
ML Case-study Interview Question: Scalable Item Dimension Prediction Using FastText Embeddings and Approximate Nearest Neighbors


Browse all the ML Case-Studies here.
Case-Study question
A leading e-commerce platform processes millions of shipments daily. Some items lack accurate package dimensions (weight, length, width, height), causing errors in shipment cost calculations and fulfillment center occupancy forecasts. You are asked to design a model that predicts missing item dimensions. The model should find similar items based on text metadata, then estimate final dimensions. Provide a full plan for data sourcing, feature engineering, model architecture, model serving, and deployment. Explain how you would handle training at scale and real-time predictions.
Detailed Solution
The solution uses a pipeline approach:
Data Collection and Feature Engineering
Data is gathered from different sources: one containing item metadata (title, category, brand, model) and another with reported package dimensions (weight, height, width, length). Each item’s shipments come with varying reported dimensions. A single dimension set per item is derived by taking median values to reduce outlier impact. Titles and other text fields are cleaned by removing diacritical marks, tokenizing, converting to lowercase, and applying spelling checks.
Vector Representation via Embeddings
A FastText model is trained on the cleaned text to generate dense vector representations for each item. Each item’s input features consist of its embedded vector (derived from title, category, brand, and model concatenated into a single string).
K Nearest Neighbors Regressor with Approximate Search
An approximate nearest neighbor search library (Annoy) is used to store and retrieve items in an embedding space. When a new item’s embedding vector is queried, Annoy finds the K closest vectors based on a distance metric:
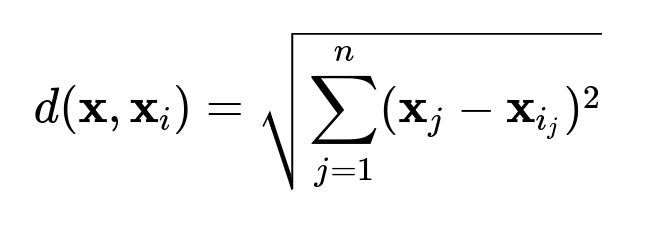
All neighbors exceeding a distance threshold T are discarded. The remaining neighbors are used to compute a final median dimension estimate for the query item. This approach handles large-scale data more efficiently than exact nearest neighbor searches.
Model Serving and Scalability
The pipeline is exposed via an API. Given an item’s text metadata, the service:
Preprocesses and embeds it.
Fetches approximate neighbors with Annoy.
Filters neighbors by distance threshold T.
Takes median of neighbors’ dimensions. The system handles high request volume by horizontally scaling the service on instances with sufficient RAM and CPU resources. Inference time can be as low as a few milliseconds per request, even at tens of thousands of predictions per minute.
Code Snippet Example
import fasttext
import annoy
import numpy as np
# Train FastText model (simplified example)
model = fasttext.train_unsupervised('items_corpus.txt', lr=0.05, epoch=5, dim=100)
# Build Annoy index
ann_index = annoy.AnnoyIndex(100, 'euclidean')
for idx, item_vector in enumerate(item_vectors):
ann_index.add_item(idx, item_vector)
ann_index.build(10) # number of trees
def predict_dimensions(item_text):
# Preprocess item_text
cleaned_text = preprocess(item_text) # remove accents, tokenize, etc.
vector = model.get_sentence_vector(cleaned_text)
# Approx nearest neighbors
neighbor_ids = ann_index.get_nns_by_vector(vector, k=50)
neighbors_filtered = [nid for nid in neighbor_ids if distance_ok(vector, nid)]
# Retrieve dimension sets and compute median
dims = [stored_dims[nid] for nid in neighbors_filtered]
return np.median(dims, axis=0)
What hyperparameters matter most and why?
High-level hyperparameters include:
The dimensionality of the FastText embeddings. Larger dimensions might capture more semantic nuances but risk overfitting. Smaller dimensions train faster but might reduce expressiveness.
The number of trees in Annoy. More trees often give higher accuracy at the cost of build time and memory usage. Fewer trees yield faster build but potentially lower recall.
The distance threshold T for neighbor filtering. Too high allows irrelevant neighbors, too low might filter out valid neighbors.
How do you handle items with limited metadata?
Items with very short or noisy titles can be enriched by category-level embeddings. One approach is to use fallback embedding sources (category alone or brand-model if available). If there is no matching neighbor set, the system can apply a more generic dimension estimate based on historical averages in a specific product category.
How do you update the model for newly introduced products?
New items often have metadata never seen during initial training. The steps:
Re-train or periodically fine-tune the FastText model with new text data.
Dynamically insert new item vectors into the Annoy index. Annoy allows adding items incrementally, but for very large updates, a fresh rebuild might be needed to preserve speed and accuracy.
How do you evaluate performance at scale?
Mean Absolute Error (MAE) and Mean Absolute Percentage Error (MAPE) are common for dimension prediction. System coverage metrics measure how many items get dimension estimates. Calculate coverage on raw item-level data before transformations so results reflect real-world scenarios.
How do you mitigate high memory usage for the Annoy index?
Annoy indices can become large with millions of items. Techniques:
Use a dimensionality that balances representation with memory footprint.
Use multiple indices sharded by product categories.
Rely on streaming or incremental updates if feasible, offloading older items to secondary storage.
How do you ensure inference speed is acceptable at high traffic?
Optimize the Annoy index build with sufficient trees to maintain accuracy but not too many that queries slow down. Deploy the index in memory on instances with enough RAM. Scale horizontally with load balancers, distributing lookup requests across multiple replicas.
How do you handle outliers or items with contradictory dimension information?
Multiple shipments might yield conflicting dimension values. Taking the median per item helps reduce the effect of outliers. Additionally, watch for items whose dimension spread is unusually large. They can be flagged for manual review or special rules if the system sees repeated inconsistencies.