
ML Case-study Interview Question: Building Reliable RAG LLM Chatbots for Delivery Service Contractor Support


Browse all the ML Case-Studies here.
Case-Study question
A large delivery service has many independent contractors who frequently need support. An existing flow-based automation system resolves a small subset of issues. Most issues still need live agents. The company has a large knowledge base. They want to build a Retrieval-Augmented Generation (RAG) chatbot using Large Language Models to improve automated support. They also need a robust system to detect hallucinations, check response correctness, handle language consistency, ensure compliance, and reduce latency. How would you design such a solution, step by step, and what key components or approaches would you use?
Detailed Solution Explanation
The solution combines a RAG-based chatbot with additional modules for verification and monitoring. The components and their workflows are outlined in detail below.
RAG System
RAG uses relevant content from a knowledge base (KB) to enrich model responses. The KB consists of articles that answer frequent contractor questions. A vector store index can be created by embedding these articles. When a user raises an issue, the chatbot extracts the core user request and retrieves the top articles via similarity search.
Many RAG systems use cosine similarity on vector embeddings. One typical way is to represent the user query and KB entries as embeddings and measure their closeness using the cosine similarity measure.
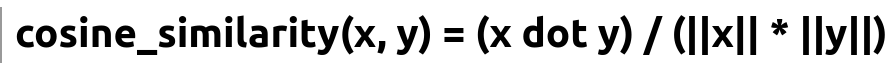
x and y are embedding vectors. x dot y is the dot product of x and y. ||x|| is the L2 norm of x. ||y|| is the L2 norm of y.
The RAG flow:
Summarize user conversation to derive a concise query.
Retrieve top N relevant KB articles by similarity.
Insert these KB article segments into the model prompt.
Generate an answer grounded in the retrieved text.
Guardrail System
A guardrail system intercepts the model's output and checks for correctness, relevance, and policy compliance. The main objective is to eliminate hallucinations and non-compliant content. An efficient strategy:
A quick shallow check compares the answer with the retrieved article text for semantic similarity.
If the shallow check flags potential hallucinations, an LLM-based layer further assesses coherence, correctness, and compliance.
A failing response triggers a fallback to a human agent.
This two-stage approach lowers computational overhead. Only suspicious outputs need deeper LLM-based evaluations.
LLM Judge
LLM Judge is an offline quality evaluation system. It processes thousands of chatbot transcripts and generates structured feedback, focusing on:
Retrieval correctness
Response accuracy
Language correctness
Coherence with conversation
Relevance to the user query
It uses open-ended questions to identify failure modes. Recurring issues are then tracked with rules or improved prompts. Human review teams also sample transcripts to maintain calibration.
Quality Improvement Pipeline
This pipeline addresses:
Knowledge base updates: Errors in KB articles often degrade system responses. Human experts update or clarify articles.
Retrieval enhancements: A carefully chosen embedding model and a well-tuned query summarization method optimize search results.
Prompt optimizations: Clear instructions and chain-of-thought guidance improve the generated responses.
Regression prevention: Prompt changes must pass a battery of tests (e.g., with open-source tools like Promptfoo). Any failing test blocks the new prompt.
Example Code Snippet for Retrieval
import openai
from sentence_transformers import SentenceTransformer
import numpy as np
# Load embedding model
model = SentenceTransformer('multi-qa-mpnet-base-dot-v1')
# Suppose we have a user's query:
user_query = "I cannot locate the customer to deliver the package"
# Summarize or refine query if multi-turn conversation:
refined_query = "Customer cannot be found by Dasher"
# Encode the refined query
query_embedding = model.encode([refined_query])[0]
# Assume KB_articles is a list of (article_id, article_text)
kb_embeddings = [(article_id, model.encode([article_text])[0]) for article_id, article_text in KB_articles]
# Compute cosine similarity and retrieve top matches
def cosine_similarity(vec_a, vec_b):
return np.dot(vec_a, vec_b) / (np.linalg.norm(vec_a) * np.linalg.norm(vec_b))
# Sort articles by similarity
sorted_articles = sorted(kb_embeddings,
key=lambda x: cosine_similarity(query_embedding, x[1]),
reverse=True)
top_n_articles = sorted_articles[:5]
The chatbot then creates a prompt by combining the user question, context, and these top N articles. The next steps involve response generation and passing the guardrail checks.
Follow-up Questions
1) How would you handle latency concerns when using large models?
High model latency can degrade user experience. Shortening prompts helps. Summarizing long conversations reduces token usage. Quick fallback to human agents when responses exceed a certain threshold keeps users engaged. Model distillation or smaller specialized models can also be used for faster responses. In some cases, a two-tier approach uses a lightweight model to triage simpler requests and escalates only complex cases to a larger model.
2) If a user interacts in a non-English language, how do you ensure the chatbot maintains language consistency?
Prompt the LLM explicitly to respond in the detected language. If the system retrieves KB articles in English, a second prompt can translate relevant passages. The guardrail can also check if the output matches the request language. A well-trained multilingual model often respects the language context if the instructions are clear. Testing with real user queries ensures coverage for different languages.
3) How do you prevent model hallucinations if the knowledge base is incomplete?
Hallucinations occur when no relevant KB entries exist. The system can sense a low similarity score and direct the user to a fallback response or a human agent. The guardrail can also reject responses if they have insufficient grounding in the KB. Error tracking with LLM Judge might reveal missing KB content, prompting article creation or updates to fill knowledge gaps.
4) How do you measure semantic similarity effectively?
Semantic similarity is often measured with cosine similarity. Different embedding models produce varied embeddings. Evaluating them on known ground-truth pairs helps. Sentence Transformers, or specialized domain embeddings, are strong candidates. In production, you can maintain a validation set of query-article pairs for ongoing model performance checks.
5) How do you handle repeated or multi-turn queries without losing context?
Use a conversation summary for each turn instead of appending the entire chat history. The summary includes the key user intent plus relevant facts from past turns. The summarizer can be a smaller language model or a simple text summarizer. This refined summary becomes the retrieval query for the next prompt, avoiding huge token overhead.
6) How do you systematically identify new failure modes during real-world deployment?
Logging and analyzing transcripts for user complaints, low satisfaction ratings, or guardrail triggers. LLM Judge can label transcripts with suspected error types. Frequent error patterns guide the next iteration of KB improvements, guardrail logic, or prompt updates. Human experts help interpret corner cases that the LLM struggles with.
7) What if the retrieval pipeline incorrectly picks articles?
Improve embedding accuracy by selecting the right model. Use specialized domain embeddings if general models fail to capture the right context. Adjust how you tokenize or chunk KB articles. Sometimes a smaller chunk size captures context better. Conduct A/B testing to confirm retrieval enhancements actually improve correctness.
8) How do you evaluate compliance in sensitive scenarios?
Compliance checks can look for any references to disallowed content, private user data, or policy breaches. You can embed a list of restricted keywords or phrases. A dedicated LLM or rules-based layer can flag suspicious responses. If flagged, the system either scrubs it or escalates to a human agent. Regularly updating compliance rules ensures coverage of new policy items.
9) How can chain-of-thought prompts help debug issues like logical missteps or missing references?
Chain-of-thought prompting encourages the model to show intermediate reasoning. That text helps you see if it made valid logical steps or used correct references. If an error surfaces, you can refine instructions or guardrail logic to correct it. This method is crucial for identifying hidden leaps in logic that cause subtle mistakes.
10) How would you address scaling if user volume surges?
Distribute workloads across multiple instances of your LLM service. Cache repeated queries or use retrieved contexts to avoid redundant calls. Parallelize guardrail checks by offloading them to smaller models or separate worker nodes. A traffic-based fallback approach can throttle the LLM usage and route simpler queries to a lighter system, ensuring stable system responsiveness.