
ML Case-study Interview Question: End-to-End Deep Learning for Video Recommendations to Maximize User Engagement


Browse all the ML Case-Studies here.
Case-Study question
You work at an online streaming platform with hundreds of millions of daily active users. The company wants to improve its recommendation system for video content, aiming to maximize user watch time and engagement. The platform’s existing approach uses collaborative filtering with minimal feature engineering. Management suspects there is latent information in the content metadata, user watch histories, timestamps, and contextual data. They want a full-fledged machine learning solution: data ingestion, feature extraction, model training, real-time inference, and performance evaluation. Propose a design for the end-to-end system. Include modeling strategies, relevant machine learning or deep learning approaches, infrastructure considerations, and a plan to evaluate and iterate. Provide enough detail to allow an engineering team to build and deploy it. Assume large-scale data with strict performance requirements. How would you ensure reliability, scalability, and continuous improvement?
Detailed Requirements
Explain the entire process of: Data collection and cleaning. Feature engineering from user behavior and content metadata. Model training (candidate generation vs ranking). Realtime inference pipeline. Handling model drift and feedback loops. Measuring success metrics and business impact.
Detailed solution approach
An end-to-end recommendation system here involves distinct stages. Each stage must be carefully orchestrated to handle large volumes of data with minimal latency. Management’s aim is maximizing engagement, so watch time, clickthrough rate, and session length become critical success metrics. The solution below addresses data pipelines, model training, feature engineering, deployment, and monitoring.
Data ingestion and cleaning The platform collects logs on user sessions, watch durations, device types, timestamps, and user demographics. This data flows into a distributed data store (for instance, a data lake). Engineers build ETL routines that clean duplicates, remove corrupted rows, and reconcile partial user records. After quality checks, the cleaned dataset goes into a structured format that allows querying at scale.
Feature engineering Relevant features include user watch patterns, user preferences by genre or keyword, time-based trends (peak hours vs off-peak), and metadata embeddings for content. Each video’s metadata can be converted into vector representations by training a neural embedding model on textual descriptions, tags, or transcripts. Similarly, user historical behavior can be converted into aggregated features such as average session length or skip rate. Combining these features yields a richer representation than simple collaborative filtering.
Model training The system splits into two main sub-models: a candidate generator and a ranker. The candidate generator narrows the universe of videos to a smaller set. A possible approach is a deep learning model that uses user embeddings and video embeddings to compute similarity. The ranker then refines the short list using a more advanced model that incorporates all the engineered features. A gradient boosted decision tree or neural network can handle tabular features, embeddings, and session context to produce final scores.
When training a neural network for classification, watch likelihood or engagement probability can be optimized using a cross-entropy loss function. The system might produce a probability for each user-item pair. The network is trained to discriminate whether the user engaged with that video or not.
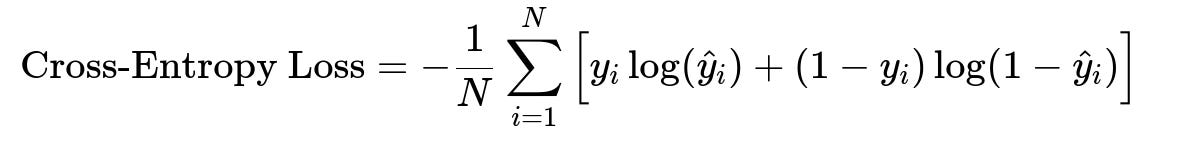
Here, y_{i} is the true binary label (engaged or not), and hat{y}_{i} is the model’s predicted probability of engagement for the i-th example. This formula is crucial because it quantifies the penalty when the predicted probability deviates from the ground truth. Minimizing cross-entropy helps the model adjust parameters to improve engagement predictions.
Infrastructure and deployment Data is stored in a distributed file system. Training is orchestrated using a cluster of GPU or CPU instances. The candidate generation model might run on a dedicated service that retrieves top relevant video IDs for each user in real time. The ranker model runs in a low-latency inference environment. Engineers can deploy the models as microservices behind load balancers, ensuring autoscaling. A feature store manages real-time user statistics. A message queue handles user events, which are continuously fed back into the system to update user embeddings.
Evaluation and iteration The core metrics are watch time, user retention, and overall engagement. Offline evaluation uses standard metrics such as Mean Average Precision at K or Normalized Discounted Cumulative Gain. Online evaluation uses A/B testing. Engineers analyze user cohorts to see if certain groups benefit more from the new approach. Over time, the team refines the feature set to capture emerging user behaviors. Periodic retraining addresses model drift.
Reliability and scalability Kafka or Kinesis can queue high-volume streaming data. Spark or Flink can process real-time logs. Model inference must respond within milliseconds, so an efficient ranker is key. Engineers might keep the candidate generator less complex to handle massive user loads, while the ranker can be more sophisticated but only runs on a short candidate list. The system is closely monitored for errors or latency spikes, triggering alerts and fallbacks.
Example code snippet for model training
import tensorflow as tf
# Hypothetical dataset placeholders
user_features = tf.placeholder(tf.float32, shape=[None, 128])
video_features = tf.placeholder(tf.float32, shape=[None, 128])
labels = tf.placeholder(tf.float32, shape=[None, 1])
# Simple feed-forward architecture
concat_input = tf.concat([user_features, video_features], axis=1)
hidden1 = tf.layers.dense(concat_input, 256, activation=tf.nn.relu)
hidden2 = tf.layers.dense(hidden1, 128, activation=tf.nn.relu)
logits = tf.layers.dense(hidden2, 1, activation=None)
predictions = tf.nn.sigmoid(logits)
loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(labels=labels, logits=logits)
)
optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
# Normal training loop
Engineers run epochs until the model converges on offline metrics. They then deploy the model behind an inference API. Logs continuously track model performance. Retraining might occur daily or weekly.
Summary
This architecture captures user embeddings, content embeddings, and fine-grained features. The candidate generation stage screens out irrelevant content at scale, while the ranker refines the final set. The system integrates with streaming pipelines for real-time feedback. A/B testing verifies improvements. Continuous retraining handles data drift.
Follow-up question 1
Explain how you would handle cold-start users with almost zero watch history or preference data. How would you adjust the system to recommend relevant items for them?
Detailed answer
The system handles cold-start by relying on broad preference signals beyond individual watch history. New users might receive recommendations from a popularity-based or rule-based system. The ranker could incorporate demographic or device-level data if available. Metadata-based embeddings for content might also guide top picks, for instance showcasing popular, high-rated, or trending videos. As soon as the user interacts with any content, the system updates user embeddings. Over time, the model transitions to more personalized suggestions.
Follow-up question 2
How do you manage model drift in this environment, especially if user tastes or trending content change rapidly?
Detailed answer
Model drift occurs when the data distribution shifts. Retraining is scheduled at frequent intervals, maybe daily, to capture fresh trends. The system also monitors performance metrics such as daily watch time or clickthrough rates. If performance dips, a faster retraining or a fallback system might be triggered. Real-time embedding updates help mitigate drift in user features. At inference time, if new content is not adequately represented in the model, the candidate generator can re-embed the new items rapidly.
Follow-up question 3
How would you implement explainability in this recommendation system to help product owners understand why certain videos are being recommended?
Detailed answer
Engineers might use feature importance methods or Shapley value approximations on the ranker model. For instance, they parse the main signals influencing a recommendation, such as strong content similarity to the user’s past watch history or popularity within certain time slots. The platform can display a short rationale, like "Because you watched sports highlights" or "Trending in your area." Internally, product owners see an aggregated view of the top features in the ranker’s decisions. This helps debug odd recommendations.
Follow-up question 4
How would you scale hyperparameter tuning for deep models, especially when dealing with millions of videos and millions of users?
Detailed answer
Hyperparameter tuning can be parallelized with frameworks like Hyperopt or Bayesian optimization. Training subsets of data in parallel reduces search time. Distributed training on GPU clusters helps handle large data. Engineers might employ early stopping, measuring partial epochs on validation sets to quickly discard unpromising hyperparameter sets. The final selected configuration is tested on a holdout set before full-scale training. Automated tools or custom pipelines schedule repeated tuning. Advanced search methods, such as population-based training, further optimize results.
Follow-up question 5
If the system experiences a sudden traffic spike, how do you ensure fault tolerance without service downtime?
Detailed answer
A robust architecture must have autoscaling groups for inference services. A load balancer routes incoming requests to healthy instances. A circuit breaker pattern halts calls to failing model endpoints to avoid cascading failures. Caching might serve top videos in case of partial outage. Engineers keep a fallback policy, such as showing top trending videos. Stored snapshots of critical user embeddings accelerate state restoration. Thorough monitoring triggers instant alerts, and a rollback plan ensures minimal interruption.
Follow-up question 6
Why not rely solely on collaborative filtering for this system?
Detailed answer
Collaborative filtering alone uses only historical user-item interactions. It struggles with new items or cold-start users. It also misses out on contextual signals like time of day or device type. By integrating metadata embeddings and contextual features, the system surfaces fresh or niche content and adjusts recommendations based on real-time user patterns. This approach handles dynamic trends more effectively.
Follow-up question 7
What are common data pitfalls that might harm recommendation performance, and how would you mitigate them?
Detailed answer
Data pitfalls include incomplete logs, delayed streaming events, mismatched timestamps, or skewed user samples. Strict checks in the ETL pipeline detect anomalies. Logging must be consistent across devices and regions. Engineers align timestamps with a universal standard. If data for certain user segments is underrepresented, they might sample carefully or apply class-weighting in training. They also set up real-time anomaly detection to flag sudden shifts in data volume or distribution.
Follow-up question 8
How do you ensure user privacy and compliance when you collect and store this data?
Detailed answer
Data collection must align with privacy regulations. The system may apply anonymization or tokenization for sensitive fields. Secure data storage protocols ensure encryption at rest and in transit. Strict access controls guard user data. Minimizing personally identifying attributes at feature extraction helps reduce risk. Auditing and logging track who accessed which data. If required, the platform can store only aggregated statistics. The objective is to keep personalization while respecting user consent and compliance rules.
That completes the case study solution and potential follow-up Q&A.