
ML Case-study Interview Question: Collisionless Hashing for Scalable Real-Time Sparse Feature Recommendations.


Browse all the ML Case-Studies here.
Case-Study question
You are designing a large-scale real-time recommendation system for a consumer application. Users generate massive interaction data every second. The recommendation pipeline must capture new user feedback instantly. The system must handle extremely sparse and dynamic user/item features to achieve high accuracy. You must address memory constraints, embedding collisions, concept drift, and the need for real-time training updates. How would you design a solution?
Explain in detail:
How to store sparse embeddings without collisions, while keeping memory usage manageable.
How to implement real-time streaming data ingestion and online training.
How to synchronize model parameters with minimal overhead, while ensuring up-to-date predictions.
How to handle fault tolerance without sacrificing too much real-time responsiveness.
Detailed Solution
Collisionless Embedding Storage
Use a hash table that guarantees no collisions. Embed each unique feature ID separately. Insert new IDs dynamically. Evict stale or low-frequency IDs to manage memory.
Adopt a Cuckoo Hashing approach. Maintain two tables T0, T1 with hash functions h0(x), h1(x). Attempt insertion into T0 at h0(x). If occupied, evict the occupant to T1 at h1(occupant). Repeat until all items settle or a cycle triggers a rehash.
Store embeddings as vectors for each ID. Remove inactive IDs after a time threshold. Filter out IDs with very low occurrences. Maintain memory efficiency by periodically cleaning old keys.
Handling Concept Drift With Real-Time Training
Stream interactions and features as soon as they occur. Merge them with user labels in a streaming join step. Sample negative examples to maintain class balance. Update model in small increments.
Produce training examples in near-real-time. Feed them to the online trainer. Push newly learned sparse parameters to the online serving parameter server at minute-level intervals or faster if resources allow.
Keep dense parameters synchronized less frequently. They move slowly because fewer dense updates occur per mini-batch compared to the many sparse IDs. Minimize overhead by pushing dense parameters daily or at suitable intervals.
Parameter Synchronization Logic
Maintain separate training parameter servers (PS) and serving PS. Send only updated sparse embeddings to serving PS. Track touched IDs for each update cycle. Transmit only that subset. Reduce network load by sending incremental deltas instead of copying the entire table.
Accept the possibility of small version mismatches between dense and sparse parts. Observe that stale dense parameters typically do not degrade accuracy by large amounts. Schedule less frequent snapshots for fault-tolerance. Accept that losing part of a day’s update on a single PS has negligible impact given the massive scale and distribution.
Python-Like Snippet
import tensorflow as tf
# Pseudocode for a custom collisionless hashtable resource in TensorFlow
# This is a simplified conceptual snippet for illustration.
class CollisionlessHashTable(tf.Module):
def __init__(self, dim, initial_capacity=100000):
super().__init__()
self.dim = dim
self.capacity = tf.Variable(initial_capacity, trainable=False)
# Hypothetical internal structures for cuckoo hashing
self.keys_1 = tf.Variable(tf.zeros([initial_capacity], dtype=tf.int64))
self.keys_2 = tf.Variable(tf.zeros([initial_capacity], dtype=tf.int64))
self.emb_table_1 = tf.Variable(
tf.zeros([initial_capacity, dim], dtype=tf.float32)
)
self.emb_table_2 = tf.Variable(
tf.zeros([initial_capacity, dim], dtype=tf.float32)
)
@tf.function
def lookup(self, key_ids):
# Stub for cuckoo-lookup. Real code would do collisionless search.
# Return embeddings for the requested IDs.
# Possibly fallback to a "missing key" embedding if not found.
pass
@tf.function
def insert(self, key_ids, embeddings):
# Stub for cuckoo-insertion logic. Evict or rehash if collision.
pass
@tf.function
def remove_stale(self, threshold_time):
# Evict keys that are older than threshold_time or too infrequent.
pass
# Usage in a training step
def training_step(hash_table, ids, labels):
# Get embeddings
emb = hash_table.lookup(ids)
# Forward pass
predictions = my_model_forward(emb)
loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=labels, logits=predictions)
# Backprop
grads = tape.gradient(loss, [emb]) # partial gradient on embeddings
# Insert updated embeddings
updated_emb = emb - 0.01 * grads[0] # simple gradient step
hash_table.insert(ids, updated_emb)
return loss
Explain the design constraints: the table must dynamically grow for unseen IDs while keeping collisions at zero. Use frequency filtering and time-based expiration. Evict inactive IDs. Split parameter updates into frequent sparse pushes and infrequent dense pushes.
Core Model Formula Example
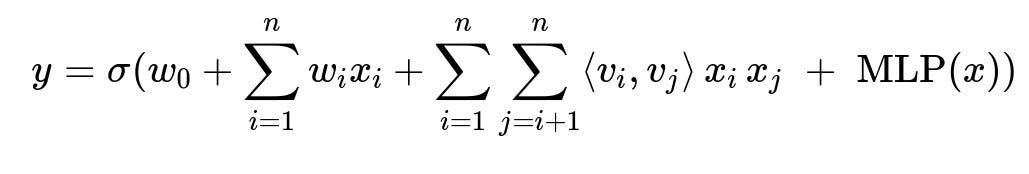
Here y is the predicted probability, x_i is the i-th feature value, w_i is the linear weight, v_i is the embedding vector for feature i, sigma is the sigmoid function, and MLP(x) is a multi-layer perceptron on the same input x. The double sum captures pairwise feature interactions through dot products of embedding vectors.
Putting It All Together
Design real-time ingest with a streaming engine. Join user events with features. Generate training samples. Filter negative samples at a chosen ratio. Update collisionless embeddings on training PS. Push sparse updates incrementally to serving PS at minute-level intervals. Send dense updates daily or at off-peak hours. Snapshot daily. Accept that a failed PS recovers from the previous snapshot. Rely on the small fraction of lost updates producing negligible impact at large scale.
Follow-Up Questions
What if collisions exist in the embedding table for rarely accessed items?
A collision merges distinct embeddings into a shared parameter, degrading model quality. Ensure no collisions for hot IDs. Hash collisions among rare IDs still create confusion in gradients and hamper personalization. Use a collisionless table or expand the table dimension to reduce collision probability. Evict stale IDs. Filter low-frequency keys.
How to manage memory constraints while storing so many sparse IDs?
Filter IDs by occurrence thresholds. Evict stale IDs if they remain unused beyond a cutoff. Compress infrequent embeddings or store them on secondary storage. Avoid storing embeddings for short-lived features. Tune dimension of embeddings for each feature group based on ROI.
Why not synchronize the entire model more frequently for consistency?
Copying multi-terabyte parameters for each synchronization is expensive. Production pipelines need incremental updates. Sparse updates are frequent, but relatively small. Dense variables receive fewer gradient updates per iteration, so daily sync is enough. Minimizing overhead and memory spikes is critical. Slightly outdated dense parameters usually do not hurt accuracy.
How to handle rare but critical events that arrive late?
Keep short-term user features in memory. Write older features to on-disk key-value stores. Retrieve them upon delayed user actions. Accept some limit on retention to preserve memory. Use time windows to decide data staleness. Re-weight or re-sample data in training pipelines for late-arriving signals.
What if the online training pipeline fails and restarts?
Resume from the latest PS snapshot. Rely on short intervals for data ingestion to rehydrate. Maintain replication of Kafka or streaming logs for resilience. Keep a specialized job to catch up on missed updates. Accept minor gaps in real-time feedback. Snapshot the online model daily or at intervals you can handle.
Could partial parameter loss degrade recommendations?
Each parameter server holds a shard of the embedding table. If one fails, only that shard’s update since last snapshot is lost. Overall quality drop remains tiny at the scale of billions of IDs. Sparse updates occur per ID usage, so losing a small fraction of updates is negligible. Users rarely notice a dip.
How to ensure the approach generalizes to other types of sparse features?
Design the collisionless hash table for flexible key-value pairs. Handle user IDs, item IDs, and any categorical or contextual features. Map new features to unique keys at runtime. Filter or expire keys to prevent unbounded growth. Integrate well with any streaming data source. Keep negative sampling or other data balancing strategies consistent.