
ML Case-study Interview Question: Unified Data & Deep Embeddings for Scalable Real-Time Global Recommendations


Browse all the ML Case-Studies here.
Case-Study question
A global-scale online service faced inconsistent product recommendations across regions, which harmed user engagement. They gathered massive multi-modal data from separate data pipelines and wanted a high-accuracy Machine Learning system to predict item relevance for each user. They had to unify disparate datasets, handle real-time inference, and maintain robust performance in production.
Propose a comprehensive approach to ingest and preprocess data, design the model architecture, train and evaluate the model, deploy it at scale, and measure performance. Suggest how to ensure continued improvements over time. Include solution details for advanced feature engineering, system architecture, and handling model drift.
Proposed Solution
Gather all raw logs into a central data store. Build a unified schema that normalizes user events, item metadata, and contextual signals. Map user actions and item descriptions to consistent attribute fields. Parse logs to extract key features such as user history, contextual clicks, and timestamps.
Design feature transformations to encode textual data with embeddings, convert categorical features into numerical representations, and unify the temporal dimension with time-based signals. Store processed features in a feature repository for training and inference. Use consistent data access patterns to avoid training-serving skew.
Train with a supervised pipeline using an embedding-based model that learns item similarity and user preferences. The final layer predicts relevance. For classification tasks, use cross-entropy as the loss function.
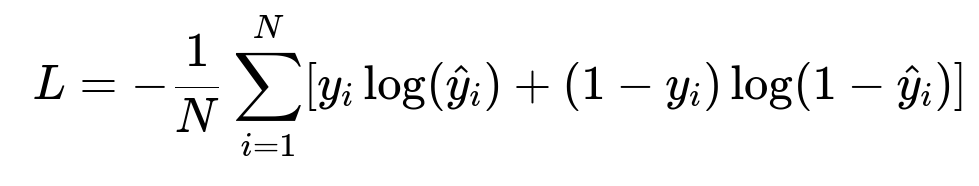
Here N is the total number of samples, y_i is the ground-truth label for sample i, and hat{y}_i is the predicted probability for sample i. Cross-entropy penalizes large deviations from the correct probability and helps calibrate the model output.
Test multiple architectures, including deep networks with embedding layers for user and item IDs, and possibly a Transformer-based model if the text data is large or if sequence order matters. Tune hyperparameters with a validation set. Track metrics such as precision, recall, and mean average precision.
Deploy as containerized microservices using a low-latency model server. Scale horizontally with autoscaling. Maintain a shadow deployment for canary testing. Integrate an A/B testing framework to compare new models against production baselines. If results are positive, shift traffic gradually.
Monitor performance with logs and dashboards. Compare distribution of input features in production to the training distribution. Implement automatic retraining schedules to mitigate model drift. Retain new user feedback signals and continuously improve data pipelines.
Use incremental model updates or real-time streaming pipelines if data changes rapidly. Periodically offline retrain with a full dataset for deeper refinement.
Below is a sample Python skeleton for the training component:
import torch
import torch.nn as nn
import torch.optim as optim
class RecommenderModel(nn.Module):
def __init__(self, user_dim, item_dim, emb_size):
super(RecommenderModel, self).__init__()
self.user_emb = nn.Embedding(user_dim, emb_size)
self.item_emb = nn.Embedding(item_dim, emb_size)
self.fc = nn.Linear(emb_size * 2, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, user_id, item_id):
user_vec = self.user_emb(user_id)
item_vec = self.item_emb(item_id)
concat = torch.cat((user_vec, item_vec), dim=1)
logit = self.fc(concat)
prob = self.sigmoid(logit)
return prob
def train_model(train_loader, model, epochs=10, lr=0.001):
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
model.train()
for epoch in range(epochs):
for user_batch, item_batch, label_batch in train_loader:
optimizer.zero_grad()
preds = model(user_batch, item_batch)
loss = criterion(preds.squeeze(), label_batch.float())
loss.backward()
optimizer.step()
return model
Follow-up Questions and Detailed Answers
How would you handle noisy or missing data in the feature set?
Clean data before ingestion with rules or heuristics for missing values. Use imputation strategies such as mean or median for numerical fields. Treat textual anomalies by defaulting to special tokens or discarding if they are irrecoverable. Include data validation steps in the pipeline to detect anomalies early. Monitor distribution changes and alert if large deviations appear.
How can you ensure your training pipeline remains consistent with your serving pipeline?
Structure ingestion code into a single shared library or service. Reuse feature transformations for training and inference with the same code or artifacts. If you store transformations in a feature repository, ensure that the exact logic is used in real-time inference. Version each pipeline component so you know which transformations align with which model.
How would you deal with model drift in production?
Compare the distribution of user behavior and item attributes over time to historical distributions. Track how well the current model’s predictions match user feedback in real scenarios. Schedule periodic retraining with fresh data. Consider an online learning approach for real-time adaptation if data arrives continuously. Validate new models offline and then online with A/B tests. If performance worsens, retrain or revert to a previous version.
How would you ensure your system can handle large-scale traffic and low-latency requests?
Deploy your model with horizontal scaling. Containerize the serving application and use an orchestration system for load balancing. Keep your inference pipeline optimized by batching requests if possible, or use GPU acceleration for high-throughput tasks. Implement efficient caching for repeated queries. Monitor response times and set up autoscaling thresholds to keep latency low.
How do you handle real-time feature updates?
Use a streaming ingestion framework to capture user events as they happen. Update relevant features in real-time. Maintain a fast cache or key-value store that the model server queries. Structure everything to avoid data freshness delays. If certain transformations are complex, schedule periodic micro-batches instead of pure real-time updates to balance overhead with latency.
Why would you choose a more advanced architecture like Transformers over simpler feed-forward models?
Some user interactions or item content have sequential patterns (e.g., user’s recent browsing history). Transformers handle long-range dependencies and textual features effectively. They capture subtle relationships in user sessions. If the dataset is massive and textual, Transformers often yield better accuracy. Simpler models might be faster but can miss complex temporal or semantic signals. Always validate the added complexity with real performance metrics.
How would you manage ensemble models in production?
Bundle multiple trained models into a unified inference service or orchestrate them behind an aggregator. Each model outputs predictions. Aggregate them by averaging probabilities, weighted scoring, or a meta-learner. Monitor the ensemble’s performance to confirm it justifies additional overhead. If it adds too much latency, consider distilling it into a single model that approximates the ensemble’s predictions.
How do you measure success beyond offline metrics like accuracy or AUC?
Check how the recommendations increase user satisfaction and retention in real-world usage. Track engagement metrics like clicks, conversions, time spent, or user ratings. If the use case involves revenue, measure lifts in sales. Conduct controlled online experiments (A/B tests) to confirm the model’s improvements. If the model runs in a personalized content feed, measure dwell time or skip rates. Combine these metrics for a holistic performance view.
What if you encounter data imbalance during training?
Use methods like oversampling the minority class or undersampling the majority class. Apply class weights in the loss function to emphasize rare classes. Augment data through synthetic techniques if possible. Monitor how these adjustments affect real performance. Evaluate with metrics like precision and recall for each class, especially the minority class.
How do you ensure that the system remains stable when user behavior changes abruptly?
Build a robust pipeline that triggers alerts when input patterns deviate significantly from the training distribution. If an event changes user behavior (e.g., holidays or product launches), quickly collect fresh labels and retrain. Keep a fallback or simpler heuristic-based approach in case your advanced model fails under dramatic shifts. Validate logic with synthetic stress tests that mimic abrupt changes.
How can you reduce training time with extremely large datasets?
Adopt distributed training with frameworks like PyTorch Distributed or Horovod. Partition data across multiple workers and synchronize updates. Use advanced optimizers and mixed-precision training. If the data is too large, sample or do partial training epochs. Profile bottlenecks in data loading or GPU utilization. Optimize your input pipeline for parallel reads and transformations.
How would you ensure reproducibility?
Maintain code, configurations, and metadata in version control. Use the same random seed, environment, and library versions. Store the data snapshot or the exact queries used to generate training data. Log hyperparameters, model checkpoints, and metrics in an experiment tracker. If you re-run training, ensure all versions match. Document everything so that others can replicate your setup.
Why might a custom solution outperform an out-of-the-box managed ML service?
A custom solution gives more flexibility over feature engineering, architecture choice, and optimization techniques. You can fine-tune your system for your unique data distributions and user behaviors. If you have specialized domain constraints or performance needs, custom code can better handle them. Managed services are convenient, but they might limit advanced customizations. Always weigh maintainability and time-to-market against the performance benefits of building in-house.
What regularization methods would you apply?
L2 weight decay and dropout layers help prevent overfitting. If you have embedding layers with high capacity, set a moderate L2 penalty. Monitor validation accuracy to tune these hyperparameters. Early stopping is also common if you see no improvement after several epochs. Keep training logs to confirm that regularization is not hurting performance too much.
When would you prefer an online learning approach?
If user data arrives continuously and distribution shifts occur frequently, an online learning approach updates the model parameters incrementally. This is helpful in recommendation scenarios with ephemeral or time-sensitive patterns. It can adapt quickly, but watch out for catastrophic forgetting of older patterns. Mix streaming updates with periodic batch retraining to keep a global perspective on user history.
That concludes the case-study question, proposed solution, and potential follow-up questions with detailed explanations.