
ML Case-study Interview Question: Neural Network-Powered Subfolder Suggestions with Human-in-the-Loop Control


Browse all the ML Case-Studies here.
Case-Study question
A large-scale file-hosting platform noticed that manual organization of large volumes of files is time-consuming for users, especially team administrators responsible for folder cleanups. The company wants a machine learning system that can suggest subfolders for each new file placed into a broader parent folder. They want an intuitive human-in-the-loop approach, where the system suggests best-fit subfolders and the user can accept, modify, or reject these suggestions. They also want to ensure reasonable latency and privacy safeguards.
Consider you are leading the Senior Data Scientist team. How would you design an end-to-end solution? Outline your data strategy, model architecture, evaluation metrics, privacy protections, and deployment approach. Address potential hurdles, such as personalized file naming conventions, dealing with sensitive filenames, ensuring low latency, and allowing full user control in final decisions.
Detailed Solution
Understanding user behavior and forming hypotheses
Teams typically have diverse organization styles. Some prefer organizing by theme, while others focus on workflows or source of content. This implies that a generic model must handle multiple strategies without forcing a single rigid approach. The system should collect examples of already well-organized folders, treating them as labeled data for how future recommendations should look.
Building a labeled dataset
Engineers can infer “correct” file-to-subfolder mappings from folders that appear organized. Training data pairs (file, subfolder) become positive examples when a file belongs in that subfolder. All other subfolders in the same parent folder become negative examples. Sensitive filenames or folder names should remain protected. One strategy is to rely on a secured sandbox of allowed data that only a small, approved team can access for development.
Two modeling approaches
The first baseline is a similarity heuristic. Compute string or token-based matches between the file name and candidate folder names or sibling file names. The second approach is a neural network that encodes names into vector spaces and scores each (file, folder) pair.
Key formula for ranking candidate subfolders
Below is a simple conceptual representation of the scoring function in plain text. This formula outputs a single numeric score used to rank subfolders for each file.
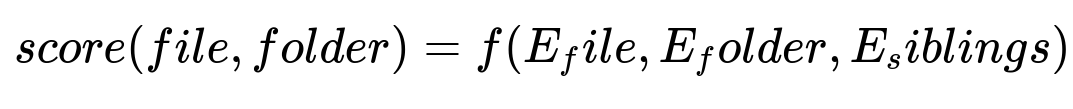
Here:
E_file is the encoded representation of the file's name.
E_folder is the encoded representation of the candidate folder’s name.
E_siblings is an aggregate representation of the names in that folder, since those can reveal strong clues about that folder’s contents.
f is a function that can be implemented by a small neural network. The network might do pairwise or triplet comparisons among file, folder, and siblings. A higher score indicates a stronger likelihood that file belongs in that folder.
Model architecture
A simple neural network with fewer than 20 hidden layers can map embeddings of file and folder tokens to a single prediction. A final sigmoid or softmax layer can classify if the match is correct or not. The highest-scoring candidate becomes the top recommendation. Additional thresholds split recommendations into high, medium, or low confidence.
Privacy constraints
Ensure no raw filenames are accessible by unauthorized personnel. Use a secure pipeline that either anonymizes text or grants temporary access to sanitized tokens. Store only hashed or obfuscated tokens when possible. Restrict developer access, log usage, and periodically purge data.
Deployment and latency
Trigger the model at the moment a user attempts to organize files. Maintain performance by caching embeddings or applying approximate nearest neighbor queries. Tuning embeddings and controlling model size help achieve low inference latency.
Example code snippet (simplified Python)
import torch
import torch.nn as nn
class FileFolderScorer(nn.Module):
def __init__(self, embed_dim, hidden_dim):
super(FileFolderScorer, self).__init__()
self.fc1 = nn.Linear(embed_dim * 3, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, 1)
self.sig = nn.Sigmoid()
def forward(self, file_embed, folder_embed, siblings_embed):
combined = torch.cat([file_embed, folder_embed, siblings_embed], dim=-1)
x = self.fc1(combined)
x = torch.relu(x)
x = self.fc2(x)
score = self.sig(x)
return score
# Suppose we already have embeddings for file, folder, and siblings
# For a single (file, folder) candidate pair, forward pass might look like this:
model = FileFolderScorer(embed_dim=128, hidden_dim=64)
file_vec = torch.rand(1, 128)
folder_vec = torch.rand(1, 128)
siblings_vec = torch.rand(1, 128)
prediction_score = model(file_vec, folder_vec, siblings_vec)
print(prediction_score.item())
This example demonstrates a simplified forward pass. The final prediction_score can be used to rank candidate folders.
Human-in-the-loop solution
The product presents suggestions for all files in a chosen folder. High-confidence mappings are highlighted, while medium-confidence suggestions are displayed as optional moves. The user can accept or override any recommendation. Their final actions can be logged as new data, improving future model iterations.
Results and improvements
Heuristic methods may sometimes give higher acceptance rates in scenarios with simple patterns. Neural network methods are more adaptive in other contexts. Incorporating user feedback into iterative retraining often boosts performance and user trust over time.
Follow-up question 1
How would you handle multilingual filenames or folders if some are in English, others in different languages?
Detailed answer
Use multilingual tokenization or subword segmentation. Train embeddings on multi-language corpora or leverage open-source multilingual encoders. The model must not rely on only English-based token frequencies. At inference, the same pipeline encodes text from any language. If new languages appear, retraining or fine-tuning might be needed to maintain accuracy.
Follow-up question 2
How do you ensure the model can handle massive folders with thousands of files, while keeping latency low?
Detailed answer
Precompute folder and file embeddings. Store them in a quick lookup system. When a user initiates the organization workflow, retrieve embeddings rather than recomputing them. Use approximate nearest neighbor techniques or indexing to reduce comparisons when scoring subfolder candidates. Maintain minimal overhead by batching predictions. Profile the pipeline at scale and optimize memory usage or model size where needed.
Follow-up question 3
How do you measure success for this system beyond raw accuracy metrics?
Detailed answer
Track the acceptance rate of suggestions. Compare how many moves were auto-suggested vs manually done. Observe time saved in organizing files, measured by user event logs. Collect user feedback on suggestion relevance or perceived correctness. Monitor longitudinal changes in folder structure to see if suggestions reduce organizational drift or messiness over time.
Follow-up question 4
How would you handle privacy and compliance when dealing with potentially sensitive filenames?
Detailed answer
Restrict raw data handling to approved team members and secure systems. Apply hashing or tokenization so original text is masked. Implement ephemeral data retention for training sets. Keep logs and audits of any data access. Ensure compliance with regulations through frequent reviews and validations. Use minimal data needed to maintain model performance.
Follow-up question 5
If you observe that heuristic-based suggestions outperform your neural network in user acceptance tests, how might you respond?
Detailed answer
Investigate training data and any mismatch between your labeled examples and real usage patterns. Evaluate if the model is overfitting to a narrow set of users or folder types. Expand or rebalance the training set. Adjust how you handle file extensions or synonyms. Implement interpretability methods to show users why the model suggests a folder. Fine-tune or re-architect the model if simpler heuristics capture the practical cases better.