
ML Case-study Interview Question: Enhanced Spam Call Detection via Semi-Supervised Audio Preamble Removal


Browse all the ML Case-Studies here.
Case-Study question
A real-estate rentals platform receives thousands of phone messages from prospective renters to property managers. Spammers are abusing these phone lines with automated or scam calls. The team has only a few labeled spam samples, but they possess large amounts of unlabeled phone recordings. The objective is to build a machine learning system that detects and blocks spam phone calls. The platform’s existing text-based spam classifier performs poorly if the call recording is transcribed verbatim (including automated menu prompts, voicemail greetings, etc.). Removing these “preamble” segments before transcription boosts spam detection. Propose an end-to-end system that automatically identifies and removes the preamble from audio, then transcribes the remaining message and classifies it as spam or not spam. Explain how to handle the limited labeled samples, how to incorporate large unlabeled data, how to structure the model pipeline, and how to evaluate performance.
Detailed solution
Overview
Large unlabeled audio recordings are leveraged with a semi-supervised strategy. Few labeled samples of phone calls are available. A specialized preamble detector removes extraneous audio at the start. The rest is transcribed, then passed to a text-based spam classifier. The preamble detector learns from both labeled and unlabeled data, using a self-supervised pretraining step on large audio corpora, followed by switch point regression with the small labeled set.
Audio processing
Raw audio is recorded at 22.05 kHz. Short calls under five seconds are discarded. Longer calls are trimmed or padded to 240 seconds. Mel Frequency Cepstral Coefficients (MFCC) are extracted from each audio sample. Each MFCC is up to 2584 x 20, where each window captures 93 ms of audio.
Self-supervised feature encoder
A CNN-Transformer encoder compresses the MFCC input by a factor of four. A convolution layer maps MFCC frames to latent embeddings. A stack of transformer blocks with multiple attention heads captures contextual relationships. The model is pretrained using a masking approach, predicting masked MFCC frames to minimize mean squared error.
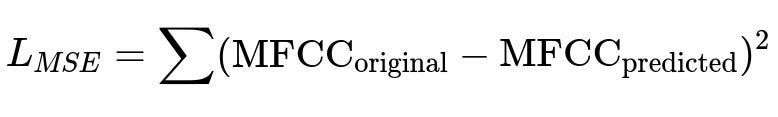
L_MSE is minimized over masked regions of unlabeled audio. The encoder learns general representations without many labeled samples.
Switch point regression
The encoder output is a sequence of latent feature vectors. A multi-stage model identifies the boundary between preamble and real message content. The framewise classifier computes the probability of “voice content” for each frame. A dynamic programming algorithm proposes candidate switch points from the probability sequence. A whole-segment classifier (boosting-tree-based) then scores each candidate to find the best boundary.
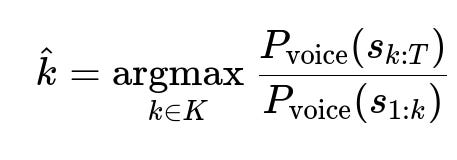
Here k is a candidate switch point, s_{1:k} is the score segment before k, and s_{k:T} is the segment after k. The boundary with the maximum ratio is chosen.
Text transcription and spam classification
An off-the-shelf speech-to-text model transcribes the trimmed audio (after removing the preamble). The resulting text is fed into a pretrained RoBERTa-based spam classifier. That classifier has already learned text spam patterns from email/SMS data, so minimal labeled phone spam is needed.
Performance
Evaluation compares accuracy with and without removing preambles. Removing preambles reduces false negatives. The system’s preamble detector achieves median absolute switch point errors of under one second, improving the text-based spam classifier’s precision and recall.
Follow-up question 1
How would you handle a scenario where many preambles and voice segments are interspersed (for example, multiple automated prompts within a single call)?
A multi-segment approach is needed. The model must locate each transition from preamble to voice. The same pipeline extends to multiple switch points. The dynamic programming step can propose several breakpoints. Each candidate boundary can be checked with the whole-segment classifier. The final segmentation might consist of repeated calls to the procedure for each segment. Large preamble segments can be removed piece by piece. If transitions exist mid-call, the region outside real content is excluded before transcription.
Follow-up question 2
Why is self-supervised pretraining beneficial in this low-label setting?
Self-supervised pretraining uses abundant unlabeled audio to learn general representations. The model sees diverse phone calls with various patterns (preambles, voices, background noise). This builds robust embeddings without needing explicit labels. The small labeled set then fine-tunes only the parts needed for switch point detection. This data efficiency reduces overfitting, which would be severe if training a model from scratch on limited labels.
Follow-up question 3
How does the dynamic programming approach differ from a direct regression to predict the switch point?
Directly regressing a single switch point in one shot overlooks the local structure. The dynamic programming algorithm partitions the score sequence into segments that minimize a chosen cost. It proposes multiple candidate boundaries, addressing the uncertainty in complex sequences. The subsequent re-ranking with the whole-segment classifier refines predictions. A pure regression approach often leads to higher error because it treats the entire sequence as a single continuous label, rather than analyzing local changes.
Follow-up question 4
Why use a boosting tree for the whole-segment classification?
A boosting tree such as CatBoost handles tabular features (score distributions, local context) well. The labeled set is small, and boosting trees often excel in low-data regimes compared to neural networks. The tree quickly captures nonlinear patterns in the probability sequences. Integrating neural embeddings with a tree-based classifier is practical and yields improved performance over a single neural architecture.
Follow-up question 5
What are key challenges in production deployment?
Call audio may vary by user hardware, phone carriers, call lengths, and background noise. The pipeline must handle broad distributions. Real-time inference may require faster or more compressed models. Speech transcription must handle noisy speech. Model drift can occur if spam strategies evolve. Regularly sampling fresh calls and retraining is necessary, possibly using active learning to prioritize uncertain calls for labeling.
Follow-up question 6
How would you reduce Whisper’s tendency to hallucinate extra speech in silent segments?
A custom post-processing step can filter out suspicious transcripts or enforce thresholds on silence detection. The preamble detector’s timestamps can help. Sections with near-zero energy or no voice-likelihood can be removed. Language constraints (such as known valid words or typical domain-specific patterns) can further eliminate implausible text. Fine-tuning Whisper on in-domain phone call data, if feasible, can also help.
Follow-up question 7
How do you ensure robust performance in multilingual contexts?
A multilingual model is needed for transcription. The self-supervised encoder can be trained on multilingual phone calls to capture universal audio features. Labeled samples in multiple languages or domain-specific data enhance the fine-tuning steps. The text-based spam classifier must also be language-aware or replaced with a multilingual language model. Alternatively, language detection can route calls to the correct language-specific pipeline.
Follow-up question 8
What active learning strategies might improve this system over time?
An uncertainty sampling approach requests human labeling for calls where the model is least confident about switch point location or spam classification. Additional strategies involve diversity-based sampling that ensures coverage of various call types. Periodically retraining the model with fresh labels reduces drift. Over time, the system’s accuracy improves while still relying on minimal labeling effort.
Follow-up question 9
How would you address potential user privacy concerns when recording phone calls?
User consent is essential. Clear privacy policies and disclaimers must be in place. Partial redaction or on-device transcription can be considered. For legal compliance, data encryption, role-based access, and usage logs are mandatory. The system can store only embeddings or hashed representations instead of raw audio. Privacy-preserving techniques like federated learning might also be explored to keep raw data off central servers.