
ML Case-study Interview Question: Aligning Ad Prediction Models: Fixing Offline vs. Online Performance Discrepancies.


Browse all the ML Case-Studies here.
Case-Study question
A fast-growing platform is monetizing through ads, relying on machine learning models to predict user conversions and optimize ad rankings. They observe that newer models show strong offline metrics (like higher area-under-curve) but do not consistently yield better online metrics (like lower cost-per-acquisition) when tested in live A/B experiments. They suspect feature inconsistencies, model-training bugs, or pipeline issues. They also worry that offline metrics might not correlate well with real-world business targets. As the Senior Data Scientist, outline a step-by-step plan to diagnose and resolve these online-offline discrepancies. Propose how you would design experiments to isolate potential bugs, choose more aligned metrics, ensure data consistency, and deploy solutions that can handle traffic spikes and stale features.
In-depth Solution
One critical step is diagnosing potential mismatches between offline metrics and actual business targets. Area-under-curve (AUC) or log-loss do not necessarily map well to real-world cost metrics. Including an offline proxy for cost-per-acquisition (CPA) or closely related financial metrics can improve alignment. When defining CPA, we use:
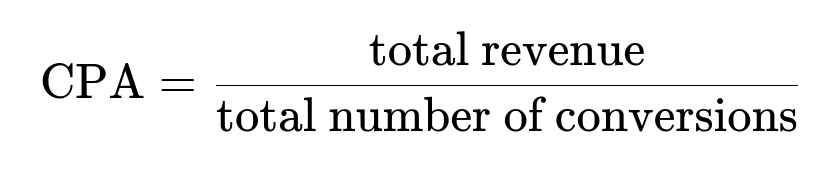
Where total revenue is the sum of ad spend or relevant payments received during the experiment window, and total number of conversions is the approximate count of successful user actions labeled as conversions.
To mitigate label errors or noise introduced by external sources, check label coverage and quality early in the pipeline. Fix or omit faulty data segments before model training. Ensure that new features introduced for the treatment model appear consistently in both the training set and the real-time serving environment. Confirm that data transformations match precisely in both environments.
Keep the training pipeline robust and watch out for feature discrepancies caused by asynchronous logging. For example, if feature values get refreshed only at certain hours, the model might be serving partially stale features. Investigate the magnitude of performance drops for requests missing up-to-date data. Build resilience into the model to handle missing feature values gracefully.
Model Training Pipeline
Train your model with a standard approach. After training, run a batch inference job on fresh logs to compare predicted scores with expected outputs. If offline predictions look consistent, push the model checkpoint to storage for serving. Implement checkpoint integrity checks to detect corruption. Monitor the time it takes for the new model to appear in the online environment and confirm that the correct checkpoint is in use.
Online Serving Framework
When the model is deployed, confirm that the features extracted at serving time match those used during training. If a caching layer is involved, verify that the online logs show the correct feature values. In high-traffic spikes, the feature store might return null or stale data. Set up stable caching or fallback strategies and track how often missing or partial features occur. Investigate dropoffs in performance during peak load by replaying logs for stress tests offline.
Tying Metrics Together
A model can show consistent improvement in AUC but fail to cut overall cost if downstream ensembles or other ranking logic dilute its impact. Examine how the new model’s scores integrate with the final bidding algorithm. Align model outputs with the final business objective instead of focusing on a single classification measure. Consider building new custom offline metrics approximating cost-based gains across segments of traffic.
Experimentation
Maintain robust experimental design to minimize cross-contamination between control and treatment. If the control model is learning from treatment-affected data, separate their training logs or ensure a short testing window. Run short ramp-up experiments at smaller percentages of traffic to catch anomalies early. Expand the experiment if results remain stable. Ensure that you can roll back quickly if you see major performance degradation.
Handling Unexpected Failures
Use logs and aggregated dashboards to spot suspicious distribution shifts in features, coverage, or conversion labels. Confirm your pipelines emit alerts if coverage or freshness for key features drifts below thresholds. If there is a mismatch between offline gains and online losses, replay the model with the same features used in real-time. This helps detect whether the pipeline is indeed feeding the right inputs. Build resilience for any memory or traffic bottlenecks.
Example Code Snippet for Replay
import pandas as pd
from some_ml_library import Model
# Suppose we have logged_data with features and labels.
logged_data = pd.read_parquet("logged_data_for_day.parquet")
model = Model.load_from_checkpoint("my_model_checkpoint")
# Batch inference
logged_data["predictions"] = model.predict(logged_data[feature_cols])
# Compare with offline predictions or analyze distribution
distribution_check = logged_data.groupby("some_key")["predictions"].mean()
print(distribution_check.describe())
This approach checks if the model’s predictions align with the logs. If a discrepancy appears, investigate caching or pipeline issues.
Possible Follow-up Questions
How do you enforce data consistency between offline training and online serving?
Confirm that the same feature computation logic runs in both environments. Have a unified feature store controlling transformations. If features are aggregated daily, confirm that offline training uses similar daily snapshots. Run daily or hourly checks to catch data shifts or missing coverage. Keep a small fraction of traffic for logging both the predictions and raw feature values. Compare them to see if features match expectations. If mismatches are detected, halt training or revert to the previous pipeline version.
How do you make the model robust to missing or stale features?
Train with augmented data that simulates random feature drops or older feature values. Include placeholders or default values so the model can produce reasonable scores. Monitor performance specifically for the segments with missing features. If the model sees too many missing features, investigate the pipeline latencies or caching constraints. Consider fallback heuristics or simpler sub-models triggered when crucial features are unavailable.
How do you decide which online metric to use?
Clarify the business objective. If cost-per-acquisition or return-on-ad-spend is the main target, design an offline approximation of these. If you rely solely on AUC or precision-recall, you might miss how changes affect cost or revenue. Ensure your offline metric correlates strongly with your final online metric by analyzing historical data. If correlation is weak, refine the offline metric or incorporate cost-based weighting into your loss function.
How do you detect that the control model is learning from treatment data?
Compare metrics from traffic that is purely served by the control model to the traffic served by the treatment model. If your system has shared training logs, isolate them so that the treatment traffic’s outcomes do not feed back into the control model’s next training cycle. If cross-contamination is unavoidable, reduce the experiment window or traffic percentage. If you suspect it’s happening anyway, re-train the control model on older logs unaffected by the treatment model’s changes.
How do you diagnose a potential slowdown or model failure in production?
Set up distributed tracing and error-rate monitoring. If response times spike, quickly reduce the treatment traffic. Check if your GPU or CPU usage is saturated. If the model sees high input QPS, scale the cluster or set autoscaling rules. If the pipeline fails to produce fresh features, revert to a stable model version until reliability is restored.
How do you handle label noise and partial label availability?
Implement label validation. If external sources provide conversions, watch for anomalies or missing data. Adjust your training sets to exclude advertisers or sources with repeated label issues. Combine multiple signals (click-based, view-based, or on-platform events) for better label reliability. Use a robust training objective that can handle uncertain labels (for instance, partial labeling or feedback loops). Periodically retrain or fine-tune to adapt to shifting label quality.
How do you unify separate models without losing specialized signals?
If multiple models feed into a final ensemble, ensure each model’s output is scaled appropriately. Examine how each model’s predictions contribute to the final bidding logic. If certain models overshadow others, re-tune weighting schemes. If the final aggregator model or rule-based logic is too rigid, refine it to incorporate changes in the new model’s probability distribution.
How do you confirm that your solution’s changes persistently boost metrics?
Deploy a long-running experiment to track performance over time. Watch for external factors like seasonal traffic or major marketing campaigns. Compare both short- and long-term performance. After the model is fully ramped, re-check offline metrics on the newly collected data. If the improvements hold steady or improve further, keep the new model. Otherwise, iterate again with refined features or new data checks.
These steps ensure thorough debugging and optimization of large-scale ads systems. They keep the pipeline consistent, the metrics aligned, and the system stable even under unexpected data fluctuations.