Time vs. Scheduled Approach
Real-time notifications ensure timely delivery for urgent posts. This design demands robust error handling, since pipeline outages or miscalculated features can alter thresholds. An alternative is scheduling notifications at fixed times tailored to each user’s engagement patterns, then ranking the best candidates together. Combining both approaches can preserve timeliness for urgent updates and also allow a more efficient ranking for less urgent posts.
Example Code Snippet (Pseudo-Python)
# Relevance scoring
import xgboost as xgb
import redis
# Load user threshold for email
r = redis.StrictRedis(host='localhost', port=6379, db=0)
threshold_email = float(r.get(f"user_{user_id}_email_threshold"))
# XGBoost model inference
score = xgb_model.predict(features_vector)
# Decide whether to send
if score > threshold_email and user_email_budget_remaining > 0:
send_email_notification(user_id, post_id)
record_send_event(user_id, "email")
Explain in a paragraph: This snippet retrieves a user’s threshold from redis, computes a prediction score using a preloaded XGBoost model, checks budget constraints, and then decides if it should trigger an email notification. For push channels, a similar threshold and budget are used.
Potential Follow-up Questions
How would you handle embedding generation for post text and user profiles?
Word embeddings can be pre-trained on the platform’s historical text. Each user profile can be aggregated by reading all posts authored or engaged with by that user, then averaging word embeddings or applying a more advanced approach. To incorporate real-time data, partial re-training can be scheduled periodically, or updated embeddings can be written incrementally. The final user embedding is stored for fast retrieval during scoring.
How would you ensure model quality when a post is scored multiple times as it trends?
Keeping a single representation for the post content helps avoid double-counting. The model’s dynamic features can capture how engagement evolves (clicks, taps, or comments). The pipeline re-scores the post with the updated engagement data. However, a tracking system must ensure a notification is only delivered once per user per post, or that subsequent triggers for the same post are meaningfully distinct (such as a major update to the content).
How would you address PID threshold oscillations if the weekly budget changes drastically?
Calibrating PID parameters is critical. Overly large K_p, K_i, or K_d can induce oscillations. Moderating these gains helps smooth threshold adjustments. A soft target slightly below the true budget allows small positive errors, which helps the system avoid constantly overshooting or undershooting. Monitoring daily or weekly metrics can show if the thresholds oscillate. If so, re-tune the coefficients or clamp large jumps in threshold adjustments to ensure stability.
How would you handle sudden changes in user behavior that may invalidate the learned thresholds?
Abrupt shifts, such as mass unsubscribes or spikes in post volume, could create errors in PID updates. Real-time logging must detect these anomalies and override or reset thresholds if needed. A fallback approach can revert to a safe baseline threshold. Additional gating logic can ensure extraordinary circumstances do not blow past budgets or block relevant content.
How would you test the effectiveness of the new approach?
An AB experiment can be set up where half the users receive notifications from the new ML approach, and the other half follow the legacy heuristic. Core metrics include click-through rates, user engagement (daily active counts), unsubscribe rates, and user satisfaction. Comparing these results over a defined period can demonstrate if the ML-driven system yields better relevance and retention.
Would you store separate models for email and push channels?
A single model can handle both channels by including the channel as a feature. This shares training data across email and push, allowing the model to learn channel-agnostic patterns. However, separate thresholds and budgets for each channel ensure volume control.
Could you refine the system to handle multi-objective optimization, such as balancing clicks and unsubscribes?
A multi-objective approach can involve weighting clicks and unsubscribe rates in the loss function or training separate models for relevance and risk, then combining them. Another solution is to build a single reward metric that penalizes unsubscribes heavily while rewarding clicks. This ensures the system does not blindly chase engagement at the cost of user trust.