
ML Case-study Interview Question: Scalable Machine Learning for Dynamic Retail Pricing and Profit Optimization


Case-Study question
A large retail chain with thousands of stores across North America wants a dynamic pricing algorithm to set in-store prices for hundreds of millions of product-store combinations. They aim to maximize profit while maintaining a brand strategy that emphasizes consistently low prices. There are constraints around how often these prices can be updated, as frequent changes involve added labor costs and potential consumer backlash. The chain competes with strong online retailers that change prices often, so the algorithm must adapt to competitor data, seasonal factors, and real-time inventory conditions. How would you design and implement such a pricing algorithm to handle these massive scale requirements and evolving market demands?
Detailed solution
Problem framing
There are about 5,000 stores, each carrying approximately 100,000 items. That implies about 500 million price recommendations each time the algorithm runs. Changing prices too often is costly. Updating them too infrequently can lose competitive edge. The primary business goal is profit maximization. The brand prefers stable prices, so big fluctuations can hurt brand perception.
Basic supply and demand formulation
The profit for an item is computed as the difference between its selling price and cost, multiplied by the demand at that price. This is captured by:
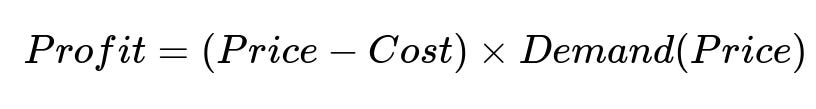
Here, Price is the per-unit retail price, Cost is the per-unit procurement cost, and Demand(Price) is a function representing how many units will be sold at that price.
Linear demand curve approach
Demand often decreases when price goes up. A linear regression model that predicts demand as a function of price can approximate this relationship. The coefficient for price indicates how elastic or inelastic the product is. A larger negative coefficient means more sensitivity to changes in price. Luxury or prestige goods can sometimes display positive relationships, but most household essentials and groceries will have negative demand-price relationships.
Assuming each product’s demand pattern is stable, historical sales data and previous price points are used to fit a separate linear regression for each product. For instance, item demand_{i} = a - b * price_{i}, where b is the price-sensitivity coefficient. The algorithm finds the price that yields the maximum (price - cost)*demand. This works if each product is modeled in isolation.
Limitations of the simple approach
Simple linear regression does not capture interactions between items. Changing the price of one item can cannibalize the sales of related items. It also ignores location-specific differences. Consumer preferences in urban areas may differ from those in rural areas. Some goods, especially perishable items, require faster clearance pricing. A single elasticity-based model may oversimplify real-world complexity.
Black-box modeling and additional data
Adding more features can improve accuracy. These may include:
Item details like category, shelf placement, product size.
Competitor prices from large online retailers or nearby physical stores.
Inventory levels to ensure items do not remain unsold too long.
Seasonality to capture spikes or drops during holidays or off-seasons.
Store-level factors to account for local tastes or promotions.
Large-scale machine learning methods (gradient boosting or neural networks) can handle these multi-variate inputs. They learn complex interactions among features, potentially capturing cannibalization effects and location-based patterns when given the right historical training data.
Handling brand strategy and update frequency
Prices cannot oscillate wildly or daily in most store locations because it conflicts with a stable low-price reputation. A compromise might be a small set of strategic price adjustments per product: an initial everyday price, an intermediate discount, and a final clearance price if necessary. This reduces operational overhead but still allows responsiveness to changing market conditions.
Testing and measuring impact
Deploy an A/B test by choosing two comparable sets of products. Keep one set priced under the legacy or simpler strategy, and have the other set priced under the new dynamic model. Measure profit lift, revenue differences, and inventory turnover. Avoid mixing products that strongly influence each other’s sales in the same group vs. control to prevent cross-contamination. Wait through several inventory cycles to gather stable performance metrics.
Practical implementation details
Distributed computing pipelines (e.g., Spark or other large-scale batch frameworks) handle the daily or weekly model training and prediction updates. Training sets contain historical sales data, competitor price data, and store-level context. The resulting model(s) generate recommended prices. A separate rules-based layer enforces constraints on maximum allowable price changes or ensures alignment with brand guidelines.
Follow-up question 1
What are the main computational challenges when generating 500 million price predictions regularly?
Explanation
Running complex models for hundreds of millions of items can be time-intensive. Distributed systems are essential. Partition the data by store or region. Scale horizontally with multiple computing nodes. Use efficient model inference techniques such as batch scoring or specialized ML frameworks that can handle large-scale scoring. Caching intermediate results and carefully optimizing data pipelines can reduce both time and cost.
Follow-up question 2
How do you factor in seasonal products and perishable goods?
Explanation
Integrate seasonality variables such as month, holiday indicators, and local weather data into the model. For perishable items, track shelf life in the inventory data. Increase discounting rates as items approach expiration. If a product is highly seasonal, weighting recent seasonal data more strongly helps. Some items may only sell around certain holidays, and historical data from the same period in previous years can improve predictions.
Follow-up question 3
What is your approach to measuring price elasticity in practice?
Explanation
Fit a regression or similar predictive model on historical price and demand. Use the price-related coefficient to interpret how changes in price affect units sold. Segment items by category and region to confirm if derived elasticities make sense (e.g., essential groceries may have lower elasticity). Compare elasticity estimates across similar products to spot anomalies. If an elasticity for a basic staple appears too large or positive, investigate potential data or modeling errors.
Follow-up question 4
How would you ensure you do not degrade the brand’s positioning while still maximizing profit?
Explanation
Define rules to keep day-to-day price changes below a certain threshold. Restrict the number of times prices can be updated within a given timeframe. Use a tiered pricing approach: regular price, moderate markdown, and final clearance. If rapid price undercutting risks confusing customers or harming the low-price reputation, incorporate a stability constraint in the optimization. That might slightly reduce theoretical profit but preserve brand equity.
Follow-up question 5
How do you mitigate interaction and cannibalization effects among products?
Explanation
Train multi-task or multi-output models when data volume allows. Include features for substitutable items in the input to see how discounting one product might reduce sales for similar products. Incorporate category-level constraints in the optimization so that price changes in one item do not unduly harm related items. Adjust final recommended prices in a post-processing step if the model’s raw suggestions show signs of unintended cannibalization.
Follow-up question 6
How would you adapt the algorithm to new products with limited historical data?
Explanation
Use hierarchical or transfer learning techniques. If a new item is similar to an existing product group (e.g., same brand or same category), initialize its price-demand parameters from that cluster. Refine as real sales data arrives. In the short term, rely on category-level averages for cost and elasticity. Over time, gather enough actual transaction data to update the model parameters more accurately.
Follow-up question 7
How would you address real-time competitor price undercutting?
Explanation
Ingest frequent competitor price feeds. Track current competitor prices for key items. If the model detects significant changes, recalculate recommended prices or apply rules to remain within a certain margin. For a large in-store retailer with physical price labels, it may not be cost-effective to react instantly. Instead, consider regular intervals for competitor-aware price updates (e.g., daily or weekly). Balance operational constraints with the need to remain competitive.
Follow-up question 8
What deployment strategy would you use to roll out this pricing system?
Explanation
Roll it out incrementally. Start with a pilot in a small subset of stores and product categories. Evaluate the key performance metrics (profit, revenue, brand sentiment, inventory turnover). Monitor for potential inventory stockouts or unexpected consumer responses. If performance is good, gradually expand coverage. Maintain a fallback logic that reverts to a simpler pricing approach if the advanced model yields anomalies or operational issues in any region.