
ML Case-study Interview Question: Productionizing Interactive LLM Coding Assistants for Enhanced Developer Workflows


Browse all the ML Case-Studies here.
Case-Study question
You are presented with a scenario where a major platform launched an AI-driven coding assistant that uses a large language model to help developers throughout the software development lifecycle. The platform experimented with several prototypes: an AI-assisted pull request summary generator, an AI-driven documentation assistant, and a command-line interface assistant for generating and explaining commands. These prototypes produce suggestions that can sometimes be incorrect, and their usefulness hinges on how the output is presented to the user. Developers have shown more acceptance when they can edit or confirm the AI suggestions rather than having the AI post automatically. Your task is to design an end-to-end solution to productionize these AI-assisted features.
Please propose a strategy for:
Integrating the AI tools into the existing software ecosystem.
Handling errors or inaccuracies in AI-generated recommendations.
Ensuring the user experience reduces friction when verifying or editing AI outputs.
Managing model training, prompt engineering, or retrieval methods to improve accuracy and guard against security risks.
Measuring success metrics for adoption, correctness, and developer satisfaction.
Detailed solution
Overview
AI-driven coding assistants rely on large language models that generate contextual suggestions, code completions, or explanations. The goal is to integrate these assistants so developers can quickly adopt them without sacrificing trust or productivity. The approach revolves around interactive UX design, robust retrieval for context, iterative fine-tuning, and clear fallback strategies for inaccuracies.
Technical architecture
Use a client-server design. The client (e.g., a browser-based editor or command-line tool) sends context (code, documentation references, user queries) to a service that holds the large language model. The service returns results that the client displays in a way that users can accept, refine, or reject.
Key formula for LLM optimization
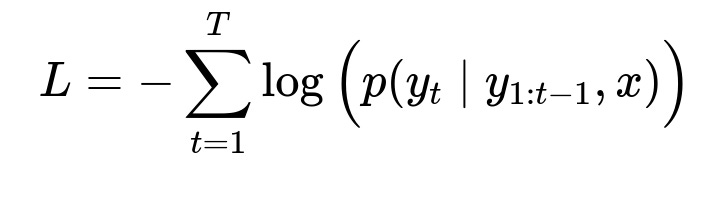
This represents the cross-entropy loss.
T is the length of the sequence.
y_{t} is the token at position t.
x is the input context.
p(y_{t}|y_{1:t-1}, x) is the predicted probability of the next token given previous tokens and the context. Minimizing this loss helps the model produce more accurate next-token predictions.
Explainable AI outputs
Always provide rationale for suggestions. For instance, an assistant generating command-line prompts should include an explanation field describing each part of the command. This fosters trust and helps users catch errors. For a pull request summary tool, an AI-generated draft becomes a suggestion that can be easily edited before finalization.
Error handling and accuracy improvement
Add retrieval steps to gather relevant knowledge, such as existing documentation or code context, before passing it into the model.
Let users see references or source links so they can quickly verify correctness.
Capture user feedback (e.g., upvotes, edits) and feed this back into iterative fine-tuning or few-shot prompting.
Security considerations
Process user inputs carefully to avoid unintended commands or code injection. Use deterministic checks on AI-generated outputs, particularly for shell commands or code modifications, to reduce risks. Filter dangerous keywords and confirm with the user when the command modifies system-critical files.
Example code snippet for integrating an AI doc-search
import requests
def fetch_contextual_docs(query):
# Query a vector database for doc embeddings
url = "https://my-docs-server.example/search"
payload = {"user_query": query}
response = requests.post(url, json=payload)
return response.json()
def generate_answer_with_context(query, model_api_endpoint):
docs = fetch_contextual_docs(query)
prompt_content = f"Answer with the context: {docs}. User query: {query}"
# Send prompt_content to the LLM's API
r = requests.post(model_api_endpoint, json={"prompt": prompt_content})
return r.json()["completion"]
This approach retrieves relevant documents first, then composes them into the prompt. The model uses that context to generate more accurate answers.
Measurement of success
Track usage stats such as how often suggestions are accepted or edited. Use acceptance rate, edit distance, or time saved as success metrics. Log the rate of incorrect outputs, measure resolution time, and tally user satisfaction surveys. Over time, refine the model or retrieval pipeline to boost accuracy.
How would you manage prompt engineering for more control?
Prompt engineering involves carefully crafting the inputs to the model so it produces reliable answers. Provide explicit instructions or structure in the prompt for the model to follow. Include short examples of correct outputs (few-shot examples). If you need structured results (e.g., JSON), instruct the model to output strictly in JSON format. These techniques increase consistency.
Use a layered approach:
Generate an initial completion from the model.
Post-process if needed. For instance, parse or validate the response, then re-prompt if the answer violates format requirements.
How would you handle iterative fine-tuning if the model makes frequent mistakes?
Collect examples of erroneous outputs along with the correct solutions. Re-train or fine-tune on these pairs. Update your training dataset to reflect real-world usage patterns. If frequent mistakes arise from domain-specific terms, incorporate domain text into the fine-tuning corpus. Evaluate improvements on a validation set that contains tricky samples.
Augment data by including user feedback:
User rejects an AI suggestion.
System logs the correct fix provided by the user.
Fine-tuning data pairs the original prompt with the corrected answer.
How do you secure an AI-generated command-line feature?
Separate user privileges from AI suggestions. If the AI tries to generate destructive commands, prompt the user for extra confirmation. Maintain an allowlist or denylist of commands. For critical operations (e.g., editing system files), present a clear summary. Consider sandboxing commands or imposing access controls so the AI cannot circumvent security policies.
Prevent prompt injection:
Strip suspicious tokens or hidden instructions from user input or model outputs.
Avoid blindly running commands that the user hasn’t confirmed.
How would you integrate these AI features across an entire platform?
Embed the AI assistant in multiple workflows, such as code reviews, documentation lookups, and command-line interactions. Ensure consistent authentication, logging, and usage analytics. Provide a unified interface where users can configure personal or team-based preferences for the AI’s style and capabilities. Use modular APIs so each feature (pull requests, docs, CLI) communicates effectively with a shared AI backend.
Keep a central feedback loop where usage metrics from each integration feed into a central data store. Periodically review feedback, identify patterns of AI failure, and refine the system accordingly.
How do you measure success beyond correctness?
Look at user engagement over time. If usage grows and overall development speed increases, that suggests the AI tools add value. Conduct developer satisfaction surveys, track whether developers are finishing tasks faster, and see if they rely less on external searches. Combine these metrics with error rates, acceptance levels, and manual intervention times to form a holistic view of success.