
ML Case-study Interview Question: Hierarchical Cross-Domain Mapping for Cold-Start Grocery Recommendations with Location-Aware Ranking.


Browse all the ML Case-Studies here.
Case-Study question
A grocery delivery platform faces a cold-start recommendation challenge for new users. They have abundant user-item interaction data in their food-delivery domain, but limited data for groceries. They want a cross-domain approach that maps food-order histories to grocery preferences, then ranks grocery items to show each new user.
Propose a solution strategy. Explain how to handle the new user scenario, how to leverage historical data from the food domain, how to build and train a mapping that learns food-to-grocery category preferences, how to incorporate location-based product popularity, and how to generate final recommendations that outperform naive popularity baselines. Discuss the technical approach, modeling details, and any experimental methodologies. Include relevant performance metrics and how you would evaluate success.
Detailed solution
Overview of the approach
Use a two-stage architecture. First, map each user’s food-order behavior into grocery-category preferences. Second, feed the mapped category preferences plus product-specific features into a location-aware ranking model. Evaluate performance using metrics like Mean Reciprocal Rank (MRR) and Normalized Discounted Cumulative Gain (NDCG).
Candidate set generation
Create a retrieval layer that filters a few hundred or thousand products. Compute a popularity score based on recency-weighted frequency. This popularity score ρ is calculated as a weighted sum of order frequencies over recent days, with exponential decay. Each product p in store D, time slot T, and day offset delta from 0 to X contributes to the total:
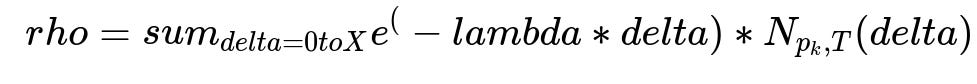
Here, N_{p_k, T}(delta) is how many units of product p were ordered delta days back in time slot T, and lambda is the recency decay factor. A larger lambda de-emphasizes older orders more strongly.
Hierarchical cross-domain mapper
Train multiple multi-label classifiers to link a user’s food-domain preferences at different hierarchical levels (L1, L2, L3) to the likelihood of ordering a corresponding grocery-category level. Represent each user by dish-family percentage vectors. The network outputs the probability of each grocery category being in their first grocery order.
For training, use positive labels for categories actually purchased in the user’s first grocery transaction. This yields a set of hierarchical mapping models that infer category-level affinities from food-order proportions.
Location-aware ranker
Take the outputs of the hierarchical mapper (category-level scores and ranks) plus other grocery-specific features (such as the product’s recency-weighted frequency ρ). Feed these into a pointwise gradient boosted trees classifier that scores each <user, product> pair. Train it by marking purchased products as positives and popular-yet-unpurchased products as negatives. Sort final candidates by the predicted score.
Why hierarchical mapping works better than direct embedding methods
Noisy embeddings arise from a long tail of items with limited training data. Aggregating at higher-level hierarchies (L1, L2, L3) smooths noise. Then, combining those category-level features with location-specific signals in a ranker captures local preferences and recency effects.
Evaluation
Measure offline NDCG and MRR against a held-out set of first grocery purchases. Compare to:
Pure popularity-based ranking.
Direct embedding mapping from user’s food vector to grocery vector (single-level approach).
Hierarchical cross-domain ranking typically yields higher NDCG and MRR, especially as users have more food-order history.
Follow-up question 1
How would you handle situations where you lack sufficient domain overlap? For example, if a user’s food-domain orders are too few or unrelated to the grocery domain?
Detailed answer
Build a fallback pipeline. If the user has minimal food orders or those orders do not map well to grocery categories, rely on popularity-based or demographic-based methods. You can segment users by recency or location and serve a more robust fallback recommendation. Another strategy is to incorporate additional signals (time-of-day preferences, user-supplied attributes, or search behavior). If domain overlap is partial, partially weight the cross-domain mapper’s outputs and combine them with a general popularity ranker or a user demographic embedding.
Follow-up question 2
How do you tune the recency decay factor lambda in the recency-weighted frequency formula, and why might its value differ across geographies?
Detailed answer
Set up a validation-based search. For each candidate lambda, compute NDCG on a hold-out set of user sessions. Select lambda that maximizes offline metrics while not overfitting. Then confirm with small-scale online tests. Different locations have different purchasing patterns and demand volatility. In regions with highly dynamic product turnover, a larger lambda helps emphasize recent trends. In regions with stable demand, a smaller lambda might work better because older orders remain relevant for a longer period.
Follow-up question 3
How would you adapt the ranker if you moved from pointwise learning to listwise learning?
Detailed answer
Use a listwise loss function, such as ListNet or LambdaRank, to handle the entire list of candidate products at once. Instead of scoring each product independently, these methods optimize the rank position directly, aiming to improve metrics like NDCG. You would construct training data by listing each user’s candidate products along with ground-truth relevances. The ranker learns parameters that produce an ordering aligned with higher user engagement or conversion. Listwise approaches often yield more globally optimal rankings but require careful tuning of hyperparameters and sampling strategies to handle large numbers of candidate items per user.
Follow-up question 4
How do you justify using a tree-based ranker over a multi-layer perceptron?
Detailed answer
Tree-based models handle sparse tabular features, nonlinearity, and location-based signals well without extensive feature engineering. They split on features directly (for example, popularity or category scores) and can handle categorical data easily once encoded. Multi-layer perceptrons can also work but often need more hyperparameter tuning, more data preprocessing, and might overfit if the data dimensionality is high. In many real-world production systems, gradient boosted trees provide a good trade-off between interpretability, training speed, and robust performance.
Follow-up question 5
Why is it necessary to train separate mappers for each hierarchical category level instead of a single multi-task model?
Detailed answer
Independent or loosely coupled multi-label models at different hierarchy depths simplify training and avoid confusion between broad-level (L1) categories and granular (L3) subcategories. The hierarchical structure is preserved because each level captures distinct correlations. A single multi-task model might overfit or conflate signals if the categories are heavily imbalanced. Separate mappers let you optimize each level separately. You can also ensemble them, giving each hierarchy’s prediction a partial weight, which often yields better generalization than a single large network.
Follow-up question 6
If you wanted to incorporate time-slot preferences or day-of-week preferences in the mapper, how would you do so?
Detailed answer
Augment user features with time-slot distribution: for instance, percentage of orders placed at morning, afternoon, or night in the food domain. Similarly, include day-of-week distribution or weekend vs weekday proportions. The mapper’s input vector grows to include these features alongside dish-family proportions. The multi-label classifiers then learn if certain groceries correlate with morning or weekend preferences in the food domain. This helps capture time-based correlations, like weekend breakfast items or late-night snack preferences.
Follow-up question 7
What would be your approach to detect and correct potential biases in the model?
Detailed answer
Look for systematic biases in item recommendations across user groups or geographies. Compare recommended items vs. actual user purchases to see if the model under-recommends or over-recommends certain categories. Perform A/B tests to measure if certain segments experience degraded accuracy. To fix biases, reweight training samples, add fairness constraints, or calibrate outputs. For example, if the ranker underweights new local items, artificially boost them in the training sample to ensure they appear frequently enough. Track fairness metrics and keep them within acceptable ranges, just like performance metrics.
Follow-up question 8
If the real-time system must respond in milliseconds, how would you deploy and scale this two-stage architecture in production?
Detailed answer
Precompute the candidate set via recency-weighted frequency offline. Store popular products per location-time slot in a low-latency data store. For each incoming user request, quickly extract their aggregated food-domain features (either precomputed or from a fast in-memory store). Pass them through the cross-domain mapper in micro-batches or using a lightweight inference service. Then feed the top candidate set, user-level features, and mapper outputs to the gradient boosted trees ranker. Output the top products immediately. Leverage model-agnostic serving tools like TensorFlow Serving or an XGBoost/LightGBM service with caching. Use minimal feature transformations and approximate nearest-neighbor methods if further speedup is needed.