
ML Case-study Interview Question: Hybrid ML Pipeline for Proactive and Reactive Viral Spam Detection.


Browse all the ML Case-Studies here.
Case-Study question
A large professional networking platform wants to detect spam content that can go viral rapidly, before it spreads widely among users. They already filter or remove some spam, but a few posts evade detection, accumulate significant engagement, and then become harder to contain. How would you design a robust Machine Learning pipeline to catch such viral spam content as early as possible, minimize false positives, and maintain a positive user experience?
Detailed Solution
Overview
Use two defenses that complement each other. One defense acts on newly posted content to block it proactively. Another defense monitors engagement signals to stop it from spreading reactively. Combine both with rich feature engineering to cover textual, author, and engagement factors.
Proactive Defenses
Train deep neural networks to detect spam immediately after a post is published. Feed them content-level signals (text features, polarity, potential policy violations) and author-level signals (spam history, reputation). These models run every few hours. If they detect spam, they filter or send the post for human review.
Core Model Formula for a Binary Classifier
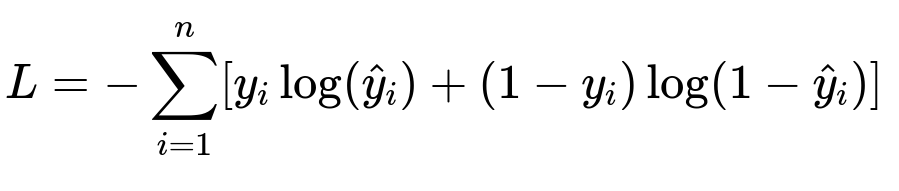
Here, y_i is the true label (spam or not spam), and hat{y}_i is the predicted probability from the neural network. Minimizing this cross-entropy loss helps the model distinguish spam from legitimate posts.
Reactive Defenses
Analyze engagement patterns (likes, shares, comments, velocity over time) with a Boosted Trees model. Monitor a post’s performance. If it looks like it is accumulating rapid interactions, estimate the probability of it being spam. Stop it or slow it if the score is high.
Feature Engineering
Text features determine any forbidden content or high negativity. Author features (connection counts, prior activity) reveal a spammer’s network reach. Engagement features (reaction velocity, comment bursts, share spikes) measure how quickly a post is spreading. Combining these signals captures both the content’s spamminess and its potential for virality.
Implementation Details
Build a pipeline in Python that orchestrates data extraction, model training, and deployment. Use an internal ML platform for training and hosting models. For deep networks, use TensorFlow for feature processing and distributed training. For Boosted Trees, use a library like XGBoost or LightGBM.
import tensorflow as tf
from xgboost import XGBClassifier
# Example pseudo-code for the reactive model
data = load_data()
X = data[feature_columns]
y = data['spam_label']
model = XGBClassifier(
n_estimators=300,
learning_rate=0.1,
max_depth=6
)
model.fit(X, y)
# Predict on new content signals
preds = model.predict_proba(X_new)
threshold = 0.8
spam_flags = preds[:,1] > threshold
These steps showcase how you might assemble the final classifier, decide a threshold, and flag spam.
Monitoring and Impact
Run proactive models every few hours to catch most spam early. Keep reactive models on standby to stop posts that slip through and gain traction. The combined approach can reduce overall spam viewership by a measurable percentage. By removing suspicious content fast, fewer users see it, improving trust and reducing user complaints.
Future Enhancements
Integrate a single consolidated model for faster scoring across different content types. Optimize run times and resource usage. Keep refining the feature set to handle novel spam tactics.
Follow-up question 1
How would you address data scarcity for detecting rare viral spam posts?
A robust solution augments the training data. Curate synthetic spam examples by combining real suspicious text fragments, or by oversampling known viral spam. Use transfer learning from related classification tasks, or add unlabeled data with semi-supervised methods for better representation. Generate negative samples from diverse legitimate posts to keep the model balanced.
Follow-up question 2
How would you mitigate false positives from early-stage posts with limited engagement data?
Build confidence with a multi-step scoring. Assign an initial probability based on content and author signals. Re-check the post as soon as new engagement arrives. If repeated checks confirm a high spam probability, intervene. Use conservative thresholds in the first stage and stricter thresholds later as more data accumulates.
Follow-up question 3
What measures ensure the models adapt to evolving spam patterns?
Retrain frequently. Maintain a feedback loop. Monitor real-world metrics like user reports, growth in suspicious link patterns, or changes in language usage. Introduce an active learning framework that flags uncertain samples for annotation, ensuring the training set stays current.