
ML Case-study Interview Question: Predicting SQL Query Resource Needs with XGBoost and TF-IDF Features


Browse all the ML Case-Studies here.
Case-Study question
A data analytics platform handles massive SQL queries for on-premises and cloud clusters. The team faces issues with large spikes in resource usage. Some queries consume extensive CPU and memory within seconds, overwhelming the cluster. The team needs a robust approach to forecast query resource needs before query execution. How would you design a solution that can predict CPU and peak memory consumption for incoming SQL queries based on historical data, enabling more efficient query scheduling, resource allocation, and cost management?
Proposed solution
System Architecture
The system gathers SQL query logs generated by a large-scale data analytics environment. Each log record includes user details, query statements, CPU time, and peak memory usage. The training cluster processes these logs. Data cleaning and discretization transform continuous CPU time and peak memory values into categories for classification. Models are stored in a central repository. A serving cluster loads these models into a web service, exposing endpoints to predict CPU and memory categories for new queries.
Data Cleaning and Discretization
The cleaning phase removes malformed entries or incomplete records. The CPU time and peak memory usage are converted into discrete labels. Queries below 30 seconds CPU time are labeled low, between 30 seconds and 5 hours are labeled medium, and above 5 hours are labeled high. Peak memory follows a similar strategy. Queries below 1 MB are labeled low, between 1 MB and 1 TB are labeled medium, and above 1 TB are labeled high. This transformation addresses the highly skewed power-law distribution of resource usage.
Feature Extraction
Each SQL query statement is converted into numerical features using bag-of-words and TF-IDF. The bag-of-words approach counts the frequency of terms, while TF-IDF weights terms by how unique they are in the entire dataset. These approaches bypass table-specific metadata and focus on textual patterns in queries.
Model Training
Training data is split into 80 percent for model building and 20 percent for testing. A gradient boosting classifier (XGBoost) fits the categorized CPU and memory data. The main objective function for gradient boosting is shown below.
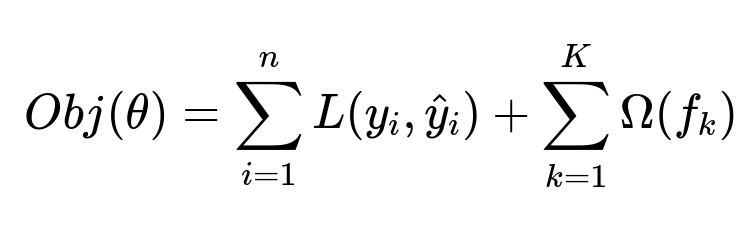
Where:
y_i is the observed label (e.g., low, medium, high CPU usage)
hat{y}_i is the predicted label
L(...) is the loss function for misclassification
Omega(...) is the regularization term for tree complexity
Three-fold cross-validation helps tune hyperparameters. The final model reaches around 98 percent accuracy, with precision and recall above 95 percent even for the high-resource classes.
Model Serving
A RESTful API wraps the trained models, allowing rapid inference at scale. The prediction service runs in containerized environments that can be scaled out by adding replicas. Inference takes about 200 ms per query.
Example Python Snippet
import xgboost as xgb
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
# Example data preparation
queries = [...]
cpu_labels = [...]
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(queries)
X_train, X_test, y_train, y_test = train_test_split(X, cpu_labels, test_size=0.2)
# XGBoost training
model = xgb.XGBClassifier(objective='multi:softmax', num_class=3)
model.fit(X_train, y_train)
This snippet prepares TF-IDF features and trains an XGBoost classifier. Similar steps apply to memory prediction.
How would you handle a highly imbalanced dataset with very few high-CPU queries?
A thorough strategy includes resampling methods, data augmentation, or class weights in model training. Oversampling techniques such as SMOTE or undersampling of the dominant classes can balance the training set. Tree-based models like XGBoost accept scale_pos_weight to mitigate skew. Collecting more samples for rare high-resource queries can also help improve model reliability.
How can you handle real-time inference constraints if model inference time grows under heavy load?
Horizontal scaling addresses sudden spikes by deploying more containers. Model compression, such as knowledge distillation or quantization, reduces model size. Partitioned inference distributes the feature extraction workload. Caching partial results for frequent query patterns also reduces overhead.
What if the queries have frequent changes in syntax or new SQL patterns?
Periodic retraining on the latest logs keeps the model updated. Continuous integration pipelines can trigger model retraining when new patterns are detected. Monitoring precision and recall for newly emerging query patterns flags potential model drift. Online learning or incremental updates can adapt the model on the fly.
How do you ensure that the system remains robust to data quality issues?
Regular data validation checks and anomaly detection tools can spot erroneous log records. Alerts for unusual spikes in CPU time or memory consumption help filter out outliers. Automated rollback to an older model version preserves reliability if newly trained models degrade in accuracy.
How do you handle complex queries that touch multiple datasets with varying statistics?
Text-based features capture partial information, but no table metadata is used. This approach remains engine-agnostic and fast to implement. Expanding the feature space with metadata can boost precision but needs additional cost for metadata lookups. The current method strikes a balance between modeling complexity and inference speed.
How would you extend this to forecast actual numeric CPU and memory values instead of categorical labels?
A regression approach can be adopted by replacing classification with a regression objective. The model would output continuous estimates of CPU time or peak memory. Certain hierarchical or multi-stage techniques might first classify queries into categories (low, medium, high) and then run specialized regressors within each category for finer estimates.
How can you generalize this solution to other resource metrics like disk I/O or network usage?
Log data for I/O or network usage can be discretized similarly. The same TF-IDF feature engineering approach can be applied to the SQL statements. Each resource metric becomes a separate classification or regression target. The architecture remains consistent; only the labels and model outputs change.