
ML Case-study Interview Question: Personalized Accounting Suggestions via Vector Embeddings and ANN Search


Browse all the ML Case-Studies here.
Case-Study question
A technology organization wants to assist accountants by automatically suggesting transaction categories based on historical accounting data. They need a system that quickly finds similar transactions in massive datasets, accommodates subjective categorizations across different accountants, and returns accurate recommendations in real time. How would you design and implement such a system?
Detailed Solution
Overview
This system addresses inconsistent transaction categorizations among different accountants. Similarity-based machine learning converts transactions into vector embeddings that capture contextual relationships, then searches for nearest historical matches to suggest relevant categories.
Generating Vector Embeddings
A machine learning model must encode transaction details (vendor name, textual descriptions, contextual metadata) into fixed-size vector embeddings. These vectors should place semantically similar transactions close together. One effective approach uses a triplet loss framework, training the model with anchor, positive, and negative samples.
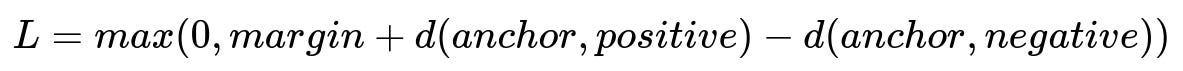
Where:
L is the triplet loss.
margin is a margin value enforcing a gap between positive and negative pairs.
d(anchor, positive) is the distance between the anchor and positive embeddings in plain text format d(a, p).
d(anchor, negative) is the distance between the anchor and negative embeddings in plain text format d(a, n).
In each training iteration, the model learns to pull positive samples closer to the anchor in vector space and push negative samples farther away. This process yields robust embedding representations that preserve semantic similarities (for example, seeing “Uber” and “Lyft” as closer vectors than “McDonald’s”).
Searching for Similar Transactions
When a new transaction arrives, the system encodes it into an embedding vector. Then it performs a nearest-neighbor search in a large vector database. Instead of brute force searches, it is practical to use approximate nearest neighbor (ANN) lookup. ANN indices such as Hierarchical Navigable Small World Graphs (HNSW) can add or remove embeddings while keeping the lookups efficient. Searching for top neighbors provides reference transactions with known categories.
Deriving Category Suggestions
The closest historical matches suggest possible categories. This approach handles the subjectivity of accountant preferences by adjusting what “positive” examples look like for each user or client. When an accountant reclassifies a transaction, that feedback can retrain or fine-tune the model, refining future suggestions.
Handling Real-Time and Batch Workloads
Use streaming pipelines to process transactions as soon as they arrive, generate embeddings, query the ANN index, and return fast results. Batch pipelines handle large-scale reprocessing to refresh or recalibrate the system. This combined strategy gives immediate suggestions while continuously improving the model in the background.
Practical Implementation Notes
A production deployment might run the model inference in a managed environment (for example, a cloud-based machine learning service) that scales during workload spikes. The ANN index can also be hosted in a managed vector store, which auto-scales to accommodate dataset growth. This setup gives quick, accurate category suggestions for millions of transactions.
Possible Follow-up Questions
1) How do you handle scenarios where two accountants categorize the same transaction differently?
The system stores each accountant’s classification as a valid label. When generating training triplets, the accountant’s own transaction data becomes the “positive” group, while transactions from other accountants become the “negative” group. This approach aligns the model with each user’s preferences. Over time, the embeddings capture the unique style of every accountant or client.
The system also returns multiple suggestions, ranked by similarity. Accountants see top options, choose the correct one, and that choice updates the historical data. On subsequent encounters with a similar transaction, the system reflects those updated preferences.
2) How do you select or tune the distance metric for comparing embeddings?
High-dimensional embeddings often rely on cosine distance because it focuses on the angle between vectors rather than their magnitudes. For similarity-based classification tasks (such as grouping text-like vendor names or descriptions), cosine distance typically gives robust results. Euclidean distance can be considered when embeddings are low-dimensional or the magnitude has a specific meaning in the domain. Empirical testing can confirm which metric works better, but cosine distance is a strong default for text-rich embeddings.
3) Why not use a direct classification model instead of a similarity-based approach?
A standard classification model would map each transaction to a single category. That approach assumes consistent labeling across all accountants. In reality, multiple accountants or clients often label the same type of transaction differently. A similarity-based approach avoids forcing a single universal label. It instead finds the most similar historical transactions for each accountant’s style. This system learns flexible embeddings that adapt to changing or subjective categorization preferences.
4) How would you incorporate new embeddings into a real-time pipeline without rebuilding the entire index?
HNSW-based approximate nearest neighbor solutions allow insertion or deletion of vectors at runtime. This means the system can add embeddings as new transactions arrive. Because the index can be updated incrementally, there is no need for full recomputation. The data pipeline encodes new transactions, sends their vectors to the index, and the index structure adapts in real time. Occasionally, a re-build may be performed for system-wide maintenance, but day-to-day usage only needs incremental updates.
5) How do you mitigate potential errors due to approximate nearest neighbor searches?
Approximate nearest neighbor methods sacrifice some accuracy for speed. Careful configuration of hyperparameters (for example, controlling how many candidate neighbors the algorithm scans) helps maintain adequate recall. Empirical testing with a holdout set ensures the recall is sufficient. If the system demands especially high precision, you can retrieve the top candidates from the approximate index and then do an exact distance check on that subset, boosting accuracy while still reaping most of the speed advantages.
6) How do you ensure the system remains unbiased or fair in its suggestions?
Regularly monitor the training data for systematic labeling biases. Use transparency tooling to see how often certain classifications appear. If an accountant’s preferences lead to skewed categorizations (for instance, always labeling certain vendors incorrectly), that becomes visible in the metrics. Incorporate feedback loops. If accountants manually correct the model’s suggestions, that correction quickly updates the embeddings or index. Frequent retraining with corrected labels helps the system stay unbiased relative to each user’s labeling standards.
7) How would you productionize this end-to-end?
Build the pipeline with modular steps:
Inference service for generating embeddings from raw input data.
Managed or self-hosted ANN service for fast vector queries.
Feedback integration for updating embeddings or index entries based on user corrections.
Streaming ingestion system for real-time inference and suggestions.
Batch pipelines for large-scale re-indexing or model re-training.
Each module scales independently. Logging, monitoring, and error-handling measure performance and highlight issues. This design supports smooth operation in a large enterprise setting.
8) What strategies would you use to optimize cost and performance at scale?
First, reduce embedding dimensionality through careful architecture design so the index stays compact. Second, tune index parameters (for example, the number of graph layers in HNSW) to balance speed and accuracy. Third, cache frequently queried vectors to reduce repeated computations. Fourth, autoscale computing resources in both streaming and batch pipelines. Fifth, track resource usage with performance dashboards to ensure you do not over-provision memory or compute capacity.
9) How would you extend this approach if new data sources (e.g., image receipts) are introduced?
Train a multi-modal embedding that combines textual transaction data with the extracted features from images, such as vendor logos or product line items. The core similarity-based principle remains the same, but the embeddings now encode both text and image features. The index search still queries nearest neighbors, but the vector encoding becomes more comprehensive, accommodating new data types seamlessly.
10) How do you maintain accuracy as more diverse transactions and vendors emerge?
Regularly retrain the embedding model on newly labeled data. Conduct periodic fine-tuning so the model adapts to emerging vendors and new user conventions. The approximate index must also update so embeddings remain representative of the latest transaction universe. Monitoring system accuracy and adjusting the pipeline’s parameters help maintain high-quality suggestions despite shifting data distributions.