
ML Case-study Interview Question: Causal Machine Learning for Personalized Metered Paywalls: Optimizing Engagement and Conversion.


Browse all the ML Case-Studies here.
Case-Study question
A major digital publisher with a strong online subscription model wants to optimize its paywall. They have a metered paywall that lets non-subscribed, registered users read a fixed number of free articles each month before seeing a subscription offer. The company wants to personalize this meter limit for each registered user to maximize both engagement and subscription conversions. They have first-party data on user engagement, as well as a randomized control trial dataset in which different users received different meter limits. How would you propose a complete solution approach, focusing on causal machine learning to determine personalized meter limits, while balancing multiple objectives (readership engagement and conversions), and also ensuring fairness and privacy?
Proposed Solution
Causal machine learning is key because the goal is to prescribe an action (meter limit) and then measure its effects (subscription likelihood and continued engagement). A prescriptive model uses past data from a randomized control trial to learn which meter limit optimally balances conversions and engagement. The data contains user features derived from reading activity and a treatment variable representing the meter limit each user received during the trial. A model learns how each user’s outcome would change if they had received a different meter limit.
Training two separate base models can capture two distinct targets: one model predicts subscription propensity, and the other predicts engagement. Represent the subscription propensity as p = f(X, T) and the engagement as e = g(X, T), where X denotes user features and T denotes the meter limit treatment. Both outcomes depend on T in potentially different ways. Combining these outcomes into a single objective s that includes a friction parameter delta (0 <= delta <= 1) allows a trade-off between conversions and engagement. A simple approach uses a convex combination:
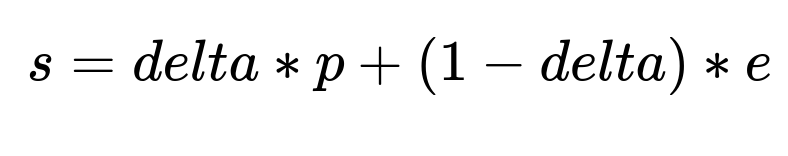
Choosing delta close to 1 prioritizes conversions, whereas choosing it closer to 0 prioritizes engagement. The final prescription policy for each user picks the meter limit T that maximizes s over the set of possible meter-limit treatments:
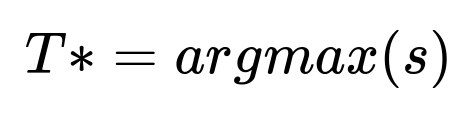
Where T* indicates the best meter limit for that user.
Model Testing and Backtesting
Testing on historical data requires careful design. A backtest procedure only examines users for whom the model’s chosen treatment matches the random assignment in the past. That subset’s observed outcomes can then approximate how the entire cohort might have behaved under the model’s choices. An inverse probability weighting estimator aggregates individual outcomes and corrects for the different probabilities of assignment in the randomized control trial:
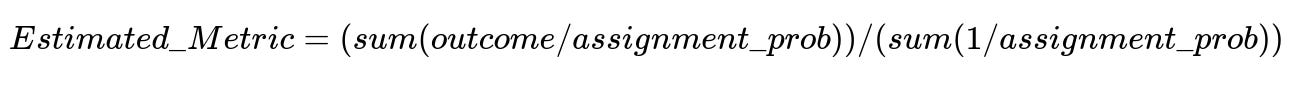
Using this procedure for both the conversion rate and average engagement yields an estimate of the model’s performance across varying values of delta. The resulting Pareto front indicates the trade-off curve between conversions and engagement. This flexible approach lets decision-makers pick a specific operating point that suits business goals.
Practical Implementation
Machine learning pipeline steps include feature engineering, model selection (e.g., gradient boosting or neural networks), hyperparameter tuning, and model calibration. A typical implementation in Python might load the dataset, split it into training and validation sets, and train two distinct models:
import pandas as pd
import numpy as np
from sklearn.ensemble import GradientBoostingRegressor
data = pd.read_csv("meter_limit_experiment_data.csv")
# X includes user features
# T is the meter-limit group (categorical or numeric)
# y_sub is a binary indicator for subscription
# y_eng is the measured engagement
# Train subscription model
sub_model = GradientBoostingRegressor()
sub_model.fit(data[["feature1","feature2","T"]], data["y_sub"])
# Train engagement model
eng_model = GradientBoostingRegressor()
eng_model.fit(data[["feature1","feature2","T"]], data["y_eng"])
# Predictions for each user, for each possible meter limit
# Then pick the meter limit that maximizes the combined objective s
Deployment requires intercepting user requests, extracting user features, and producing an immediate decision about how many free articles remain. It also requires real-time logging of outcomes to facilitate iterative model re-training.
Fairness and Privacy
Features should exclude sensitive demographic data. Avoid any group-level discrimination by relying on user behavioral signals. Randomized evaluation ensures that the model does not systematically deny or grant extra free articles to protected classes. Encrypted storage of user activity logs protects user privacy.
What is the difference between a prescriptive model and a purely predictive model?
A purely predictive model estimates what will happen. For instance, it might predict how many articles a user will read if given a particular meter limit. A prescriptive model goes further by computing the optimal action to take, based on how changing the action affects the outcome. Prescriptive models aim to select the best decision for each user rather than only forecasting an outcome.
How do you handle the missing data problem in causal inference?
Randomized control trial data is crucial. Each user is assigned a specific meter limit at random, so there is no direct observation of the user’s behavior under alternative assignments. Causal inference methods approximate these unobserved counterfactual outcomes from similar users who received the other treatments. This approach relies on the assumption that the trial assignment is random, which controls for confounding variables.
How do you decide on the correct value of the friction parameter delta?
Business context and experimentation guide this choice. If the organization’s near-term objective is higher conversion, pick a higher delta. If growing readership is the priority, pick a lower delta. Evaluate outcomes along the entire Pareto front to see how engagement changes as you adjust delta, then select a point that best balances both goals.
How can you ensure robust evaluation before a large-scale deployment?
Repeated backtests and online experiments help validate the model. Backtests simulate performance on historical data, while online experiments (e.g., A/B tests) can confirm real-world impact. Testing smaller segments first minimizes risk. Monitoring key metrics after launch ensures the model behaves as expected. If performance degrades, quickly roll back or retune.
How do you maintain and update this system over time?
User behavior changes with new products and content. Monitoring data drift in user engagement patterns or subscription trends is essential. Re-train on newer data to incorporate the latest user activity. Frequent iterative updates keep the model aligned with current business goals.
How do you address long-term user habituation in such a system?
A user who consistently receives a high meter limit might form a habit of reading many free articles without subscribing. A user who receives a very tight meter might be turned away. Tracking each user’s behavior over time helps the system shift to a more optimal balance. Including features that capture long-term reading patterns helps avoid negative habituation effects.
How would you engineer new features that might improve the model?
Consider time-based features such as frequency of article views per day, recency of last visit, or categories of content viewed. Capture session length or device usage patterns. Monitor changes in consumption after hitting the paywall. Seek uncorrelated features that add true signal rather than duplicating existing data.
How do you see this approach generalizing to other digital products?
Any digital product that must decide how much free access to offer before gating content can apply a similar method. Prescriptive causal models help decide who should see friction and when. The key is having randomized data and clearly defined objectives. Engagement, conversion, or churn targets can all be integrated into this multi-objective framework.