
ML Case-study Interview Question: Auto-Classifying Restaurant Cuisines with Customer Clicks and Menu Embeddings


Browse all the ML Case-Studies here.
Case-Study question
You lead a Data Science team that must auto-classify restaurants into multiple cuisine types in a large-scale food delivery platform across different countries. The classification includes cuisine labels such as geographical or cultural cuisine (e.g. Italian, Singaporean) and dish-based cuisine (e.g. Chicken, Pasta). Some restaurants serve multiple cultural mixes, adding complexity. Manually labeling thousands of restaurants is too slow and inconsistent. You suspect customers’ on-platform behavior can help. How would you design a solution to classify these restaurants accurately at scale while handling subjective labeling and local context differences?
Proposed Solution
Cuisine definitions are subjective in different regions. Building a purely manual labeling approach causes inconsistent data, especially when many cuisine labels apply. A hybrid solution combines users’ on-platform clicks (search terms) and an unsupervised embeddings approach to detect similar restaurants. Label specialists then validate or prune incorrect labels.
Building the Model
Shortlisting Cuisines from Customer Clicks Customers often search using keywords that strongly indicate a cuisine. Collect these queries and see which restaurants they click on. Tag those restaurants with the queried cuisine. This bootstraps a set of labeled restaurants.
Generating Restaurant Embeddings Represent each restaurant by averaging vector embeddings of its menu items, for instance using fastText. Compute similarity scores between labeled and unlabeled restaurants. High similarity suggests the same cuisine.
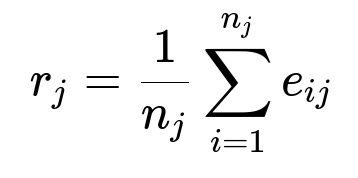
Here, r_{j} is the embedding of restaurant j in plain text format. n_{j} is the count of menu items for restaurant j. e_{ij} is the embedding vector of the i-th menu item for restaurant j.
A restaurant with no known labels is assigned a cuisine label if it is very similar to a labeled restaurant. This captures multi-cuisine contexts too (if a restaurant is close to multiple labeled clusters).
Label Validation Label specialists check the assigned tags. They only confirm or reject suggested cuisines. This speeds up labeling, reduces guesswork, and lowers the risk of missing relevant labels.
Key Observations
Subjective cuisine definitions require local context. Embeddings help uncover actual similarity across different menus. Some cuisines form distinct clusters (like Pizza). Others fragment into smaller clusters (like Desserts). Using customer clicks plus embeddings boosts buy-in from stakeholders, because the approach reflects real user behavior.
Model Limitations
Only predefined cuisines are detected. Fusion cuisines or edge cases may be missed. Wrong labels might be suggested if item names have multiple cultural interpretations. Click-based signals might be biased if customers search differently in certain regions.
Future Extensions
Calibrate thresholds for cosine similarity to refine label assignment. Identify new cuisine subgroups (e.g. coffee, bubble tea) by discovering subclusters in the embedding space. Use embeddings to remove incorrect labels if similarity is too low. Extend the approach to multiple languages or character-based languages.
Practical Implementation Example
Use fastText or a similar library to create word vectors for each item description. Store embeddings in a vector database or a sparse matrix. Compute cosine similarity with a library function and build a pipeline to push label suggestions. Maintain an interface for label specialists to confirm or reject cuisine tags.
import fasttext
import numpy as np
# Load or train fastText model
model = fasttext.load_model('fasttext_model.bin')
def restaurant_embedding(menu_items):
vectors = []
for item in menu_items:
v = model.get_sentence_vector(item)
vectors.append(v)
return np.mean(vectors, axis=0)
# Suppose we have a dictionary of restaurant_id -> cuisine_labels from user searches
labeled_restaurants = get_labeled_restaurants_from_clicks()
# Generate embeddings for all restaurants
restaurant_vectors = {}
for rid, items in all_restaurant_menus.items():
restaurant_vectors[rid] = restaurant_embedding(items)
# Compute similarities to labeled restaurants
candidate_labels = {}
for rid_unlabeled, vec_unlabeled in restaurant_vectors.items():
for rid_labeled, label_set in labeled_restaurants.items():
sim = cosine_similarity(vec_unlabeled, restaurant_vectors[rid_labeled])
if sim > threshold:
candidate_labels[rid_unlabeled] = candidate_labels.get(rid_unlabeled, set()) | label_set
# label_specialists then validate candidate_labels
How do you ensure data labeling quality?
Labeling specialists only confirm or reject suggested cuisines. They do not manually propose new labels. This reduces randomness. The approach uses explicit user signals (clicks) as evidence that a restaurant should get a certain label.
How do you handle false positives from ambiguous menu items?
Refine text preprocessing (synonym expansion, context-based disambiguation) to ensure “Carrot Cake” is interpreted correctly. Possibly add metadata (images or restaurant-level tags). Control the similarity threshold to reduce spurious matches.
What if restaurants have incorrect labels from outdated information?
Maintain a routine re-check. Recompute embeddings when menus change. Track user actions over time. If user engagement for a label is low, remove that label.
Could you discover new cuisines beyond a predefined list?
Inspect the embedding space for distinct clusters that are not aligned with known categories. Propose new categories to domain experts if there is a consistent group of restaurants with similar items (e.g. bubble tea).
How do you extend this to multiple languages?
Use multilingual word embeddings or train separate fastText models for each language. Concatenate or unify embeddings if items mix languages. Evaluate performance on each language domain.
How do you validate performance if manual labeling is limited?
Start with a small curated reference set. Track precision and recall on that set. Measure any correlated metric like user click-through rate for each labeled cuisine. Compare model-labeled restaurants vs. baseline.
What if the platform has a large language model-based approach?
A large language model could embed each menu item in a semantically rich vector. The rest of the steps remain similar. The label propagation logic based on similarity scores stays the same.