
ML Case-study Interview Question: Multi-Stage Hybrid Course Recommendations: Blending Collaborative Filtering & Response Prediction


Browse all the ML Case-Studies here.
Case-Study question
A prominent online learning platform has millions of users and thousands of courses. The company wants to build a robust recommendation engine that shows relevant course suggestions to users. The system should handle new users with limited platform activity and returning users who have already interacted with many courses. The final solution should also provide a way to incorporate real-time context during user sessions. As a Senior Data Scientist, propose a complete design that includes model architectures, multi-stage pipelines, handling of user cold-start, blending of multiple models, and considerations for performance at scale.
Detailed In-Depth Solution
Offline and Online Architecture
The system uses offline computation to generate personalized recommendations. It stores these results in an online key-value system. When a request arrives, an online service fetches the stored recommendations and may supplement them with context-based suggestions. This approach reduces computation time at the moment of user interaction and lets the service deliver new relevant content if real-time signals (like recent page views) are available.
Response Prediction Model
This model predicts the probability of explicit engagement, such as clicks or bookmarks, by learning from user profile information (like skills and industry) and course attributes (like level or topic). It uses historical engagement data as the training label. Training typically involves large-scale feature engineering on user profiles, course metadata, and past interactions. New users have more available profile data than usage data, so this model handles them well and mitigates cold-start issues. It relies on both the user’s professional information and limited interaction signals, allowing the system to make predictions even when the user’s engagement history is sparse.
Collaborative Filtering Model
This model learns latent representations of users and courses. It predicts user-course relevance from these latent vectors. It focuses on implicit engagement (like watch activity). It is powerful for users who have already watched multiple courses.
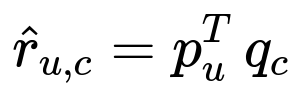
In this equation, p_u represents the embedding vector for user u, q_c represents the embedding vector for course c, and the dot product p_u^{T} q_c represents the estimated affinity between user u and course c based on shared latent factors. Collaborative filtering handles active users well but struggles with very new users and courses. It implicitly learns correlations from historical watch patterns, so it captures recent shifts in user interests and leverages similarities between courses that have shared audience segments.
Blending
The final set of recommendations emerges from blending predictions from Response Prediction and Collaborative Filtering. A controlled selection probability combines outputs from both models. This ensures that the system taps into both profile-driven insights (from Response Prediction) and behavior-driven similarities (from Collaborative Filtering). Blending addresses weaknesses of each model. It boosts coverage for new users by using profile-based scores and improves personalization for returning users by using latent factors.
Multi-Stage Model Pipeline
Data scientists run scheduled offline jobs to process raw interaction logs, extract features, train or update embedding vectors, and produce final ranked lists. The offline pipeline includes data cleaning, feature transformation, training, validation, and scoring. Blended recommendations are stored for quick retrieval. The online component delivers results in real time. It can use session context, such as the most recent course the user visited, to refine the ranking or filter out irrelevant items.
Scalability
The platform supports thousands of courses that continually grow. New courses appear each week, and the user population also grows. The system is designed for large-scale matrix factorization and efficient retrieval of predictions. The platform uses a consistent A/B testing framework for online experimentation. It measures metrics like click-through rates or course completion rates to confirm improvement in engagement and relevance.
Example Python Snippet
A typical Python code block for training a latent factor model can look like this:
user_embeddings = np.random.rand(num_users, embedding_dim)
course_embeddings = np.random.rand(num_courses, embedding_dim)
learning_rate = 0.01
for epoch in range(num_epochs):
for (user, course, rating) in training_data:
pred = np.dot(user_embeddings[user], course_embeddings[course])
error = rating - pred
user_embeddings[user] += learning_rate * error * course_embeddings[course]
course_embeddings[course] += learning_rate * error * user_embeddings[user]
It shows stochastic gradient descent updating user and course latent vectors. Real production systems use more advanced optimizers and robust data pipelines.
Follow-Up Question 1
How do you address the cold-start problem for new users and newly published courses?
The Response Prediction model relies on user profile features, which often exist even before the user has started interacting with courses. That circumvents the need for extensive watch history. For new courses, it uses descriptive metadata such as category or difficulty. Collaborative filtering struggles with new users or courses because it depends heavily on existing engagement signals. The blend ensures that if Collaborative Filtering cannot return a confident recommendation, the system still falls back on the profile-based score. Over time, as new users generate watch history, the Collaborative Filtering component improves as well.
Follow-Up Question 2
How would you improve real-time responsiveness if user preferences change quickly?
The platform stores offline recommendations in a key-value store and augments them with online logic that uses recent session context. If a user watches multiple advanced programming courses in the last session, the online layer re-ranks or filters results to reflect that updated interest. This partial re-ranking can be done by intercepting the final blended list and adjusting the score for courses matching recent context. It might also trigger micro-batches that update item embeddings in near real time, though that depends on system capacity.
Follow-Up Question 3
How do you evaluate the performance of these models and the final blended outcome?
Offline evaluation uses historical logs split into training and validation sets. Metrics include precision at top K, recall, and mean reciprocal rank. Online evaluation uses A/B testing on live traffic. A portion of users gets the new model’s recommendations, and another portion sees the baseline. The system monitors improvements in clicks, watch time, or completions. Statistical significance testing ensures reliable conclusions. Over time, the team monitors other engagement signals (course completion or skill development) to confirm long-term success.
Follow-Up Question 4
Which infrastructure decisions ensure scalability for millions of users and thousands of courses?
Batch pipelines run on distributed data processing frameworks. Matrix factorization jobs are parallelized. Latent factor updates for millions of users and items are sharded to multiple compute nodes. The final recommendation list is stored in a distributed key-value system that can serve high-throughput read requests at scale. Caching strategies reduce latency. For real-time data, the system may employ a streaming platform to capture and incorporate user interactions as they happen.
Follow-Up Question 5
How would you handle potential overfitting or bias in the Response Prediction model?
The modeling process uses regularization terms in the optimization step. Cross-validation ensures that the model does not simply memorize training data. Feature selection is guided by domain experts to avoid including features that might unintentionally bias recommendations. Calibration techniques verify that the predicted probabilities match true user behavior distributions. Periodic retraining captures changing platform usage patterns and mitigates drift over time.