
ML Case-study Interview Question: Predicting Call Reasons with Real-Time Contrastive Learning Embeddings from Click Events


Browse all the ML Case-Studies here.
Case-Study question
A rapidly growing financial institution has expanded from a single product to multiple products across different regions. They need to predict in real time why a customer is calling and then route the call to the correct specialist. They collect raw app click data through a flexible API, producing large volumes of semi-structured JSON events with inconsistent naming conventions and no centralized governance. They want to build a system that generates real-time embeddings from these events, then feed those embeddings into a downstream classification model to route incoming calls. How would you design a solution that addresses data ingestion, embeddings training, system architecture, low-latency storage, frequent retraining, and cost efficiency? Propose your end-to-end approach and explain your reasoning.
Detailed Solution
Overall Design
Each customer’s in-app events are transformed into a sequence of text-based tokens. The system extracts these events in real time, caches them briefly, computes embeddings, and passes them to a classification model that outputs the most probable reason for the call. This architecture supports multiple product lines and adapts quickly to evolving event structures.
Event Representation
An event consumer microservice receives click-stream data, strips infrequent attributes such as unique IDs, and stores tokenized representations. Larger windows can increase coverage but can also add noise if they include stale events. A balanced window (such as 3 hours) works well for capturing relevant behavior.
Contrastive Learning
The system learns embeddings with contrastive learning, using sets of customer events as anchor examples. One event is removed to form a positive sample, and randomly selected events from other customers become negatives. The aim is to push anchor and positive closer, while pushing anchor and negative apart.
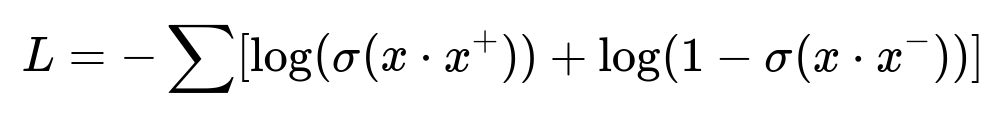
x is the anchor embedding. x^+ is a positive embedding from the same customer’s event set. x^- is a negative embedding from other customers’ event sets. sigma is the logistic function. The training minimizes L by maximizing x dot x^+ and minimizing x dot x^-.
After learning these symbol embeddings, the system sums or averages them to produce a single customer embedding vector.
Training Pipeline
A job pulls labeled data (customer calls and their eventual reasons). It looks up event tokens within a chosen time window prior to each call, computes embeddings, and joins them with the labels. The model then retrains at regular intervals. This process uses an automated pipeline so that whenever embeddings are updated, downstream tasks can trigger their own retraining.
Serving Pipeline
A microservice in Clojure receives raw events in near real time.
It normalizes and tokenizes these events.
It stores them in Redis with a short time-to-live (TTL), minimizing cost.
When a new call arrives, the classification model in Python fetches the relevant tokens, constructs the customer embedding, then produces a routing decision.
Low-Latency Storage
The high volume of events and frequent reads/writes can become expensive if stored in a fully managed key-value store with usage-based pricing. An in-memory database such as Redis cuts down cost for short-lived data while supporting fast lookups.
Frequent Retraining
Teams frequently modify the app’s flows. Consequently, event definitions can change. Continuous embedding retraining is necessary to keep the representation aligned with new event structures. A standardized pipeline simplifies updating all dependent models.
Benefits and Observations
The real-time embeddings reduce calls that require repeated transfers. They significantly improve coverage for newer products with fewer manually engineered features. They also achieve lower latency than calling multiple microservices at inference time. Development cycles are faster because teams reuse the same embeddings infrastructure for multiple models.
Follow-up Question 1: How would you address data drift in this system?
Data drift is inevitable when product flows change, or user behavior evolves. Frequent retraining and continuous monitoring are essential. Monitoring involves tracking embedding norms, distribution changes in tokens, and the classification model’s performance metrics. When detecting unexpected shifts or performance drops, the pipeline triggers early retraining and possibly a rollback to known stable embeddings or models.
Follow-up Question 2: How would you handle out-of-vocabulary or rare tokens?
The token dictionary would periodically refresh. Rare tokens are dropped or replaced with a fallback symbol. If a token was unknown at training time, the inference pipeline uses an embedding for an “unknown” symbol. During retraining, a threshold sets how frequently a token must appear to receive its own unique embedding.
Follow-up Question 3: Could you incorporate event ordering or time decay?
The current system uses bag-of-words embeddings that do not account for ordering. A sequence model such as a Recurrent Neural Network (RNN) or Transformer could preserve event order. Including time decay would weight recent events more heavily. Complexity would increase, but it might improve accuracy for time-sensitive tasks.
Follow-up Question 4: How do you measure success for this routing system?
Success is measured by correct routing rate, specialist-agent usage, call resolution time, and customer satisfaction scores. The classification model performance is tracked with metrics such as precision, recall, and F1. Business metrics like average handling time and first-call resolution indicate real-world impact.
Follow-up Question 5: How would you extend this approach to other use cases?
The same event-embedding pipeline can feed FAQ article recommendations and chat support triage. Any system requiring rapid, context-aware decisions can benefit. Developers only need to train a new downstream model that consumes the shared embeddings for a different prediction target.
Follow-up Question 6: How would you optimize infrastructure costs?
A smaller embedding dimension reduces memory footprint. Aggressive TTL on Redis limits storage overhead. Batching and asynchronous writes lower write-amplification. If event volumes become too large, specialized streaming solutions or more granular partitioning can be introduced.
Follow-up Question 7: Could you integrate larger foundation models?
Foundation models can process semi-structured data from multiple sources. They can learn richer representations than bag-of-words or standard sequence models. Integrating them would require additional compute resources and careful optimization. Real-time performance must remain within acceptable latency bounds, so techniques such as model quantization or distillation would be considered.
Follow-up Question 8: How do you handle privacy and data protection?
Data is anonymized before embedding. Personally identifiable information is removed or tokenized. Strict access controls limit who can query raw data. Regular audits ensure compliance with local regulations. Encryption in transit and at rest is mandatory, with short retention windows for sensitive data.
Follow-up Question 9: Could you illustrate a sample Python code snippet for training?
Below is an example of a simplified training script for the downstream classification step:
import numpy as np
from sklearn.linear_model import LogisticRegression
# Hypothetical function to get training data
train_events, train_labels = fetch_training_data()
# Convert tokens to embeddings by summing or averaging (pseudo-code)
def embed_token_sequence(tokens, token_to_vector):
vectors = [token_to_vector.get(t, token_to_vector['<UNK>']) for t in tokens]
return np.mean(vectors, axis=0)
X = []
for tokens in train_events:
X.append(embed_token_sequence(tokens, token_to_vector))
clf = LogisticRegression()
clf.fit(X, train_labels)
The embedding lookup uses a trained dictionary of token embeddings. Summation or averaging transforms the token list into a fixed-dimensional feature vector. The result feeds any typical classifier.
Follow-up Question 10: How do you ensure real-time retrieval of events is not a bottleneck?
The microservice that caches events must be horizontally scalable. Redis clusters handle high throughput reads and writes. Load is balanced across multiple instances. If event volumes spike, autoscaling helps maintain low latency. Network performance is monitored to avoid unexpected lag or congestion.