
ML Case-study Interview Question: Scalable Transformer Foundation Model for Unified Personalized Recommendations


Browse all the ML Case-Studies here.
Case-Study question
A major streaming platform maintains multiple personalized recommendation models, each focusing on different user needs such as “Recently Watched” or “Suggested Picks.” These models often rely on overlapping user data but are trained independently, which raises maintenance costs and slows the transfer of modeling innovations. The platform’s data science team wants to centralize preference learning into a single foundation model that can be fine-tuned for multiple recommendation tasks. They also want to integrate user interaction sequences of thousands of events and handle newly added content with minimal cold-start issues. How would you design and implement such a foundation model for personalized recommendations, ensuring it scales efficiently while retaining the ability to adapt to distinct downstream needs?
Full Solution
Building this foundation model involves large-scale semi-supervised learning on user interaction data. It uses an autoregressive sequence prediction paradigm to learn patterns from extensive histories. Combining request-time features (for context) and post-action features (for item engagement) captures short-term context and longer-term user preferences.
Data and Tokenization
Tokenization compresses raw user actions into meaningful tokens. It merges events on the same item to prevent bloated sequences. This approach balances preserving enough detail (like duration or engagement type) and keeping sequence lengths manageable. Sparse attention or sliding window sampling helps train the transformer backbone without hitting memory bottlenecks. During inference, caching key-value states avoids redundant computation.
Model Architecture and Training Objective
Autoregressive next-token prediction leverages unlabeled data at large scale. Weighting more important interactions (like a full watch over a short trailer) avoids treating all user actions equally. Multi-token prediction further improves the ability to capture longer horizons instead of just predicting the next single item. Auxiliary prediction tasks, such as predicting item genres, stabilize the training process and regularize model parameters.
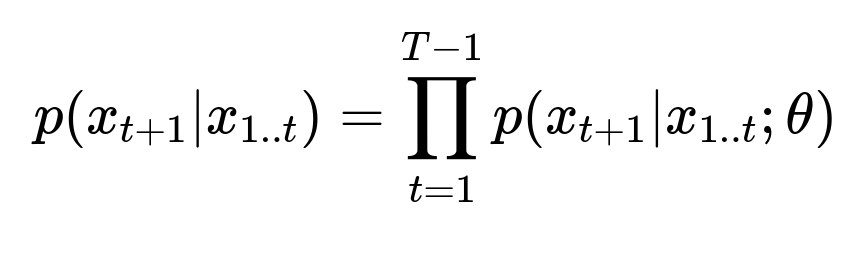
Above expression shows the probability of predicting the next user interaction x_{t+1} given all past interactions x_{1..t}, governed by model parameters theta.
Each token can embed numerous features: item ID, category embeddings, watch time, device type, and time-related details. Request-time features come from the context at prediction time. Post-action features come from the prior step’s engagement details. Combining both yields comprehensive token embeddings that capture user behavior patterns.
Handling Cold Start and Incremental Training
Newly introduced content requires embeddings even before any interactions exist. The solution learns from metadata embeddings, such as genre or country, which get combined with a learnable item ID embedding. A mixing mechanism biases new items more toward metadata when no interaction data is available. Incremental training updates the embedding layer by adding new item IDs without retraining the entire model from scratch. Model parameters for new items can be initialized as slight perturbations of an average embedding or formed from similar existing items.
Downstream Use Cases
The trained foundation model can generate user embeddings for personalization tasks. For a direct next-interaction forecast, the model’s logits produce item probability distributions. For tasks like candidate retrieval, the user and item embeddings can be used in similarity searches. When embeddings shift across model retrains, an orthogonal transformation may keep embedding dimensions consistent for downstream services.
Practical Implementation
A typical stack for this system in Python might involve TensorFlow or PyTorch for the transformer-based training loop. Data pipelines must handle billions of interaction records, applying token merging and sorting by time. Distributed training frameworks like Horovod or PyTorch Distributed are often needed for speed. Inference endpoints might use lighter transformer variants or optimized serving runtimes to preserve low latency.
Example code snippet for model definition (simplified):
import torch
import torch.nn as nn
class FoundationRecommender(nn.Module):
def __init__(self, num_items, embed_dim, metadata_dim):
super().__init__()
self.item_embedding = nn.Embedding(num_items, embed_dim)
self.metadata_projection = nn.Linear(metadata_dim, embed_dim)
self.transformer = nn.Transformer(
d_model=embed_dim,
nhead=8,
num_encoder_layers=6,
num_decoder_layers=6
)
self.output_fc = nn.Linear(embed_dim, num_items)
def forward(self, item_ids, metadata_embeddings, tgt_seq):
item_embed = self.item_embedding(item_ids)
meta_embed = self.metadata_projection(metadata_embeddings)
combined_embed = item_embed + meta_embed
combined_embed = combined_embed.transpose(0, 1) # Transformer requires seq x batch
# In practice, you may separate encoder/decoder for auto-regressive logic
output = self.transformer(combined_embed, tgt_seq)
logits = self.output_fc(output)
return logits
The code merges the item embedding with the metadata embedding, then processes the sequence through a multi-layer transformer. You can adapt it for sparse attention or sliding windows by replacing nn.Transformer with specialized modules. Fine-tuning for each downstream task can freeze parts of the model or re-initialize final layers.
What if the training data is noisy?
Data cleaning is critical. You might remove redundant or spurious interactions, apply normalizations to watch durations, or filter out bots. The objective function can also be weighted so that uncertain events carry less impact.
How to measure success during scaling?
Evaluate coverage, accuracy, or business metrics (like watch time or churn reduction) on large validation sets. Track perplexity-like metrics for next-item prediction. Compare these metrics as you increase model size or incorporate more training data, ensuring consistent improvements.
How to ensure embeddings remain valid across repeated deployments?
Embeddings drift whenever you retrain from random initializations. An orthogonal transformation can align old embeddings to the new space. This avoids invalidating downstream consumers that rely on stable embeddings.
How to reduce latency in production?
Use sparse attention or approximate nearest-neighbor techniques for partial sequence retrieval. Cache hidden states after each step to avoid recomputing transformer layers. Apply model quantization or distillation for further speedups.
How do you handle user interaction sequences exceeding thousands of events?
Token merging or chunking is essential. Avoid feeding the entire history directly. Sparse attention or hierarchical attention cuts computational overhead. Sliding window training ensures the model still sees all events over multiple training epochs.
How to address abrupt shifts in user preference (concept drift)?
Incremental training with the latest data helps adapt to new trends. Some teams maintain a short-term fine-tuned model that overwrites the older representation. This approach merges the stable representation of long-term preferences with immediate feedback.
Would you store embeddings for new titles offline or compute them on the fly?
Offline precomputation is typical for stable serving. On-the-fly embeddings get updated whenever new metadata appears. A mix of caching and partial online updates balances freshness and computational load.
How to confirm that multi-token prediction improves longer-term user satisfaction?
Run extensive A/B experiments on subsets of users. Compare the multi-token approach against single-token baselines. Gather metrics on session engagement, watch times, and user retention. Track consistency over extended periods.
How to incorporate external data like user reviews or social media mentions?
Represent those signals as auxiliary metadata (for items or even user sentiment). Combine them in the same manner as any other feature, with a separate embedding sub-layer. This extra context might sharpen cold-start predictions and refine personalization.
How to approach scaling beyond the current user base?
Increase training shards and adopt more specialized GPU/TPU clusters. Implement more memory-efficient attention. Regularly verify that the new model size meaningfully boosts predictive power. Prune model parts if diminishing returns set in.
How to keep the model interpretable?
Allow partial interpretability through attention visualization or factorizing the embedding layer for item metadata. Thorough documentation ensures that downstream teams know how embeddings are derived and how to interpret user preference signals.