
ML Case-study Interview Question: Optimizing Cross-Channel Marketing Spend Using Reinforcement Learning and Uplift Modeling


Browse all the ML Case-Studies here.
Case-Study question
A large online retailer manages many ads across social media, search, email, push notifications, and direct mail. They want to optimize marketing spend, improve ad effectiveness, and personalize messaging to the right audience. They have general-purpose models predicting purchase intent and channel-specific models for individual campaigns. They also experiment with uplift modeling to measure true incremental impact. They recently started developing a multi-layer system that uses reinforcement learning to balance “explore vs. exploit” actions across multiple channels. Propose a comprehensive plan to design, build, and maintain their marketing ML system. Include details on how you would approach data collection, training, model deployment, and long-term scaling. Suggest how to measure success, incorporate feedback loops, and integrate new business or industry changes. Describe what you would prioritize first if you were hired as a Senior Data Scientist.
Detailed Solution
General marketing ML systems aim to select relevant content, present it to the right audience, and manage budget constraints. A robust ecosystem usually has the following layers.
General Propensity Modeling
Many organizations first build a propensity modeling pipeline to identify users most likely to buy or engage. One common model is a binary classification system (for example, logistic regression) that outputs a conversion probability for each user. This approach leverages historical behavioral data (page views, past purchases, etc.) to predict future purchase likelihood.
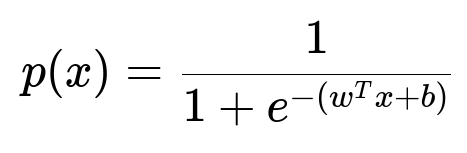
Here, p(x) is the probability of conversion for feature vector x. w is the weight vector learned from data. b is the bias term. The model can be extended with more sophisticated algorithms, such as gradient boosting or neural networks. The output is used to rank users by their likelihood to convert.
This solution is scalable because the same model output can be applied to many channels. Maintenance is also easier: a single pipeline calculates conversion probabilities and shares them with downstream campaigns. However, it can cause over-messaging if different channels all chase the same high-propensity audience. It also lacks explicit measurement of incremental impact.
Specialized Response and Uplift Modeling
Some channels need their own specialized models that predict a user’s response to a specific ad or measure true incremental lift. A channel-specific response model can handle unique data signals (for example, retargeting signals if someone left items in a cart). For deeper insights, an uplift model compares predicted outcomes under treatment vs. control.

P(conversion|treated) is the predicted conversion rate if an ad is shown. P(conversion|control) is the predicted rate if no ad is shown. This approach requires randomized tests for ground truth data. Each channel might run A/B tests to gather labeled outcomes (treated vs. control). This is expensive if done across many campaigns. Maintenance becomes harder because each channel gets its own model and experiment framework.
Multi-layer RL-based Platform
A multi-layer RL-based system maximizes overall marketing performance rather than focusing on single-channel metrics. One layer learns user-level embeddings or scores (as above). Another layer, typically a reinforcement learning module, assigns actions (which ad, which channel, how often) to each user. It adjusts decisions over time based on observed rewards (clicks, revenue, or long-term metrics).
A feedback layer also helps the RL system learn from delayed outcomes. The system might map short-term events (like clicks) into a forecast of longer-term revenue. This approach updates the treatment policy at regular intervals to keep pace with new conditions. It can handle multiple objectives, such as preventing ad fatigue or capping daily budget.
Practical Implementation Details
Data collection starts with pipelines that aggregate user behavior, ad impressions, conversions, and campaign costs. The data is stored in a centralized warehouse. Daily or weekly training jobs update general propensity models and specialized models. A separate process runs reinforcement learning training using the data feed of past actions and rewards.
Model deployment uses versioned artifacts. General propensity models get updated at intervals (monthly or quarterly). The RL optimization layer might refresh more frequently (daily or even hourly) if the system is built to handle real-time training. A strategic approach ensures that if the RL policy fails or data changes unexpectedly, a backup rule-based system can keep marketing running.
Long-term scaling involves automating experiment management. For uplift modeling, building robust pipelines for randomizing treatment and control is crucial. Data scientists track each user’s experimental condition to label outcomes accurately. This RCT framework ensures that any new channel or targeting strategy can integrate with uplift measurement.
Monitoring success requires tracking business KPIs over time: incremental revenue, return on ad spend, and engagement. Each channel feeds data into a central dashboard so the team can spot problems early and refine model parameters. If a channel’s strategy changes—like new creative or a shift in user privacy policies—the RL layer adjusts as soon as the reward signals show changes in user response.
Early priorities might include:
Ensuring consistent, high-quality data ingestion.
Implementing a stable pipeline for training and serving general propensity scores.
Setting up frameworks to run incremental tests and measure actual lift.
Deploying an RL-based optimization layer once consistent data streams and baseline models are stable.
What strategies would you adopt for validation and backtesting?
A robust validation strategy checks that the models deliver stable and accurate predictions. Historical backtesting can replicate how the model would have performed if it had been deployed during past time windows. It involves splitting data by time and ensuring that training data does not overlap with future events. Once the model is live, an online experiment—such as an A/B test at the campaign level—verifies whether predicted improvements translate into real outcomes.
Cross-validation on rolling time windows is often done for offline validation. Models should be retrained on older slices of data, then tested on the subsequent time segment. This reveals performance drift if user behavior changes or seasonality appears. After offline testing, real-world A/B tests confirm whether the uplift the model promises actually occurs. Such tests are especially critical for uplift modeling, where random treatment assignment is required to measure genuine incremental impacts.
How would you address over-messaging and campaign cannibalization?
Over-messaging occurs when multiple campaigns target the same group too often, causing annoyance and diminishing returns. An RL-based approach can incorporate penalty terms in its reward function to reduce repeated impressions on the same user. Alternatively, it can cap the maximum number of impressions per user within a time window.
A centralized coordinator can track each user’s total impression count and enforce global frequency constraints. If two channels both plan to send messages to a user in the same day, the coordinator can let only the highest expected-value campaign proceed. This logic can be part of the decision optimization layer. If a user is at high risk of unsubscribing or ignoring ads, the system can pause or reduce the marketing frequency.
Why is uplift modeling more expensive to maintain than propensity modeling?
Uplift modeling requires continuous randomization for building labeled datasets. For every wave of marketing, a subset of users must be held out to receive no treatment. This ensures that the uplift model learns the counterfactual: what would have happened without exposure. Such holdouts can result in opportunity costs because some users will not see a potentially profitable ad. The process also demands extra tracking to mark who is in treatment vs. control, then measure the outcome differences.
Propensity modeling, on the other hand, uses observational data with no special experimental design. It is cheaper to scale, but it cannot directly quantify incremental impact since it lacks a true untreated control group. Uplift modeling is more accurate for measuring net gain, but it is more costly and complex to maintain.
How would you design the reinforcement learning system for real-time adjustment?
A reinforcement learning agent collects user and ad features, runs an action selection policy (which ad or channel to show), and observes a reward signal (click, purchase, or longer-term KPI). A typical architecture uses an online learning loop with the following steps:
For each user impression opportunity, the system scores actions based on the current policy.
It logs the chosen action, the user’s context, and the immediate or short-term outcome.
A separate process periodically updates model parameters using batch data from the logged interactions.
The new policy is deployed to production.
To handle delayed rewards such as conversions that happen hours or days later, a forward-looking forecast can estimate partial rewards from immediate signals (clicks, site visits). A longer training window accounts for conversions that arrive after some delay. If the environment changes frequently (new products, marketing constraints), the system retrains more often. Thorough monitoring flags any policy drift or performance shortfall.
How would you measure the system’s overall success?
Return on Ad Spend (ROAS) and incremental revenue are primary metrics. One approach is to run a global holdout group that does not receive these advanced model-driven treatments. The difference in cumulative revenue and profit between the treatment group and the holdout group shows the net benefit. Another approach is to track user-level metrics such as sign-up rates, average revenue per user, or retention, especially if the business cares about long-term relationships. If overall performance lifts without damaging user experience, the system is succeeding.
Technical stability also matters. Monitoring the number of model crashes, data pipeline failures, or unusual CPU/memory usage can help ensure the system is robust. If the system remains stable under traffic spikes, that is a strong sign of readiness for more channels.
How do you handle privacy or industry changes?
Privacy regulations or shifts in ad-tech (for example, less access to certain user identifiers) can disrupt features used for targeting. A robust pipeline must adapt by limiting PII usage, anonymizing data, and relying on aggregated signals. If an identifier becomes unavailable, feature engineering may refocus on contextual or first-party site data. The RL system can rely more on aggregated performance signals. Frequent retraining helps recalibrate decisions when data distributions shift.
Models can also incorporate synthetic or privacy-preserving signals: for instance, summary-level statistics for a user segment instead of detailed user-level data. If the system is well modularized, removing or replacing certain features does not break the entire pipeline. Documentation and monitoring are critical. As soon as performance drops or data coverage changes, the team can retrain or refactor.