
ML Case-study Interview Question: Two-Tower Models & ANN for Low-Latency Personalized E-commerce Recommendations.


Browse all the ML Case-Studies here.
Case-Study question
A large e-commerce platform with over 150 million users and more than 1.5 billion active product listings wants to build a deep learning based retrieval system for personalized item recommendations. They aim to use user click history on the site to generate embeddings for users and items, then rank and retrieve the most relevant items for each user in near real time.
They need an architecture that balances low latency and high relevance, can evolve from daily offline updates to fast online updates, and can handle massive data volumes. They have multiple teams building or maintaining data pipelines, GPU-based model inference, approximate nearest neighbor (ANN) indexes, and caching layers.
How would you design such a system to handle embedding generation, retrieval, and real-time recommendations at scale, starting from a simpler offline approach and eventually reaching a production-grade near real-time pipeline?
Provide details on:
The core modeling approach for creating user and item embeddings.
The infrastructure changes needed to progress from daily offline generation to near real-time updates.
The role of approximate nearest neighbor search for item retrieval.
How you would handle latency requirements while serving large traffic.
The pros and cons of each stage of evolution.
Write your solution in detail, explaining your reasoning for each design choice.
Detailed Solution
Phase 1 (Offline)
Engineers set up a pipeline that collects user click logs in a data lake (such as Hadoop). A two-tower NLP-based deep learning model is trained using item textual data and user click sequences. One tower encodes item text into an item embedding. The other tower encodes recent user browsing activity into a user embedding.
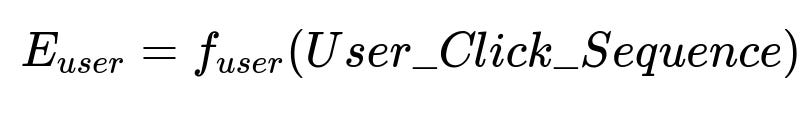
This formula shows how the user embedding is computed from a function of the user's click history. The click sequence is a chronological list of items viewed by the user. The deep learning model processes textual metadata or IDs of these items, producing a single embedding that represents that user's interests.
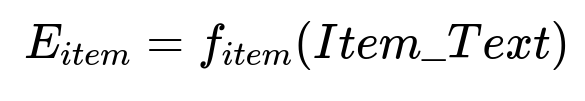
This formula shows how each item's embedding is computed from its textual metadata. The textual input includes title, description, or other relevant attributes. The deep learning tower transforms this data into a single dense vector.
Engineers generate the user embeddings and item embeddings offline. They perform a KNN search (using a library like FAISS) to match each user embedding to its top items. They store the list of recommended items in a fast key-value store (such as Couchbase), keyed by user ID. When a user visits the site, the application backend fetches these recommendations from the cache and renders them.
This is a straightforward approach but has a lag of one or more days between the user’s new activity and updated recommendations.
Phase 2 (Offline / NRT Hybrid)
They introduce a real-time KNN service. Items are still embedded offline once a day. Users’ embeddings are also generated offline and cached, but the actual KNN retrieval is now executed at request time.
The system flow:
The model generates item embeddings daily and feeds them into an ANN index (for example, HNSW or ScaNN).
The offline pipeline writes user embeddings to a key-value store.
When a user visits the site, the backend fetches the user embedding from the cache, queries the ANN index to find top similar items, and renders them in real time.
This reduces delays in retrieval results but still depends on offline user embeddings. If a user exhibits new behavior, it might take a day to see updated user embeddings.
Phase 3 (NRT)
The final goal is fully near real-time embedding generation. Engineers deploy a streaming platform like Apache Kafka that captures user click events as they happen. An Apache Flink job aggregates a user’s last N clicks, then sends this sequence to a GPU-based inference service (possibly using Triton Inference Server) to generate a new user embedding in seconds. The newly generated user embedding is stored in the key-value store. The retrieval step is the same as Phase 2, but now the user embedding can reflect the latest user behavior almost instantly.
The system can also extend NRT generation to item embeddings when new items are listed. The newly computed item embeddings get indexed into the ANN service, ensuring fresh content availability.
Pros: The pipeline updates user embeddings in seconds. The user sees up-to-date recommendations. The system is fully real-time.
Cons: Building such a pipeline is more complex. Maintaining real-time streaming, GPU inference, and an always-updated index requires specialized infrastructure.
Example Code Snippet
Below is an example PyTorch snippet for generating user embeddings given a batch of item IDs or textual features. Explanations follow in plain text.
import torch
import torch.nn as nn
class UserTower(nn.Module):
def __init__(self, vocab_size, embed_dim):
super(UserTower, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.fc = nn.Linear(embed_dim, embed_dim)
def forward(self, item_ids):
x = self.embedding(item_ids).mean(dim=1)
x = self.fc(x)
x = torch.relu(x)
return x
# Example usage:
# Suppose user_clicks is a [batch_size, sequence_len] tensor of item IDs
model = UserTower(vocab_size=50000, embed_dim=128)
user_embs = model(user_clicks)
user_embs is now a [batch_size, 128] tensor of user embeddings.
Implementation Details
An offline pipeline can run with Spark to group user data. The trained model can run on a GPU cluster for embedding generation. The KNN service can use an ANN library like FAISS, HNSW, or ScaNN. For near real-time upgrades, Kafka captures click events, a Flink job processes these events, and the inference service updates the user embedding. The item index is populated offline or incrementally. A high-throughput caching system serves the final recommendations at runtime. The front-end calls the caching system or the KNN service with minimal latency, typically a few milliseconds, to display recommended items.
Potential Follow-Up Questions
How do you ensure the two-tower model captures semantic similarity for text like “red dress” vs “scarlet dress”?
The model uses language-based embeddings and is trained on massive textual data so that synonyms or paraphrases in item text map to similar dense vectors. During training, positive examples (user clicked items) guide the model to place related text points closer in the embedding space. Negative sampling ensures unrelated items stay farther apart.
Hyperparameters like embedding size and training epochs influence how well the model discerns nuanced synonyms. Larger embedding dimensions capture finer-grain relationships, but they demand more computational resources. Text tokenization and subword vocabularies help the model handle rare words. Regular evaluation on a validation set compares synonyms or related items to tune these parameters further.
How do you handle multi-lingual or locale-specific text in item listings?
You incorporate language IDs or embeddings from a pre-trained multilingual transformer at the input stage. The model can condition on the locale ID or embed each token with a language-specific approach. You unify these signals in the same embedding space or maintain separate embeddings per language dimension. You evaluate the accuracy across different locales, ensuring that items in each language cluster sensibly. If needed, you do language segmentation or train multiple models specialized by region, combining results in the retrieval system.
How do you scale real-time inference for millions of concurrent users?
You load-balance requests across multiple GPU or CPU nodes running the inference service. You deploy model replicas in a containerized environment with an orchestration platform. Each replica has a dedicated GPU or uses a multi-GPU setup. You shard the user IDs or use a round-robin approach to distribute inference requests. Horizontal scaling allows more replicas to handle higher request volumes. You track performance metrics (throughput, latency) and autoscale as traffic fluctuates.
You also consider optimizing the model. This can involve Torchscript or ONNX format for lower overhead. Techniques like TensorRT further reduce inference latency. You maintain a GPU memory budget for each replica to avoid out-of-memory errors when user or item embeddings are large.
How do you validate or measure the quality of recommendations in production?
You track metrics like click-through rate, conversion rate, or purchase rate. You run A/B tests to compare new versions against a baseline. You also measure user engagement metrics such as time on page or bounce rate. A portion of traffic sees the new embedding or retrieval approach, and you collect user feedback. If the new system significantly improves your chosen KPIs, you roll it out to more users. If it regresses, you revert to the previous stable version or adjust hyperparameters.
You can also do offline validation by comparing known user purchase history against predicted recommendations. You measure recall or NDCG at different ranks. You analyze coverage to ensure the system does not repeatedly push a narrow subset of items.
How do you address potential cold-start problems for new users with no browsing history?
You leverage defaults such as trending or popular items for a brand-new user. You then refine recommendations as soon as they start clicking items. You can also incorporate user demographics or referrer data to generate a partial embedding. If the user logs in from certain channels or shows preferences for categories, you condition the user tower on those signals. You retrain or fine-tune the two-tower model to handle short click sequences, so any single click can produce a rough user embedding. You can also backfill partial user signals from other internal data sources if available.
How do you manage index updates for new items in near real-time?
You maintain a streaming pipeline that monitors newly listed items. When new items arrive, they get embedded by the item tower in near real-time. You insert these new embeddings into the ANN index incrementally. Modern index libraries allow partial or dynamic insertions without rebuilding from scratch. If the volume of newly listed items is too high, you batch them in short intervals. You replicate the updated index across multiple query nodes to ensure consistency. If an item gets unlisted, you remove or mark it inactive in the index to avoid irrelevant results.
How do you keep latency low while dealing with 1.5 billion item embeddings?
You adopt approximate search with HNSW or ScaNN. You tune the index parameters so that queries strike a balance between recall and latency. You store embeddings on memory-optimized nodes or use an SSD cache layer if needed. You adopt distributed indexing where you shard items by category or random partition. Each query only needs to search one shard or a small subset of shards. You profile end-to-end pipeline latencies with load tests and fine-tune concurrency limits, query depth, and re-ranking steps.
How do you prevent the system from generating stale recommendations?
You combine streaming user embeddings with frequent updates of new or changed items in the index. Each time a user clicks an item, the system updates the user embedding. Each time an item changes or is created, you refresh its embedding. You keep a small time-to-live for the user’s cached embedding if the user remains active. The architecture ensures continuous refresh of data, minimizing staleness. You also adopt fallback logic to handle any mismatch in item availability or user sessions.
Conclusion
A deep learning based retrieval system for real-time personalized recommendations relies on robust data pipelines, efficient model architectures, scalable GPU inference, and an ANN engine. You start with an offline pipeline that pre-computes recommendations, move to real-time ANN retrieval, and finally adopt a streaming approach for NRT embedding generation. Each step enhances freshness and relevance for the user, yet requires more complex infrastructure.
All components must integrate seamlessly with minimal latency and high availability. The final system can handle massive traffic and deliver user-specific item recommendations in seconds.