
ML Case-study Interview Question: Adaptive Hybrid Retrieval Using Query Entropy for Enhanced E-commerce Search Relevance


Browse all the ML Case-Studies here.
Case-Study question
A large e-commerce platform needs to improve its product search relevance at scale. They maintain two separate retrieval systems for search: one uses text-based keyword matching through a traditional SQL store, and another uses embedding-based semantic search through a vector index. Currently, they retrieve a fixed number of results from each system and merge them, but they see issues with over-fetching, lower precision for certain queries, and inefficiency in retrieving documents that do not match user intent.
Their new approach introduces a way to measure the specificity of each query so they can adaptively choose how many items to retrieve from text-based retrieval and how many from embedding-based retrieval. They propose using a “query entropy” model to capture the likelihood distribution of relevant documents for each query. For example, highly specific queries have fewer relevant items, while generic queries have many. They use this metric to adapt their recall thresholds for text and embedding retrieval, so each query’s retrieval set size is determined by the query’s entropy score.
They then combine these adaptive results into a single recall set passed to the subsequent ranking steps. They are also testing hybrid retrieval approaches such as Reciprocal Rank Fusion and weighted combinations of text and semantic scores.
Design a solution that implements this adaptive recall strategy. Outline how you would calculate query entropy, how to set dynamic thresholds, and how you would integrate text-based retrieval with vector-based retrieval. Propose an architecture that uses this strategy efficiently in production. Provide all technical details and justifications. Then explain how you would measure success, address potential inefficiencies, and maintain reasonable latency.
Detailed Solution
The key to the adaptive recall strategy is measuring how many relevant documents are likely for each query, then using that measure to distribute the recall load between text retrieval and embedding-based retrieval.
Explain the reasoning step by step:
Text-based retrieval usually excels at matching exact keywords, but it struggles with queries that are vague or conceptually broader. Embedding-based retrieval captures semantic similarity but can over-fetch if not carefully calibrated. Combining them adaptively can yield higher precision.
Use query entropy as the metric for query specificity. Low entropy suggests fewer relevant items, so we rely more on precise text matches. High entropy suggests many possible matches, so semantic retrieval becomes more important.
In production, store item metadata and text-based indices in a relational database (like Postgres), and embedding representations in a vector store (like FAISS or pgvector). For each query:
Compute an entropy value that reflects whether the query is broad or specific.
Dynamically select how many items to fetch from each retrieval system.
Merge those items into a final recall set.
Pass that recall set to a downstream ranker that re-ranks the items for the final search results.
Below is the main equation for query entropy in big font:
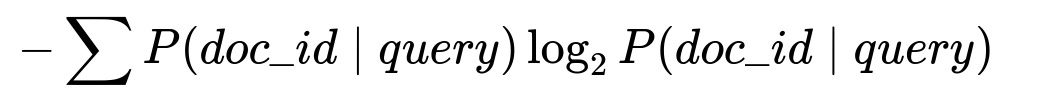
Where P(doc_id | query) is the probability of a particular document being relevant for the query, estimated by historical conversions or other engagement signals.
For each query, compute query_product_entropy. Then adapt the retrieval threshold for text (T) or embedding (E) retrieval using the formula:
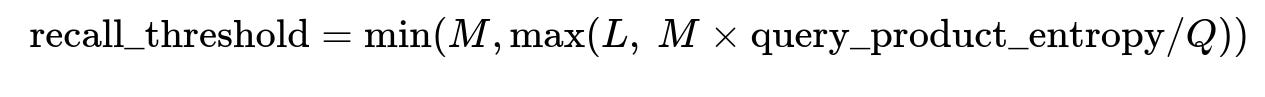
Where:
Lis the minimum number of products to recall.Mis the maximum number of products to recall.Qis a clipping factor for entropy to avoid extreme threshold inflation.query_product_entropyis the computed value from the formula above.
Configure text retrieval with a GIN or other suitable text-based index and a relevance ranking function (e.g. ts_rank). Configure embedding retrieval by generating query and product embeddings (for example, a small transformer-based encoder), storing the product embeddings in a vector index, and retrieving items by approximate nearest neighbor search.
When the user issues a query:
Calculate or lookup the query’s entropy.
Determine how many documents to retrieve from text-based retrieval and how many from embedding retrieval.
Perform both retrievals in parallel.
Merge the results.
Pass the merged set on to the re-ranker or final ranking stage.
This approach yields a dynamic recall strategy that is typically more relevant than statically picking a fixed retrieval count. It also helps reduce latency by avoiding unnecessary retrieval calls for queries with low entropy.
Support further improvement with a deeper hybrid approach that fuses the final scores from both text and embedding retrieval, such as:
Reciprocal Rank Fusion (RRF)
Weighted sum of lexical and semantic similarity scores
Example of Implementation Steps in Python
import numpy as np
def compute_entropy(doc_probabilities):
# doc_probabilities is a list of P(doc_id | query) values
return -np.sum([p * np.log2(p) for p in doc_probabilities if p > 0])
def get_recall_threshold(query_entropy, L=500, M=1000, Q=10):
clipped_entropy = min(query_entropy, Q)
threshold = M * clipped_entropy / Q
threshold = max(L, threshold)
threshold = min(M, threshold)
return int(threshold)
def text_retrieval(query, threshold):
# Code to run text-based retrieval, e.g. using Postgres
# Return top threshold items
return text_items
def embedding_retrieval(query_vector, threshold):
# Code to run ANN search on the vector store
# Return top threshold items
return embed_items
query = "example snacks"
# Suppose we have a pretrained model to compute doc probabilities and query_vector
doc_probabilities = [0.01, 0.02, 0.005, ...] # hypothetical
entropy_value = compute_entropy(doc_probabilities)
recall_threshold = get_recall_threshold(entropy_value)
text_items = text_retrieval(query, recall_threshold)
embed_items = embedding_retrieval(query, recall_threshold)
# Combine text_items and embed_items
final_recall_list = combine_results(text_items, embed_items)
# Then pass to the ranking layer
Measuring Success
Measure success by tracking:
Precision of top results.
Mean converting position or how far the user scrolls before a purchase.
Click-through rate and purchase rate.
Latency for retrieval calls and overall query handling.
An A/B experiment can confirm that dynamically adjusted recall thresholds increase user satisfaction and conversions.
Potential Inefficiencies
Storing large embeddings can be memory-intensive.
Real-time computation of entropy might add overhead. Many systems cache it for known queries.
Merging results from two sources can create network or operational latencies, so ensure parallel calls or asynchronous requests.
Overlapping items might appear in both sets. De-dupe them before ranking.
Maintaining Low Latency
Cache query entropy for frequent queries.
Use approximate nearest neighbor search for large embedding indexes.
Keep your text-based index well-optimized with proper indexing strategies.
Monitor the trade-off between recall threshold size and system overhead.
What if the training data for semantic embeddings is sparse?
Insufficient data might reduce the semantic model’s ability to generalize. Collect more training data or augment it with synthetic or data-augmentation approaches. Ensure domain coverage for different query types.
How do you handle extremely rare queries with almost no search history?
Use backoff strategies, such as relying more on text retrieval for unseen or rare queries. Also consider category-level historical data or semantic similarity with known queries to estimate an approximate entropy or default retrieval threshold.
How do you tune the weighted combination if you choose a score-fusion approach?
Train a small meta-learner on top of both retrieval signals. Use offline evaluation metrics (precision at K, nDCG) or run online experiments. Adjust weighting for each user segment or retailer context.
What if the query entropy calculation is inaccurate for new items?
Use fallback logic that assigns a default or average entropy for new items or new queries until enough data accumulates. If the system sees repeated misalignment for certain queries, adjust the default or build real-time feedback loops.
How do you decide your vector indexing solution?
Compare solutions like FAISS, pgvector, or external managed vector services on criteria like:
Ease of integration with your tech stack
Index build time and memory usage
Query latency at scale
Cost considerations for hosting large embeddings