
ML Case-study Interview Question: Scalable Visual Classification for Diverse Documents Without Text Analysis.


Case-Study question
You are working at a large platform that hosts a massive repository of user-uploaded documents. These documents vary widely in structure (text pages, comics, sheet music, tables, and more). Many are multi-page and can contain different page types. Your goal is to build and deploy a multi-class document classification system that relies on visual features only, without relying on text. The system must process millions of documents quickly. How would you design the training data pipeline, model architecture, and inference approach to classify documents into their correct categories (such as text-heavy, spreadsheet-like, sheet music, comics, and an “other” category), and how would you handle out-of-distribution data and overconfident predictions?
Detailed Solution
Data Gathering and Page-Level Labeling
Documents can contain pages of multiple types. Using entire document labels for training a page classifier would introduce noise if some pages differ from the overall label. Gathering labeled pages is essential. An active learning loop can start with a small hand-labeled set of pages for each category. A binary classifier for each category is trained, then inspected for uncertainties and misclassifications. Additional labeled examples that address any misclassification biases are added. This iterative process yields clean page-level labels.
Handling Multi-Type Documents
Documents often mix page types. Page-level classification is the first step. Each page is fed into a visual classifier to predict its type based on patterns such as text density or presence of horizontal lines. With large-scale data, focusing on visual cues avoids language dependencies.
Training the Page-Level Classifier
Transfer learning on a convolutional neural network pre-trained on ImageNet provides a strong initialization. Models like ResNet or DenseNet can yield good accuracy but might be too large for fast inference. A smaller architecture, such as SqueezeNet, balances performance with low inference cost. Lightweight models train faster, permitting end-to-end retraining instead of mere feature extraction.
Ensembling Pages into a Document Label
Page-level predictions can be aggregated for the entire document by sampling a small set of pages (for example, 4) and combining the classifier’s probabilities. This ensemble approach is a strong baseline. Additional metadata (page count, aspect ratio, word count) can help, but simple averaging of page predictions frequently matches or outperforms more complex approaches when page sampling is representative.
Managing Overconfidence
Some documents trigger overconfident but incorrect predictions. This undermines threshold-based precision improvements. An explicit “other” category helps reduce false positives. Incorporating suspicious or out-of-distribution pages into “other” during retraining curbs overconfidence for known classes. For specific classes that still yield overconfident errors, dedicated binary classifiers improve precision.
Example Core Formula
Below is a standard multi-class cross-entropy loss formula applied when training a classifier:
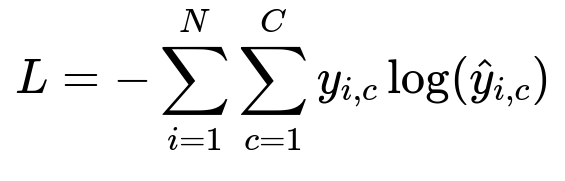
Here, N is the total number of examples, C is the number of classes, y_{i,c} is the ground-truth indicator for example i in class c, and hat{y}_{i,c} is the predicted probability.
Implementation Example in Python
import torch
import torch.nn as nn
import torch.optim as optim
# Example SqueezeNet-based classifier
model = torch.hub.load('pytorch/vision:v0.10.0', 'squeezenet1_0', pretrained=True)
# Replace final layer with custom classifier for our classes
model.classifier[1] = nn.Conv2d(512, 6, kernel_size=(1,1), stride=(1,1))
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
# Example training loop sketch
for epoch in range(num_epochs):
for images, labels in dataloader:
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
Training is repeated until convergence. Then the classifier’s softmax outputs are combined across sampled pages in each document.
Future Steps
Further refinement includes specialized extractors for specific types (sheet music, spreadsheets, etc.), using the page-level classification as a filtering step. Thorough sampling is critical for documents with thousands of pages. Identifying rare out-of-distribution examples remains an ongoing process that must adapt as new documents appear.
What if the interviewer asks...
How to handle multi-label scenarios if a single page has two overlapping characteristics?
Explain that the system would require a multi-label approach instead of a single-label approach. One strategy is to replace the classifier’s output layer with multiple independent sigmoid outputs. Each output targets a specific attribute. This demands an adapted loss function, such as a multi-label version of cross-entropy. Data annotation would need page labels that permit multiple tags per page.
Why rely on visual cues only rather than text-based features?
Mention that visual features avoid language dependencies, which is critical for a corpus with diverse languages or non-textual content. Vision-based models can identify structural cues (tables, sheet music lines) that might not be obvious from text extraction. Also, many documents might have poor Optical Character Recognition results due to low resolution or unusual fonts.
How to optimize inference for millions of documents?
Discuss distributing page-level classification across multiple workers or servers. Mention caching intermediate page representations. Suggest a smaller resolution input if domain tests show minimal accuracy drop, plus storing model weights in an optimized format. Batching pages for GPU processing can accelerate throughput. Consider a multi-stage pipeline that only applies the page classifier to a small sample of pages per document.
Why add an “other” category instead of only known classes?
Clarify that real-world uploads can contain novel structures or extremely rare formats. A forced classification can cause many misclassifications. “Other” allows the model to learn a boundary that captures anything not resembling the known classes. This reduces overconfident errors and leaves room for future expansions or specialized modules.
How to mitigate overconfidence more thoroughly?
Discuss calibration techniques such as temperature scaling, where the model’s logits are adjusted to better match true probabilities. Explain that training with additional out-of-distribution examples in “other” helps the model learn a broader feature space. Stress test the model with adversarial examples (like text pages that mimic sheet music lines) to refine the “other” boundary.
Strategies for iterating if a model misclassifies pages?
Mention that active learning remains central. Examine incorrectly predicted pages, add them to a training set that highlights the confusion, and retrain. Track false positives and false negatives for each class to maintain balanced improvements. Revisit architecture choices if consistent pattern-based misclassifications appear. Regularly analyze confidence distribution to spot drift over time.