
ML Case-study Interview Question: Using LLM Opinion Scoring and Vector Search for Alternative Perspective Video Recommendations


Browse all the ML Case-Studies here.
Case-Study question
You are given a platform that provides short videos to a large user base. The platform wants to allow users to explore varied viewpoints on videos or topics they engage with. They plan to add a feature that recommends alternative perspectives tied to each video in the feed. They have an existing multi-stage recommender system optimized primarily for user engagement and video performance. Your task is to create a new subsystem that identifies and ranks videos covering similar topics but offers different or stronger opinions, thus challenging the users’ viewpoints.
Explain how you would design and implement this alternative-perspective recommender. Clarify how you would:
Generate candidate videos that share similar topics or content with the video the user is currently watching or has watched in the past.
Re-rank the candidate videos to emphasize those with different or stronger opinions.
Ensure your system handles large-scale data with low latency.
Measure success and refine the model.
Present your solution with as much technical depth as possible, including how you would handle textual data, embeddings, vector databases, and advanced Natural Language Processing. Outline how you would integrate this module into the existing multi-stage recommender structure. Be ready to answer tough follow-up questions about your approach and potential pitfalls.
Detailed Solution
First, clarify that the existing system already presents a feed of short videos tailored to each user. The new feature requires a two-step approach: (1) candidate generation based on content similarity, and (2) re-ranking to highlight videos with different or pronounced opinions. The overall goal is to push the user outside an echo chamber while keeping content relevant.
Candidate generation starts by converting each video into a text-based representation. Title and description alone might be insufficient, so an automatic speech-to-text model can produce transcripts. After extracting transcripts, use a multilingual sentence embedding model to convert the textual data (title, description, transcript) into vector embeddings. The platform wants to handle vast catalogs, so store these embeddings in a vector database that supports approximate nearest neighbor search.
When a user watches a video, the system quickly retrieves a small set of similar items from the vector database by computing a similarity measure. The most common approach is cosine similarity. In text form, for two embedding vectors A and B:
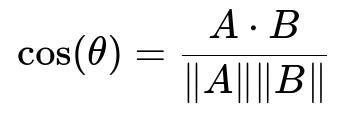
Where A and B are embeddings in a high-dimensional space. A dot B denotes their dot product. The norm of A is the square root of the sum of squares of A’s coordinates, same for B. The closer the result is to 1, the more similar the videos.
A typical implementation includes an approximate nearest neighbor algorithm to query N closest videos. This short list forms the candidate set. Next comes re-ranking. Send each transcript to a large language model that infers an “opinion score” from negative to positive. A zero score indicates neutrality, while more extreme values (positive or negative) imply stronger opinions. The final ranking promotes candidates with stronger or contrasting opinions. Other metadata (freshness, vertical format, etc.) also influences ranking.
Integrating this subsystem into the existing multi-stage recommender ensures the new perspectives appear in specific spots in the user’s feed. Log and track user interactions with these alternative videos. The system can refine itself by tracking watch time, skip rate, or user feedback on whether the alternative viewpoints were valuable.
Implementation Example (Code Snippet in Python)
import numpy as np
import qdrant_client
from qdrant_client import QdrantClient
# Step 1: Connect to Vector DB
client = QdrantClient(host="localhost", port=6333)
# Suppose we already have 'video_embeddings' for each video in the collection
# Step 2: Query the DB to find similar videos
def get_similar_videos(video_id, top_k=10):
# Retrieve the embedding from your local store
embedding = get_embedding_of_video(video_id)
# Use approximate nearest neighbor to find top_k matches
search_result = client.search(
collection_name="videos_collection",
query_vector=embedding,
limit=top_k
)
return [hit.id for hit in search_result]
# Step 3: For each candidate, get an opinion score from LLM
def get_opinion_score(transcript_text):
# Hypothetical function calling LLM sentiment endpoint
# Returns a float in [-1.0, 1.0]
return llm_sentiment_inference(transcript_text)
# Step 4: Re-rank based on opinion score and other criteria
def rerank_candidates(candidate_video_ids):
scored_candidates = []
for vid in candidate_video_ids:
transcript = get_transcript(vid)
opinion_score = get_opinion_score(transcript)
# Example: absolute value encourages stronger opinions
final_score = abs(opinion_score)
scored_candidates.append((vid, final_score))
scored_candidates.sort(key=lambda x: x[1], reverse=True)
return [vid for vid, score in scored_candidates]
This simple outline shows how to integrate approximate nearest neighbor search with an opinion-based re-ranker using external large language model queries.
Follow-Up Questions
1) How do you handle videos that lack quality textual data or have minimal transcripts?
Many videos might have ambiguous titles and short descriptions. The best approach is obtaining transcripts through speech-to-text. If that content is also insufficient or has too many background noises, you might skip these videos for the alternative-perspective feature. Another approach is to maintain partial embeddings based on whatever textual signals you have. In practice, you measure transcript completeness and only include those exceeding a threshold. You also refine your speech-to-text pipeline to handle poor audio quality. If transcripts remain useless, you acknowledge that some videos cannot be matched effectively.
2) Why not use more advanced multi-modal embeddings that incorporate visual content?
Multi-modal embeddings can capture richer contextual signals from both the audio and the video frames. However, they require more processing power and specialized training data. Depending on your infrastructure constraints and product needs, it might be acceptable to rely on textual embeddings alone for speed and simpler pipelines. A multi-modal system is typically more accurate but significantly more costly. For a large production environment, balancing compute cost and model complexity is key. If usage metrics justify it, a multi-modal approach could be revisited later.
3) How do you manage the risk of recommending extreme or harmful content?
An opinion-based system could inadvertently push harmful or overly extreme viewpoints. Mitigate this by building policy filters. Before re-ranking, you exclude flagged topics. You can also incorporate toxicity classification or content moderation. The system should incorporate a global safety net that blocks or demotes content with hate speech or dangerous misinformation. Over time, you refine these filters, monitor user reports, and track unexpected emergent patterns.
4) How do you measure the success of this new subsystem?
You track metrics like click-through rate on alternative perspectives, user watch time for recommended contrasting content, and user feedback (likes, shares, or explicit sentiment). Observe if the feature leads to broader content consumption without dropping user satisfaction. You can also run A/B tests: one group sees the new perspective feature, the other sees the baseline. Compare differences in retention, session length, and reported user satisfaction. If users remain longer, watch more varied content, or provide positive feedback, you know it is working.
5) How do you ensure real-time performance for large-scale traffic?
Vector databases like Qdrant, FAISS, or similar approximate nearest neighbor solutions are optimized for millisecond-level query latency even at scale. Hosting them on robust infrastructure with GPU acceleration can help. You also cache popular video transcripts and embeddings. For real-time opinion scoring, you batch LLM requests or pre-compute them if transcript text is static. If you must compute them on the fly, maintain a small concurrency-based microservice to handle bursts. You can also limit re-ranking computations to only those videos that have not been previously scored.
6) How do you make sure the system generalizes to many languages?
The embedding model should be multilingual. Similarly, your speech-to-text pipeline must handle multiple languages and dialects. Your sentiment analysis pipeline or large language model should also support those languages. Having a fallback for unsupported languages (e.g., skipping the alternative-perspective feature) could be necessary. You consistently evaluate how well each language is processed. If performance is poor for certain languages, consider specialized local models or improved training sets.
7) If the system inadvertently recommends content reinforcing the same viewpoint, how do you fix it?
You first detect repetition by analyzing the aggregated opinion scores. If recommended videos have opinion scores all leaning in the same direction, you intervene. One approach is to re-rank in favor of variety by introducing a penalty if too many candidates share a similar sentiment. Another approach is to blend content from different sentiment buckets. Continually track how frequently identical or near-identical perspectives appear, then adjust your weighting logic.
8) What if real-time LLM calls become expensive or too slow?
It helps to pre-compute opinion scores for a large portion of the library. Videos often have static transcripts, so you can store each opinion score in a database. When a user requests alternative perspectives, your system does not need to compute new scores. Instead, it retrieves and re-ranks them using already cached scores. You only recompute if the transcript changes or if you have new content unscored by the pipeline. This approach allows near-instant responses.
9) How would you tweak your design if you wanted to combine this with collaborative filtering signals?
You can add a collaborative filtering component by factoring in user similarity or channel subscriptions. For instance, you might weigh whether other like-minded users watched and enjoyed these alternative videos. You could incorporate that signal into your final ranking. If user-based or item-based collaborative filtering is strong in your ecosystem, you can linearly combine it with the opinion-based rank or you can feed it into a learning-to-rank model that includes both content similarity and user similarity as features.
10) Can you integrate bandit algorithms to optimize the new subsystem?
Yes. You can treat each recommended video as an arm in a bandit framework. When you serve the user an alternative video, you learn from the user’s engagement (or non-engagement). Over time, the bandit can adjust its exploration-exploitation balance by rewarding items that produce stronger user interaction. If you integrate bandits, you must keep track of each item’s reward (like watch time or like rate) and constantly update the selection policy to highlight the best-performing alternative perspectives.
That concludes the case-study, detailed solution, and follow-up explanations.