
ML Case-study Interview Question: Enterprise App Recommendations via Relevance Models with Tunable Diversity and Explainability


Browse all the ML Case-Studies here.
Case-Study question
You are tasked with designing a data-driven system to recommend enterprise applications to business customers. The goal is to match the right third-party applications with relevant customers, help a sales team explore less-popular apps while still maintaining strong recommendation accuracy, and provide explanations for why certain items appear on top. The system must allow real-time control of how diverse the recommendations are, so that less-popular but relevant apps can surface. The system must also generate clear, item-level explanations and highlight relevant user features (such as demographics or installation history). How would you design and implement such a recommendation system? What techniques would you use to achieve high accuracy, real-time diversity adjustments, and transparent explanations? Describe your approach in detail, focusing on the entire pipeline from data ingestion to model deployment. Provide the technical reasoning for each component, including any machine learning architectures, hyperparameter tuning strategies, and real-world challenges you foresee. You also need to consider how to validate the model’s ability to boost diversity without significantly hurting accuracy and how to ensure the explanations are meaningful to end users.
Proposed Detailed Solution
Overview
This approach involves a relevance model for predicting how well a user will like an app, combined with post-hoc explanation models to handle diversity and generate explanations. The system takes a customer’s ID and a diversity parameter. The relevance model scores candidate apps. A separate mechanism then reduces the scores of the most popular items to expose less-popular apps when needed. Explanation models identify which features contribute most to the recommendation.
Relevance Model
It learns to predict a “similarity” or relevance score between user and app. For each user-app pair, the model might consume features including user demographics, past installation behaviors, industry, location, consumption patterns, and other numerical or categorical fields. In practice, a deep neural network or a wide-and-deep framework can be effective, as it handles both sparse categorical signals and continuous features. The relevance model is trained end-to-end to maximize metrics such as hit ratio or NDCG.
A Python training snippet could look like this:
import torch
import torch.nn as nn
import torch.optim as optim
class RelevanceModel(nn.Module):
def __init__(self, input_dim, hidden_dim):
super(RelevanceModel, self).__init__()
self.layer1 = nn.Linear(input_dim, hidden_dim)
self.layer2 = nn.Linear(hidden_dim, 1)
def forward(self, x):
x = torch.relu(self.layer1(x))
x = torch.sigmoid(self.layer2(x))
return x
# Example training loop
model = RelevanceModel(input_dim=100, hidden_dim=64)
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(num_epochs):
for batch_data, batch_labels in train_loader:
optimizer.zero_grad()
outputs = model(batch_data)
loss = criterion(outputs, batch_labels)
loss.backward()
optimizer.step()
This is a sketch. In a production environment, you would incorporate feature engineering, multiple embedding layers, or an attention network.
Diversity and Explanation Models
They approximate the relevance model’s outputs but in simpler ways, focusing on different aspects such as item popularity or specific feature correlations. By isolating these explanation models, the system can show which features (location, industry, or installed apps) matter most.
During real-time inference, the final score for user i and item j is:
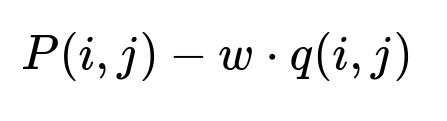
where P(i,j) is the relevance model’s predicted rating, w is the user-specified diversity parameter, and q(i,j) is an output from one of the explanation models. A higher w pushes the system to explore less-popular items by penalizing the more common ones.
Where:
P(i,j) comes from the trained relevance network.
w is a scalar that can be tuned at runtime to shift focus away from popular items.
q(i,j) is an estimate of how “common” or “hot” an item is, or a feature-based score from a post-hoc model.
A separate model can check how item features align with user features. For example, if a user has installed tool A, the explanation model might say item B is recommended because it shares relevant attributes with tool A.
System Flow
The sales team queries a recommendation service with a user ID and a parameter controlling diversity. The service scores apps, subtracts w*q(i,j), and produces a ranked list. The system also returns textual explanations by highlighting top features. This helps build trust. The user can adjust w in real time and compare the new list with the old list, balancing novelty and accuracy.
Implementation Details
The entire pipeline requires a data store that can combine user data (demographics, usage), app data (metadata, popularity), and interaction histories. A typical solution uses a distributed file system and a scalable database. The inference service would be containerized, e.g., using Docker, and then deployed to a cloud infrastructure that can handle real-time queries from the sales team.
A daily or weekly batch job can retrain the relevance and explanation models using up-to-date interactions. Once models are retrained, the new versions can be placed in the serving layer with minimal downtime. A typical MLOps cycle ensures that offline metrics align with online performance.
Follow-up question 1: How do you measure and validate the system’s capability to maintain accuracy while increasing diversity?
Use a held-out dataset of user-app interactions. First evaluate baseline accuracy using metrics like hit ratio at k or NDCG. Then vary w to increase diversity. Aggregate diversity is measured by counting unique items recommended across all users or by computing the distance between different users’ recommendation lists. Compare how these diversity metrics shift while monitoring accuracy. Find a w that gives a good trade-off. You might tune w through repeated validation cycles until you see a satisfactory balance. For large-scale scenarios, it is often tested in an A/B environment where some users see higher diversity recommendations. Track click-through, installation rates, and user satisfaction.
Follow-up question 2: Why train separate explanation models instead of incorporating explanation logic within the main relevance model?
Separate models remain simpler. Each can focus on a single explanation aspect. A single large model for both relevance and explanation might entangle many parameters, making interpretability harder. By approximating the relevance score, each explanation model can show a different rationale (popularity, key user features, item similarities). It is easier to maintain or replace each explanation model independently. It also allows faster real-time adjustments of explanation factors or popularity penalties without retraining the entire pipeline.
Follow-up question 3: How would you handle cold-start users or very new apps?
Map new users to sparse features (location, industry, or general usage categories) so the relevance model can still produce a reasonable estimate. For brand-new items, you might assign an average embedding vector or use textual descriptions and metadata. Over time, as real interactions accumulate, those items shift to specialized embeddings. One solution is to incorporate metadata-based similarity or content-based filtering techniques alongside the main model. This bootstraps the system’s ability to place brand-new apps into the recommendations.
Follow-up question 4: How do you explain feature-level and item-level rationales for a recommendation to the sales team?
Generate text strings: “This item is recommended because it shares these features with your environment: region=USA, cloud=Sales, installedAppX=SimilarTool.” Show the top few influencing features by ranking their contribution in the explanation model. Similarly, for item-based explanations, display the user’s installed tools that are most correlated with the recommended app. For each correlated installed tool, the explanation model can produce a similarity score. Sort those correlations and return them in a short textual format to the sales interface. This design keeps everything interpretable and quick to read.
Follow-up question 5: How do you handle potential biases or fairness concerns in such a recommender?
When a diversity parameter is raised, the system automatically boosts less-popular apps, mitigating bias favoring popular items. You can also use specialized fairness constraints in model training, such as balanced sampling of user segments or penalizing recommendations that are over-represented by certain categories. Continually monitor each segment’s recommendation outcomes and adjust training samples or regularize certain features to ensure balanced visibility of different apps or vendors. You might also maintain interpretability checks to see if certain demographic features dominate the model’s predictions unfairly.
Follow-up question 6: In practice, how do you ensure high performance and scalability in production?
Use batching and efficient data structures for embedding lookups. Precompute popular item lists. Optimize real-time scoring with vectorized operations or GPU acceleration if feasible. Cache frequently requested user representations. Distribute training and inference across multiple machines. Continuously track latency under production loads. Consider approximate nearest-neighbor methods if the item catalog is extremely large. Apply standard MLOps best practices such as versioning, container orchestration, and load testing to maintain reliability as traffic scales.