
ML Case-study Interview Question: Predictive Test Optimization: Faster Feedback & Defect Routing with Machine Learning.


Case-Study question
You lead a project in a large-scale enterprise with thousands of automated tests running daily. Multiple teams work on overlapping code modules. Test runs can take hours, and developers wait for critical feedback. Some tests rarely fail, and some fail often but unpredictably. Engineers also struggle to assign new defects to the correct team. Propose an end-to-end data science strategy to reduce test feedback time, reorder long-running test suites for faster detection of failures, predict failing tests without running them all, and automate the routing of new defects to the right team. Describe your solution architecture, model training details, data ingestion approach, and how you handle scaling. Show how you evaluate your predictions, ensure data quality, and integrate the system into a continuous integration pipeline.
Detailed solution
Data ingestion and linking
Collect version control data (commits, timestamps, authors), test logs (pass/fail status, timestamps, affected modules), and defect tracking data (defect ID, team assignment, resolution details). Store these in a unified database or data lake. Keep strict linkage between commits and test outcomes. Include metadata on each test’s coverage area so you can correlate failing tests with the code sections that changed.
Model training for pass/fail prediction
Train a supervised classification model that takes commit metadata (changed files, commit frequency, developer ID) as inputs. Label each training example with the test’s pass/fail outcome from historical runs. A decision tree classifier or gradient boosting method can work well. Accuracy is a key metric. One useful measure is shown below.
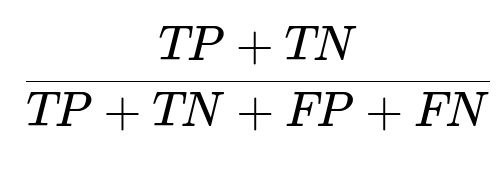
TP are true positives, TN are true negatives, FP are false positives, and FN are false negatives in predicting pass/fail. Use cross-validation over past data to tune hyperparameters. If results are stable, deploy the model so it can quickly predict which tests are likely to fail given a fresh commit.
Reordering test suites
After predicting pass/fail probabilities, sort tests in descending order of likely failure. Run the top few at higher priority. Early failures save time by terminating or pausing the suite. This approach reduces total test runtime. Track actual pass/fail outcomes to improve future predictions.
Automating defect assignment
Analyze which team last fixed defects that shared similar failing tests or files. When a new defect appears, find matching historical defects. If a particular team corrected most of these before, assign the defect to that team or highlight the top three teams. This reduces guesswork and ping-ponging of defects.
Scaling and deployment
Ingest data through a multi-container pipeline that parses logs and version control events in parallel. Train models on scalable infrastructure. Expose inference through REST endpoints. Ensure real-time or near real-time predictions. Use job schedulers or message queues to coordinate data ingestion. If volume spikes, replicate containers to handle load.
Organizational adoption
Developers want transparency. Show them how predictions are generated and how often they are right. Offer an integrated plugin or command-line tool so they can see potential failing tests right away. Provide them with a fast feedback loop to confirm or correct predictions. Make sure data pipelines remain reliable, with robust monitoring to catch ingestion errors.
Example Python snippet
from sklearn.tree import DecisionTreeClassifier
import numpy as np
# X is a matrix of features derived from commits (file_changes, developer_id, etc.)
# y is a binary array of pass/fail outcomes
X = np.load('features.npy')
y = np.load('labels.npy')
model = DecisionTreeClassifier(max_depth=10, min_samples_split=5)
model.fit(X, y)
# Predict pass/fail for a new commit (x_new)
prediction = model.predict([x_new])[0] # 0 for pass, 1 for fail
This snippet trains a simple decision tree on preprocessed data arrays. Integrate it into a larger system that fetches commits, extracts features, and retrains regularly.
How do you choose features to improve prediction?
Analyze historical test failures and commits to see which attributes correlate strongly with fails. File paths, commit size, frequency of changes in certain modules, developer ID, test complexity, or coverage region can reveal patterns. Create binary or numeric features from each. For example, consider the count of lines changed in a given module or how often a developer’s changes triggered test failures in the past. Validate feature effectiveness through ablation tests, removing features to see if accuracy drops.
How do you handle flaky tests?
Mark tests that fail intermittently on identical code. Track their fail/pass pattern across many runs. If a test flips outcomes repeatedly, lower its influence in training or tag it as flaky so its predictions do not skew the model. Investigate underlying stability issues.
How do you ensure data quality at scale?
Monitor ingestion pipelines. If logs stop arriving or version control metadata is incomplete, alert engineers. Validate all records have necessary references (commit IDs, test IDs). Reject or flag invalid data. Keep backups. Maintain consistent data schemas with robust definitions for each field.
Why not run fewer tests altogether?
In some cases, skipping rarely failing tests can shorten runtime. However, removing them entirely risks missing regressions. Instead, keep them at a lower priority or batch them less frequently. If the model’s confidence for pass is extremely high, set that test aside to run later only if resources allow.
How do you integrate with continuous integration systems?
Create a plugin or service that triggers after each commit. It retrieves feature data for the commit, queries the model for fail likelihoods, then reorders test execution. Provide a fast pass/fail likelihood for immediate feedback. If a test is predicted likely to fail, run it first. If it fails, the pipeline fails early, saving compute time and developer cycles.
How do you handle user trust and continuous improvement?
Show metrics on model accuracy over time and highlight examples of correct and incorrect predictions. Let developers override predictions. If the model is frequently wrong, investigate data drift, new code paths, or outdated training data. Retrain models on updated commits. Use user feedback to refine mislabeled or misassigned data.