
ML Case-study Interview Question: Personalized Fitness with Real-Time ML Recommendations & Churn Prediction


Browse all the ML Case-Studies here.
Case-Study question
A large connected-fitness company offers interactive workout sessions on smart exercise equipment. They want to increase user engagement and retention by leveraging machine learning to personalize class recommendations, predict churn, and optimize user experiences in real time. As a Senior Data Scientist at a major tech firm, how would you design the end-to-end solution? Propose a detailed approach covering data ingestion, model development, recommendation strategies, real-time serving, and how you would handle key challenges such as cold-start users. Outline how you would assess impact on both user satisfaction and revenue.
Proposed Solution
This solution explains the core machine learning pipeline and technical approach without referencing any specific company. It focuses on recommendation models, churn prediction methods, engineering decisions, and implementation strategies.
Data Ingestion and Preprocessing
Data arrives from user workouts, live-streamed class attendance, user profiles, and historical engagement. Store data in a scalable data warehouse (e.g., distributed file system or cloud-based data store). Apply ETL jobs for cleaning, normalizing timestamps, and merging clickstream, device metrics, and subscription records into a unified schema.
Feature Engineering
Extract user-level features (e.g., average weekly workouts, workout duration, time of day preferences), class-level features (e.g., instructor popularity, difficulty rating, music style), and interaction features (e.g., total completed classes with a specific instructor). Create time-based windows to capture user behavior trends. Represent user and class relationships in a user-item matrix for further modeling.
Recommendation Model
Train a collaborative filtering model (e.g., matrix factorization) to capture latent user-item features. Matrix factorization aims to learn user embedding vectors u_i and item embedding vectors v_j so their dot product approximates the user’s affinity. Fine-tune hyperparameters with techniques such as cross-validation.
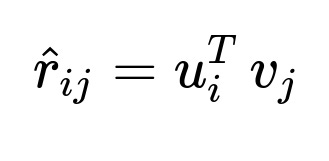
Where:
r_{ij} is the actual preference or rating of user i for class j in the training set.
u_i is the learned embedding vector for user i (contains latent factors that capture user interests).
v_j is the learned embedding vector for class j (contains latent factors describing class attributes).
hat{r}_{ij} is the predicted preference or rating for user i on class j.
Train with gradient-based optimization on a loss function that penalizes reconstruction error between actual and predicted ratings.
Churn Prediction
Model churn risk using logistic regression on user activity, engagement time, subscription duration, frequency of workouts, and new class trials. For user i, let x_i be the feature vector and w be the parameter vector.
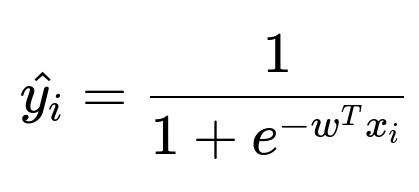
Where:
y_i is 1 if user i churns, 0 otherwise.
x_i contains churn-related predictors (usage frequency, subscription plan type, etc.).
w^T x_i is the linear combination of features.
hat{y_i} is the probability of churn.
Higher churn probability triggers targeted interventions like personalized class suggestions or promotional offers.
Real-Time Serving Architecture
Deploy model outputs to a low-latency service. Maintain a near-real-time pipeline that updates embeddings based on new interactions. Use a feature store for consistent data across training and serving. Retrieve user embedding, class embedding, and predicted churn in milliseconds, so the application can show relevant classes or offers on the user’s dashboard immediately.
Handling Cold-Start Users
Assign new users or classes a fallback embedding vector trained on population-level statistics. Update embedding vectors after a few interactions. Supplement collaborative filtering with content-based rules, such as recommended classes in the same category or intensity level that the user indicates in profile preferences.
Impact Measurement
Split users into treatment and control groups. Measure click-through rates on recommended classes, increase in workout frequency, churn reduction, and revenue uplift. Use A/B testing to confirm statistically significant improvement in user engagement.
Example Python Snippet
Below is a simplified training loop for a matrix factorization approach. This example uses random initialization and gradient descent.
import numpy as np
def train_matrix_factorization(R, k, alpha, epochs):
# R is user-item rating matrix
n_users, n_items = R.shape
U = np.random.normal(scale=1.0/k, size=(n_users, k))
V = np.random.normal(scale=1.0/k, size=(n_items, k))
for epoch in range(epochs):
for i in range(n_users):
for j in range(n_items):
if R[i, j] > 0:
error = R[i, j] - np.dot(U[i], V[j])
U[i] += alpha * error * V[j]
V[j] += alpha * error * U[i]
return U, V
This code starts with random embeddings for users (U) and items (V), then iteratively refines them based on observed ratings R. Production-grade systems would use more advanced libraries and incorporate parallelization.
How would you scale the recommendation system if the user base expands rapidly?
Online matrix factorization updates or approximate nearest-neighbor methods can keep up with large-scale data. Maintain a distributed architecture where user embeddings and item embeddings are stored on different nodes. Use partitioning strategies based on user IDs or item categories. For huge datasets, adopt sparse factorization methods that handle incomplete matrices.
How do you ensure model interpretability for stakeholders?
Provide partial dependence on key features. Surface metadata about why the model recommended certain classes (e.g., similarity to recently taken classes). For churn predictions, highlight which features drove the churn score up. Keep logs of top predictive features to demonstrate a transparent decision process.
How would you manage concept drift and ensure the model stays relevant?
Schedule model retraining or adopt streaming updates. If real-time activity indicates changing user behavior, refresh embeddings more frequently. Track distribution changes in features like workout preferences, time-of-day usage, or popularity of new instructors. Automate alerts that signal abnormal shifts and trigger a new training cycle.
How do you handle hyperparameter tuning?
Use grid or random search for hyperparameters like embedding dimension k, learning rate, and regularization parameters. Evaluate on a validation set or with cross-validation. Track metrics like root mean squared error for rating predictions, AUC for churn classification, and user engagement metrics for final selection.
How would you address re-ranking with business constraints?
Combine user relevance scores with strategic constraints (e.g., highlighting new classes, certain instructors, or promotional campaigns). Create a weighted objective that balances personalization with business goals. Monitor the effect of re-ranking on user satisfaction and adoption of targeted content.