
ML Case-study Interview Question: Scalable Multi-Stage Ranking for Personalized Delivery Marketing Recommendations


Case-Study question
A large tech-based company runs food and retail delivery. They send marketing messages to users via email, push notifications, and SMS. They want to personalize the recommended stores and restaurants in these messages. These recommendations lack immediate user context and must also align with each marketing campaign’s theme. The company handles billions of such messages across many regions. How would you build a scalable, cost-efficient system to address these challenges?
Use the following assumptions:
Users can only order from nearby merchants.
Users may view these recommendations much later.
Different campaigns have unique thematic needs.
Infrastructure costs must be carefully managed.
The company wants a multi-stage pipeline to retrieve, blend, and rank candidates.
Propose a design for each step of the pipeline, including how to handle missing user context, how to incorporate campaign-specific content, and how to manage high throughput and cost constraints.
Detailed Solution
Overview of the Multi-Stage System
The system has three main parts. First, it retrieves a list of candidate items. Next, it filters and blends them based on rules. Finally, it applies a second pass ranking with more advanced signals.
Candidate Retrieval
The system starts with a broad set of potential merchants for each user. It uses the company’s knowledge graph to find relevant merchants based on user location or predicted location. It tries to guess where a user is most likely to order next. When someone often orders from home, the system infers the home neighborhood. If a user recently requested a ride to an airport, the system overrides the default neighborhood with the airport region.
Candidate generation merges high-frequency signals (recent orders, user history) with low-frequency signals (past location or ride data). A lightweight model outputs the likely region for the user’s next order. That region’s merchants form the candidate set. This approach helps frequent and infrequent users, as it uses minimal features to maintain scale. For traveling users, an event-based override corrects the region if they show recent behavioral changes.
First-Pass Ranking
The first-pass ranking filters invalid or out-of-range merchants. It also assigns a fast linear score based on limited features, like user-merchant interaction frequency or merchant promotions. This step keeps costs low by avoiding complex operations on the entire candidate pool.
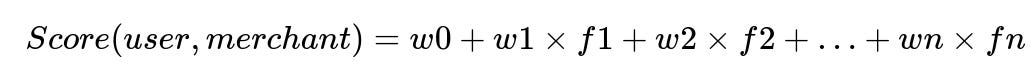
Where:
Score(user, merchant) is a simple linear combination of features.
f1, f2, ..., fn represent features such as user history with the merchant, promotion indicators, or popularity signals.
w0, w1, ..., wn are the model weights learned or tuned to optimize recall.
Only the top-scoring merchants survive to the next stage, which saves bandwidth for subsequent expensive processing.
Second-Pass Ranking
This stage applies a more complex learning-to-rank framework. It uses user-centric features such as:
Past ordering behavior.
Cuisine preferences, stored in a feature store updated regularly.
User engagement across past out-of-app messages.
The system merges these signals into a ranking model that scores each merchant’s relevance. For users with little data, it relies on older or aggregated signals to keep recommendations relevant. The platform also uses a cuisine embedding to cluster similar cuisines, so users can discover new choices while staying close to their preferences.
When building the cuisine similarity matrix, the system checks which cuisines co-occur frequently in the same merchant. A spectral clustering on this matrix groups cuisines into natural clusters. The resulting clusters power a smoothed user preference vector. This approach balances exploration with personalization, encouraging new restaurant choices without sacrificing relevance. It also reduces feature storage costs by collapsing many cuisines into fewer clusters.
Re-Ranking and Blending
After the second pass, a re-ranking layer enforces marketing rules. Different teams can amplify the visibility of certain merchants to align with campaign goals. For example, if a campaign highlights local favorites, the engine can upweight local brands. Configuration overrides allow local marketing teams to adjust parameters for specific cities or regions while inheriting defaults from larger regions.
Managing Costs
Storage and real-time computation scale with billions of messages. The pipeline addresses cost concerns by:
Using minimal feature sets in the first-pass ranker.
Caching or compressing features wherever possible (e.g., cuisine embeddings).
Overriding the user’s location context only when necessary to avoid unnecessary complex calls.
Employing auto-scaling infrastructure to handle peak loads.
Below is a simplified code snippet illustrating how the system might rank candidates after retrieval:
# Suppose candidate_merchants is the filtered merchant list from the first-pass ranking.
# user_features is a dictionary of user signals (e.g. cuisine_preferences, past_order_count).
# model is a pre-loaded ranking model.
def second_pass_rank(candidate_merchants, user_features):
# Transform user_features into model input
x_user = prepare_user_features(user_features)
ranked_candidates = []
for merchant in candidate_merchants:
merchant_features = extract_merchant_features(merchant)
combined_features = combine_features(x_user, merchant_features)
score = model.predict(combined_features)
ranked_candidates.append((merchant, score))
# Sort candidates by descending score
ranked_candidates.sort(key=lambda x: x[1], reverse=True)
return [merchant for merchant, _ in ranked_candidates]
This snippet shows a second-pass approach where the system enriches each candidate with user features, runs a model prediction, and sorts by score.
Extending to Other Business Lines
Though much of the system focuses on merchant recommendations, the platform can be extended to rides, travel, or other services. The key steps remain the same. For each new line of business, the system integrates domain-specific features and content while reusing the core pipeline.
Further Follow-Up Questions
How do you handle new or churned users with minimal data?
Rely on long-dated order records if available. If still lacking data, default to popular merchants or use aggregated signals from similar user segments. Keep the feature sets lightweight. Whenever a new user’s behavior emerges, incorporate it with daily or near real-time updates in the feature store.
How do you ensure campaign consistency?
Allow each campaign owner to specify certain business rules. The blending layer overrides part of the final ranking to fit the campaign’s theme or objective. Use hierarchical configuration to apply broad rules at a national level while permitting local teams to refine for their region.
How do you measure success and optimize the solution?
Track metrics like click-through rate, conversion rate, and order frequency. Run A/B tests on subsets of users to compare different ranking or blending strategies. Evaluate performance across various user cohorts, ensuring no single user segment is disadvantaged. Monitor system costs, especially around feature store access and real-time scoring. If costs rise, simplify features or reconsider when real-time scoring is used.
How do you maintain system reliability under high throughput?
Automate scaling policies for core services. When message volume spikes, provision extra instances for the ranking service and feature store. Batch or cache frequently accessed features, and degrade gracefully if the system is overloaded. In the worst case, revert to an offline-generated fallback list of merchants to avoid downtime.
How would you incorporate non-restaurant items or new business lines?
Define domain-specific features. For groceries or other retail, highlight relevant properties like delivery speed or product variety. For rides, consider pick-up frequency or user travel patterns. Extend the same multi-stage pipeline with specialized candidate retrieval and domain-specific ranking signals. Maintain the blending rules for each line of business and unify them in a single system that scales seamlessly.