
ML Case-study Interview Question: Explicit User Choice Models for Real-Time, Influential Recommender Systems


Browse all the ML Case-Studies here.
Case-Study question
You are tasked with designing a recommender system for a large online platform. This system must recognize user browsing patterns, offer relevant items, and influence user decisions in real time. The goal is increasing user satisfaction through improved utility while showing measurable uplift in key metrics (clicks, conversions, dwell time, etc.). Traditional offline metrics do not align well with real-world outcomes. The system may need to incorporate explicit user choice models, deal with black-box bandit approaches, or combine both. How would you propose a thorough plan to design, evaluate, and deploy such a system?
Detailed solution
Recommender systems often rely on implicit assumptions about user preferences and decision-making. Making these assumptions explicit clarifies how system changes affect user choices. Building an explicit user choice model helps analyze why a recommendation works.
Modeling user decision-making
Users gather information about products before deciding. Splitting user behavior into a browsing policy and a consumption policy helps. The browsing policy deals with how a user navigates and searches for information. The consumption policy deals with the final decision to buy, stream, or click.
One approach is introducing user types, which are hidden parameters capturing variations in preferences. These types govern how users trade off features or brand loyalty. The system may estimate these types through interaction logs and a Bayesian prior.
Shortcut effect and information effect
The recommender system can speed up user decisions by quickly surfacing relevant items (shortcut effect). It can also highlight new or easily forgotten information to alter user rankings of products (information effect). Shortcut effects reduce user friction. Information effects shift the perceived utility of an item so that a user might pick something they did not initially have in mind.
Incrementality and utility
Incrementality is whether the system genuinely changes user behavior versus a “default” scenario. Explicitly modeling user utility reveals when an item that would otherwise be ignored now becomes a top choice. Items receive positive user utility if they align with user preferences, possibly modulated by newly revealed features or brand reminders.
Potential core utility function
A simple representation of each user’s decision about an item j is:
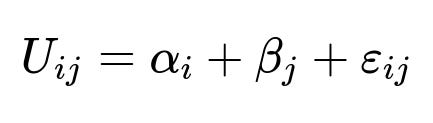
Here:
alpha_i is a user-specific term capturing preference patterns that vary across users.
beta_j is an item-specific term capturing the inherent attractiveness or features of item j.
epsilon_{ij} is a noise term reflecting unobserved factors.
Explaining how the system reveals new information or shortens search steps requires analyzing how alpha_i and beta_j get updated by glimpses of additional data. The user’s final decision emerges from comparing U_{ij} across candidate items. The system influences alpha_i or beta_j by presenting relevant details to the user. If users discover new features or recall forgotten items, the effective utility can shift.
Offline vs. online alignment
Offline metrics like precision-at-k may not capture dynamic user responses. A purely predictive approach might miss how interventions (recommendations) cause changes in user behavior. A bandit approach addresses this by learning from live feedback, continuously refining recommendations to maximize online performance.
However, black-box bandit methods do not explicitly show how user utility changes. They incrementally learn which items yield better immediate rewards (click or conversion), but they do not always interpret why. An explicit user choice model or structured bandit approach can bridge the gap, providing theoretical guarantees and interpretability.
Practical design steps
Designing the system involves:
Building a data pipeline that collects detailed interaction logs (clicks, dwell time, purchases).
Using offline analysis to bootstrap models of alpha_i and beta_j.
Deploying a bandit-based or RL-based algorithm for continuous feedback-driven optimization.
Tracking user-level metrics for incrementality and user satisfaction to confirm that the system’s suggestions align with improved long-term outcomes, not just short-term gains.
Possible code snippet
Below is a simplified Python-like pseudocode for a context-based bandit approach that updates model parameters:
import numpy as np
class ContextualBanditRecommender:
def __init__(self, num_items, context_dim):
self.num_items = num_items
self.context_dim = context_dim
self.theta = np.random.randn(num_items, context_dim)
def recommend(self, user_context):
# Compute expected utility
scores = self.theta.dot(user_context)
item_index = np.argmax(scores)
return item_index
def update(self, user_context, chosen_item, reward):
# Simple gradient update
pred = self.theta[chosen_item].dot(user_context)
error = reward - pred
self.theta[chosen_item] += 0.01 * error * user_context
This system picks an item that maximizes an estimated reward, then updates based on observed feedback (reward). Real-world implementations require more sophisticated exploration strategies, improved feature engineering, and explicit user choice modeling.
Follow-up question 1: How do you handle situations where offline metrics conflict with online A/B test results?
Offline metrics (such as recall or NDCG) assume static data. The moment the recommender system appears on a real platform, user behavior changes. Users see items differently and might click in ways not captured in the training logs. Explicitly modeling user choice helps. The system captures how different features or item placements alter user rankings. When offline predictions conflict with online results, re-check data distribution shifts, confounding factors, and how your bandit or RL agent updates its policy. Evaluate incrementality by comparing user actions under the new recommendation policy vs. the old or a control policy. Investigate large discrepancies by analyzing user segments, verifying model drift, or changing exploration strategies.
Follow-up question 2: How would you incorporate new items or features to keep recommendations fresh?
The information effect addresses surfacing new or little-known items so that users realize they exist. Explicitly track novelty scores, such as how many times a user has seen an item, or how recently an item was introduced. Incorporate exploration signals in bandit updates. If a new item has unknown utility, allocate some probability for the system to recommend it. As user feedback accumulates, the system updates estimates. By representing items as vectors in a learned embedding space, the system can guess how new items resemble known favorites. Any sign that the user might like these new items triggers more exposure for them.
Follow-up question 3: How do you measure the shortcut effect vs. information effect in practice?
Measure the shortcut effect by tracking reduced steps or faster user navigation. In e-commerce, shorter paths to conversion often indicate that users found items without extensive scrolling or repeated searches. Measure the information effect by seeing if new items or items with newly highlighted features get more interactions or sales. One approach is an A/B test comparing a baseline (no additional info) to a variant (extra details or new items surfaced). Statistically isolate the difference in user actions that can be attributed to extra product information. Model the user’s final utility for an item under each scenario. If the user picks an item they originally did not consider, that signals an information-driven change in preference. Both effects might coexist, so a multi-variate test helps disentangle them.
Follow-up question 4: How do you address possible ethical or user experience concerns?
User-centered design ensures the system meets genuine user needs without exploiting attention. Constraining the model to highlight genuinely relevant or beneficial items is crucial. Monitoring user feedback signals any negative outcomes such as excessive interruptions, confusion, or undesired purchases. Setting guardrails, such as capping recommendation frequencies, ensures a balanced user experience. If the platform has multiple parties (merchants, advertisers, etc.), define fairness constraints or ethical policies so that user well-being stays at the forefront.
Follow-up question 5: Why is an explicit user choice model helpful for interpretability?
Black-box bandit solutions can reveal which item performs well but not why. An explicit user choice model breaks down the contributions of user preference, item features, and newly supplied information. Inspecting alpha_i and beta_j clarifies which user segments or item attributes drive conversions. This interpretability helps refine product strategy, debug incorrect predictions, and explain system behavior to stakeholders or regulators. It also fosters trust by demonstrating that the system makes reasoned inferences rather than purely exploiting data correlations.