
ML Case-study Interview Question: Capturing Evolving Styles: Sequential Fashion Recommendations with Transformers


Case-Study question
A global fashion retailer wants to upgrade their product recommendations. They have a catalog of about 50,000 items, with hundreds of new products added every week. They already serve billions of recommendation requests daily. Their current system ranks products based on a matrix factorization approach that treats every previous customer interaction equally, regardless of how recently or frequently it occurred. They want a new system that better captures evolving styles and context. They heard about using transformer-based models with self-attention and positional awareness to build richer representations of customer interactions. How would you design, train, and deploy such a system to improve ranking quality and scale to billions of requests? How would you evaluate success?
Provide a step-by-step plan detailing your design choices and your approach to training data, model architecture, real-time serving, and model updates. Explain how you would handle performance optimization. Finally, propose how you would monitor and measure the system’s effectiveness both offline and online.
Detailed solution
Background
The global fashion retailer has a huge, rapidly changing catalog. Traditional matrix factorization methods capture user-item interactions in a latent space but do not explicitly model how customer interests shift over time or how different products relate to each other in context. A transformer-based recommender harnesses self-attention to extract these nuances by weighing the importance of each item in the customer’s history and introducing positional encodings to reflect the chronological order of interactions.
Matrix factorization
Matrix factorization often models user preference for item i as the dot product of learned embedding vectors. It predicts something like:
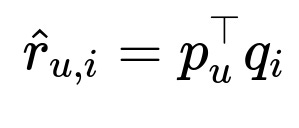
Here p_u is the user embedding. q_i is the item embedding. The model infers a preference score. This approach scales well but struggles with complex context shifts or style nuances when interactions occur at different times.
Transformer-based model
Transformers use self-attention. One important concept is the scaled dot-product attention formula:
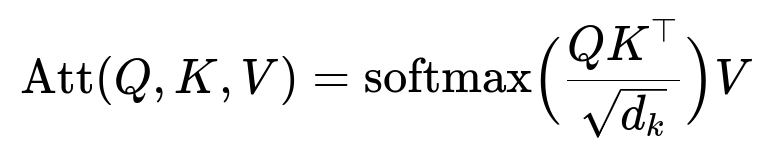
Q (queries), K (keys), and V (values) come from embedded representations of the sequence of items a customer interacted with. d_k is the dimension of the keys. This mechanism learns how each item in a sequence relates to others, making it excellent at detecting patterns of style when items are grouped together.
Positional encodings let the model track item order. This is crucial for distinguishing recent items from older ones and learning how a customer’s interests evolve over time or shift abruptly.
Training data
The retailer collects interaction data such as clicks, purchases, and adds-to-cart. Each user has a chronological sequence of item interactions. A small fraction of the data is set aside for validation and test. Each sequence is truncated or padded to a fixed length so that training is consistent. The label can be the next item clicked or purchased.
Transformers4Rec is a framework that extends standard transformer ideas to recommendations. It includes ready-made modules to handle typical user-item data, making it easier to train and deploy a transformer-based recommender at scale.
Model architecture
The input layer embeds each item as a vector. That vector is combined with positional encodings. Multi-head self-attention layers compute the relationships between items, capturing short-term context switching and longer-term style shifts. The final layer outputs probabilities over candidate items. At training time, it is often formulated as a next-item prediction task.
Real-time serving
A high-traffic system must update user context frequently. One approach is to maintain an up-to-date embedding or hidden state after every item interaction. In practice, the model can be periodically retrained on recent data. Inference might be served through a specialized GPU cluster or a high-performance CPU environment that caches user sequences and updates them with new interactions. The retailer’s large volume of daily requests demands careful optimization, including batching and efficient data pipelines.
Performance optimization
Transformers can be large. Techniques like mixed-precision training, gradient checkpointing, and distributed training help with speed. Serving needs optimized frameworks (such as TensorRT or TorchScript) for low-latency inference. Transformers4Rec integrates with these tools.
Offline and online evaluation
Offline, the team trains on historical data and measures top-k retrieval metrics or ranking metrics like Normalized Discounted Cumulative Gain (NDCG) or Recall@k on a test split. A successful transformer-based model often shows a significant improvement (such as 20% or more) over matrix factorization on these offline metrics.
Online, they run A/B tests, comparing user engagement, click-through rates, add-to-cart, and conversion metrics. They also measure latency to ensure the system can handle billions of daily requests.
Code snippet example
Below is a basic conceptual snippet for training with Transformers4Rec in Python. This is not full production code but shows a training workflow.
import torch
from transformers4rec import torch as t4r
# Example dataset creation
train_dataset = t4r.data.SequenceDataset(...)
# Define model
transformer_config = t4r.config.TransformerConfig(
d_model=64, n_head=4, n_layer=4,
max_seq_length=50, # example values
output_layer='next-item'
)
model = t4r.models.SequentialTransformer(transformer_config)
# Training loop
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
loss_fn = torch.nn.CrossEntropyLoss()
model.train()
for epoch in range(epochs):
for batch in train_dataset:
inputs, targets = batch['sequence'], batch['labels']
outputs = model(inputs)
loss = loss_fn(outputs, targets)
loss.backward()
optimizer.step()
optimizer.zero_grad()
The code loads sequences of item interactions, applies a transformer model, and computes next-item predictions for training.
Follow-up Question 1
How do you handle extremely long user histories if some customers have been active for many years and have thousands of interactions?
Answer
Sliding window approaches on sequences help. You split the user’s interaction history into manageable segments of recent items. Recent interactions are the most relevant signals for the model. Very old interactions often carry less weight. The transformer can also sample from different points in the sequence, but in production it is more common to focus on recent segments. If the user re-engages with older styles, the new sequence will reflect the items they just revisited. An alternative is to store a compressed representation of older segments. This keeps the final input length under a safe threshold for performance and memory constraints.
Follow-up Question 2
How do you represent users who are brand-new and have no or minimal interaction data?
Answer
Cold-start users can be approached by combining session-level signals with fallback logic. The system can use item similarity from popular items or apply contextual data such as geolocation, device type, or time of day. Another approach is to prompt early user interactions (like clicking on a few preferences) and then fine-tune the user embedding with those signals. Transformers can also handle session-based recommendations by encoding short session sequences. As more interactions come in, the user profile becomes richer, allowing more personalized results.
Follow-up Question 3
How do you justify the added complexity of transformers over simpler models?
Answer
Transformers require more memory and compute. They provide improved representations by capturing complex relationships. The offline gain often exceeds 20% in key ranking metrics. The online A/B tests usually show higher engagement or conversion. This translates to revenue gains and better user satisfaction. If the improvement is large enough to offset the extra compute and engineering cost, it is worth the effort. The decision also depends on infrastructure readiness. The team must ensure the environment can handle the complexity of transformer inference at scale.
Follow-up Question 4
How do you prevent overfitting when many items in the catalog come and go quickly?
Answer
Regularization and careful training set creation help. Dropout layers in the transformer reduce overfitting. You can do frequent model retraining to adapt to new products. You can also augment training data by including scenarios where older items are removed or replaced by new arrivals. The system must keep track of relevant items in embeddings. If an item no longer exists, it is excluded from new recommendations. Products that appear only briefly but have significant interactions get recognized through frequent incremental retraining or fine-tuning steps.
Follow-up Question 5
How do you handle changes in user behavior caused by seasonal or trend-based shifts?
Answer
Positional encodings help the model spot style changes over time. The model pays more attention to recent items that reflect the current season or trend. Sudden shifts (e.g., holiday purchases) are captured by the sequential nature of the transformer. Frequent retraining or fine-tuning is used so the model quickly adapts to large-scale changes in customer behavior. A more elaborate approach would incorporate external signals such as season, local climate, or global trends, but the core principle remains the same: the model must see enough recent data that captures the new patterns.
Follow-up Question 6
What are the main pitfalls in real-world deployment?
Answer
Serving latency is critical. Transformers have higher computational cost than simpler models. Without careful optimization, customers might wait too long for recommendations. Distributed inference with GPU acceleration, caching partial computations, or pruning the model is often required. Data pipelines can also become bottlenecks. Handling missing or inconsistent data from user interactions is tricky, especially at scale. Thorough monitoring and alerting systems are needed to track anomalies, drift, or rollout failures. Careful testing ensures you do not degrade the shopping experience.
Follow-up Question 7
How would you tackle hyperparameter tuning and interpretability?
Answer
A systematic search (random, grid, or Bayesian) can test different hidden sizes, attention heads, learning rates, and dropout probabilities. Evaluation on a validation set with ranking metrics reveals which settings work best. Interpretability is harder. Tools like attention-weight visualization show which prior items the model considered most important. This is helpful to confirm it focuses on relevant parts of the user’s history. Engineers then have a way to explain recommendations to stakeholders who need insights on how the model personalizes product rankings.
Follow-up Question 8
What if we want to include more contextual signals, like time of day or device type?
Answer
They can be added as additional embeddings concatenated to item embeddings. Transformers can handle multi-modal inputs. For instance, each product in the sequence can be augmented with a vector indicating the user’s device or the time block (morning, afternoon). The self-attention mechanism then factors in not only the sequence of products but also the temporal or contextual signals. This allows the model to adapt recommendations if, for example, the user shops differently on weekends or uses a particular device at night.
Follow-up Question 9
Why not only rely on real-time collaborative filtering?
Answer
Pure collaborative filtering generally lacks explicit handling of sequence ordering. It cannot capture how a recent purchase changes a user’s preference or how an older style becomes irrelevant. If you only rely on similarity to users who interacted with the same item, you lose the fine-grained insight about session context or style evolution. Transformers incorporate both collaborative and sequential patterns, yielding better personalization and capturing frequent context shifts.
Follow-up Question 10
How do you confirm that the new system is an improvement from a business perspective?
Answer
You run an A/B test on a subset of traffic, comparing the new transformer-based system to the old matrix factorization approach. You watch key performance indicators: click-through rate, add-to-cart rate, and eventual order conversions. A strong positive lift is the best proof. You check short-term metrics (immediate conversions) and longer-term signals (repeat visits, user satisfaction) to confirm sustainable gains. If these are consistently higher, the new system justifies the additional complexity and infrastructure cost.